

Chúng ta vừa kết thúc quý 1 và bước vào quý 2 năm 2020. Thực hiện nghiêm túc chỉ thị của chính phủ về phòng chống dịch bệnh do Virus Covid-19 gây ra, toàn thể nhân viên công ty bắt đầu làm việc trực tuyến tại nhà từ cuối tháng 3. Báo cáo nghiên cứu quý 1 năm 2020 đã diễn ra như thường lệ vào ngày 25 tháng 3 vừa qua nhưng với hình thức đặc biệt, đó là báo cáo trực tuyến.
Với niềm đam mê công nghệ, luôn dành thời gian để tìm tòi, nghiên cứu những kỹ thuật, công nghệ mới, trong buổi báo cáo nghiên cứu quý vừa qua, các kỹ sư của chúng tôi đã trình bày về các kỹ thuật đã nghiên cứu, học hỏi trong thời gian qua như sau:
1.REM Project: Được thực hiện bởi nhóm 4 kỹ sư: P.V.Đ. N.T.A, T.T.T, V.N.H.

Nội dung chính:
- Ứng dụng xây dựng hệ thống recommendations nội dung phù hợp.
- Đem đến trải nghiệm tuyệt vời cho khách hàng, người đọc.
- Ngoài ra còn đem lại lợi ích to lớn cho publisher.
Mục Tiêu/ Tính ứng dụng:
- Là 1 dịch vụ dành cho media (baomoi, tinhte, kênh14...)
- Dễ dàng nhúng vào bất cứ mọi websiteTạo ra recommendations widget tuyệt vời để có tỷ lệ CTR cao.
- Phân tích đặc điểm, mối quan tâm của người dùng, hot trend để nâng cao tỷ lệ CTR.
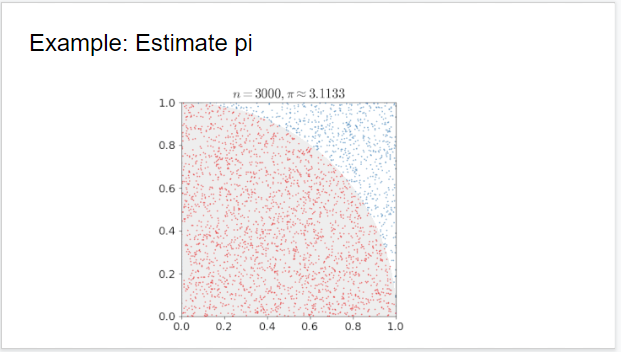
2.Monte Carlo Methods: Được trình bày bởi kỹ sư H.M.Đ.
Nội dung chính:
Reinforcement Learning: Tìm hiểu một số giải thuật, tìm hiểu lý thuyết và implement Monte-Carlo Method trong Reinforcement Learning.
Tính ứng dụng:
- Monte Carlo là phương pháp ngẫu nhiên để lấy mẫu (sampling) trong một tập hợp thống kê
- Là phương pháp xử lý những bài toán phân bổ nguồn lực phức tạp không thể giải một cách chính xác bằng giải tích toán học.
- Phương pháp Monte Carlo có một vị trí hết sức quan trọng trong vật lý tính toán và nhiều ngành khác, có ứng dụng bao trùm nhiều lĩnh vực khoa học, từ tính toán trong sắc động lực học lượng tử, mô phỏng hệ spin có tương tác mạnh, đến thiết kế vỏ bọc nhiệt hay hình dáng khí động lực học. Các phương pháp này đặc biệt hữu ích khi giải quyết các phương trình vi-tích phân.
3.Inference statistic: Do kỹ sư N.T.A trình bày.

Nội dung chính:
Tìm hiểu các khái niệm cơ bản trong inference statistic như hypothesis test, sử dụng các test thống kê giữa biến độc lập và phụ thuộc.
Tính ứng dụng:
Mỗi tập sample data sẽ cho ra 1 con số thống kê khác nhau, không thể trực tiếp sử dụng các số liệu trong sample để đại diện cho population. Inference statistics nhằm mục tiêu dự báo về population parameter thông qua sample parameter.
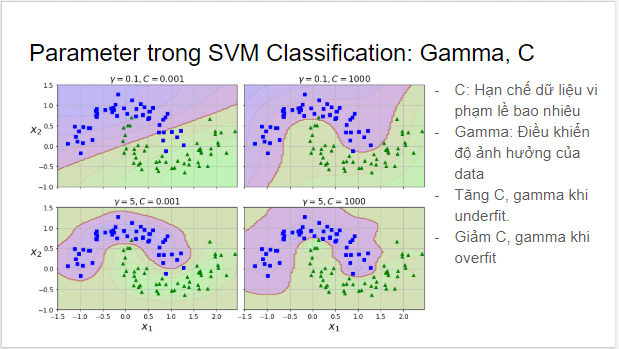
4. Tìm hiểu và luyện tập về Support Vector Machine(Viết tắt SVM): Do kỹ sư L.M.L trình bày.
Nội dung chính:
Tìm hiểu về kiến thức cơ bản liên quan đến SVM.
- Giới thiệu về SVM
- Classification (phân loại)
a) Cách hoạt động
b) Parameter trong Scikit Learn
c) Kernel Trick - giúp SVM sử dụng ít dữ liệu hơn
d) Demo: Iris Dataset và MNIST
- Regression (hồi quy)
a) Cách hoạt động
b) Parameter
c) Demo: Đoán giá nhà California
Tính ứng dụng:
- Support Vector Machine(SVM): là một model phổ biến trong Machine Learning.
- SVM là một thuật toán giám sát, nó có thể sử dụng cho cả việc phân loại hoặc đệ quy. Tuy nhiên nó được sử dụng chủ yếu cho việc phân loại.
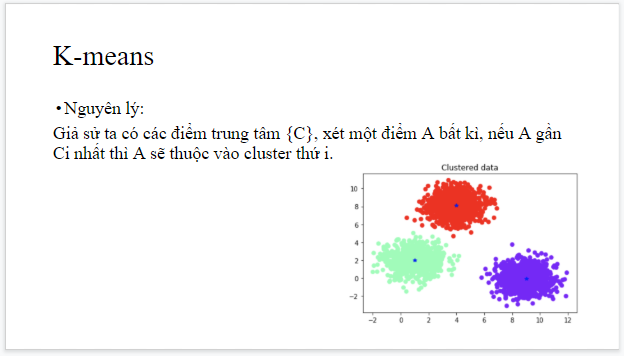
5. Cuối cùng là phần trình bày của kỹ sư P.V.H : Tìm hiểu về các kĩ thuật trong clustering.
Nội dung chính:
- Tìm hiểu về một vài kĩ thuật chính của clustering
- Demo
Tính ứng dụng:
- Là kĩ thuật để gán nhãn, phân loại data ví dụ: có thể sử dụng các thuật toán phân nhóm dữ liệu này để thể hiện trên biểu đồ thống kê, qua đó có thể đánh giá được nhóm độ tuổi sử dụng sản phẩm của khách hàng, và rồi lên chiến lược quảng cáo ...
- Về mặt chức năng giống với Classification, nhưng lại không có tập training sample xếp vào nhóm Unsupervised learning.
Tình hình bệnh dịch vẫn đang diễn ra hết sức căng thẳng, chúng ta có thể vẫn làm việc tốt khi ở nhà, thay vì buồn chán thì hãy suy nghĩ tích cực rằng đây cũng là cơ hội để chúng ta dành nhiều thời gian cho gia đình hơn, có nhiều thời gian yên tĩnh để nghiên cứu hơn... Chúc mọi người luôn có một sức khỏe thật tốt để chiến đấu với "Cô Vy". Ở nhà là yêu nước.






