

Tổng quan
Hôm nay tôi sẽ giới thiệu tới các bạn các phương pháp cấu hình trong Kubernetes để Terminate (chấm dứt) Pod một cách an toàn.
- Sử dụng
preStopđể đợi container của Pod bắt đầu chấm dứt đến khi không còn yêu cầu mới nào được định tuyến nữa. - Tắt máy có trật tự (Graceful shutdown) ở phía ứng dụng cho đến khi tất cả các yêu cầu hiện có được xử lý.
Graceful shutdown là một quá trình tắt máy ứng dụng một cách có trật tự, đảm bảo rằng tất cả các yêu cầu hiện tại được xử lý và tất cả các tài nguyên được giải phóng. - Kéo dài thời gian
terminationGracePeriodSecondscho đến khi hoàn thành 2 điều trên, tránh bị kill bởi SIGKILL.
Tiền đề
Điều gì được kích hoạt khi một Pod kết thúc?
Khi một Pod kết thúc, trước tiên nó sẽ đặt một deletionTimestamp trên tài nguyên Pod và chuyển sang trạng thái Terminating.
Sau đó, 3 quy trình sau được thực hiện độc lập (song song).
- Xử lý chấm dứt Pod
- Xóa điều hướng từ Service sang Pod
- Loại bỏ khỏi ReplicaSet hoặc Deployment
Vì chúng độc lập với nhau nên thứ tự không được đảm bảo và không thể đảm bảo việc "chờ một bước nào đó hoàn thành trước khi thực hiện bước tiếp theo".
PreStop là một hook trong Lifecircle của Kubernetes. Để tìm hiểu rõ hơn về hook này, bạn có thể tham khảo tại đây.
Trình tự sau khi Pod rơi vào trạng thái Terminating
- Xử lý chấm dứt Pod
- Xóa điều hướng từ Service đến Pod
Chúng ta sẽ vẽ sơ đồ trình tự và so sánh các trường hợp hoàn thành không có lỗi và các trường hợp không hoàn thành.
Cái sau ảnh hưởng đến khoảng thời gian các yêu cầu mới có thể được chấp nhận và không phụ thuộc vào cái trước, vì vậy cần phải luôn ghi nhớ hai điều này khi đặt tham số.
Trường hợp không có vấn đề
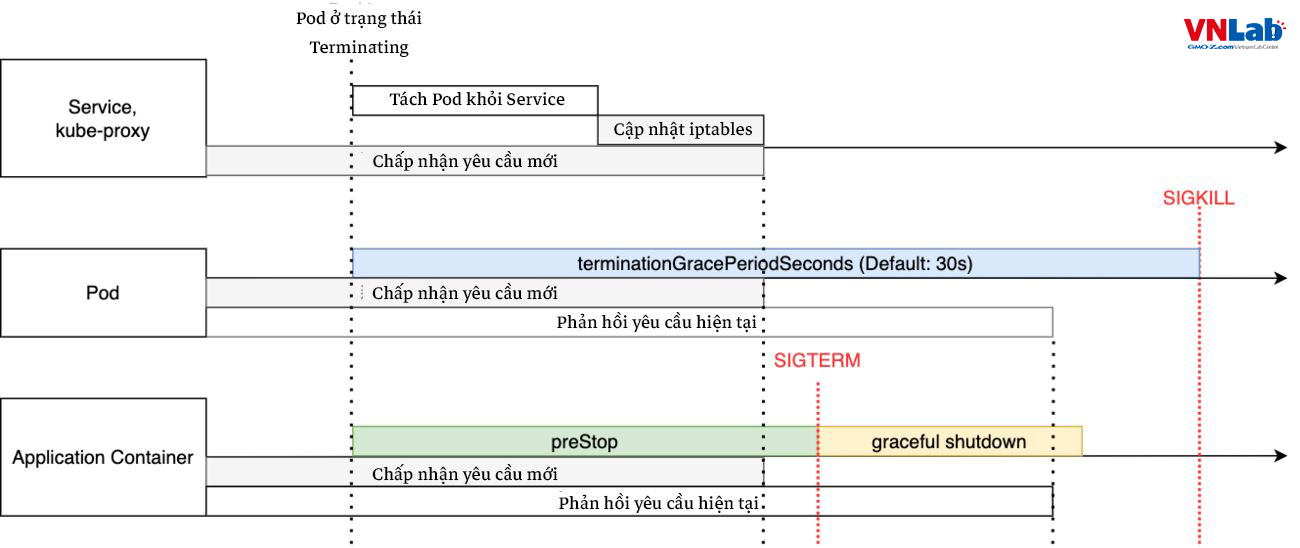
Trong trường hợp không có vấn đề gì
- Yêu cầu mới đang được chấp nhận mà không có lỗi cho đến khi kết thúc
- Xử lý tất cả các yêu cầu hiện có
Trường hợp preStop bị thiếu hoặc ngắn
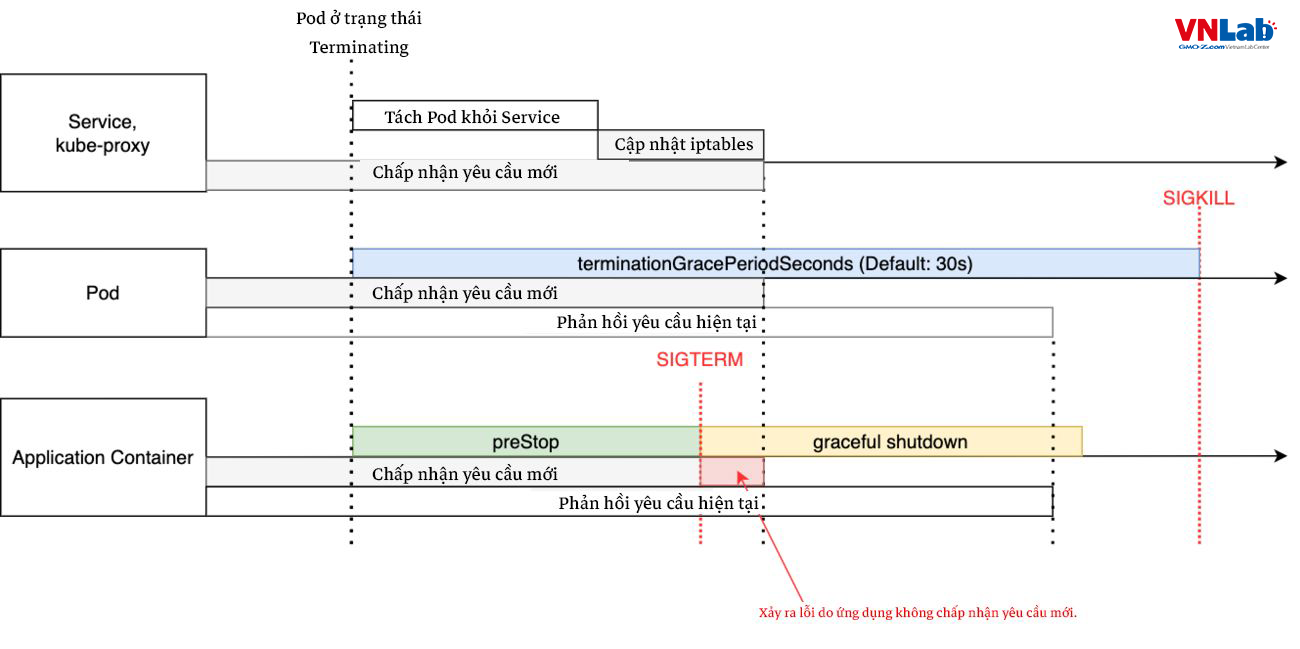
Nếu không có preStop, các yêu cầu mới sẽ không được chấp nhận giữa chừng và sẽ xảy ra lỗi như trong sơ đồ trên.
Vậy độ dài thích hợp của preStop là bao nhiêu? Cách duy nhất để khắc phục điều này là điều chỉnh cho đến khi lỗi không còn xảy ra nữa.
Điều này là do, như đã đề cập ở trên, việc tách Pod khỏi Service và cập nhật iptables được thực hiện song song với quá trình chấm dứt Pod và không thể xác định thời điểm hoàn thành của nó.
Ngoài ra, khi số lượng replica tăng lên đáng kể, lỗi bắt đầu xảy ra ngay cả khi chúng ta đã cài đặt một preStop dài mà chưa bao giờ gây ra lỗi.
Trường hợp Graceful Shutdown thiếu hoặc ngắn
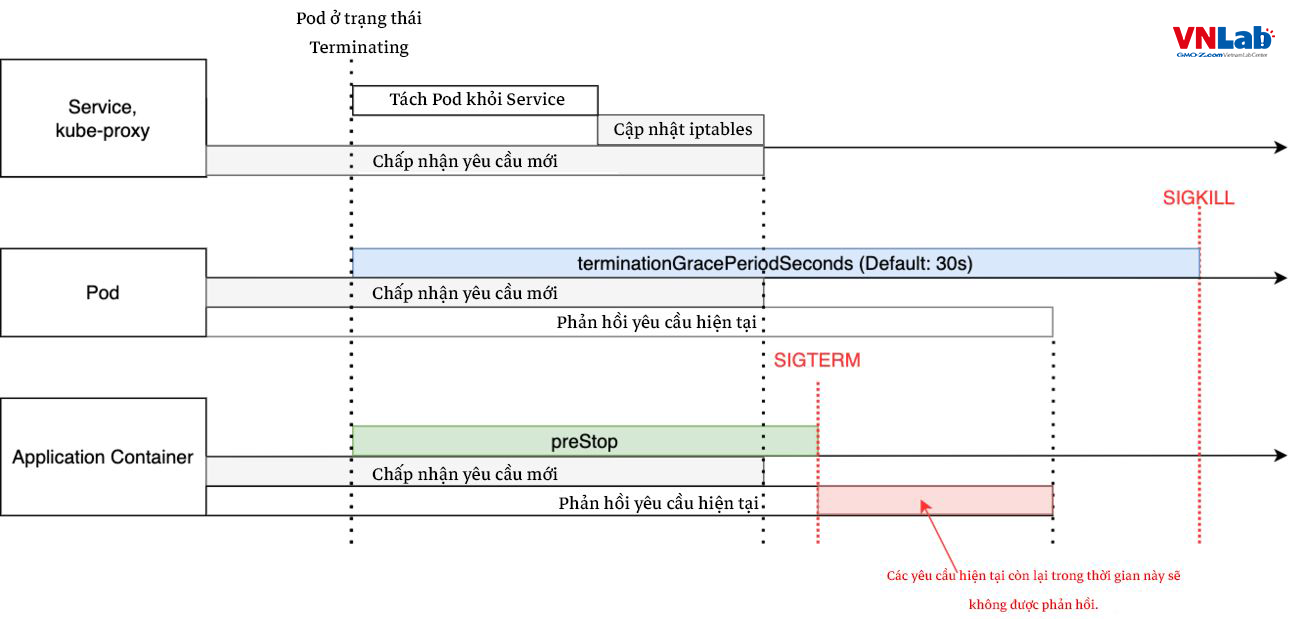
Nếu không có Graceful Shutdown, các yêu cầu hiện có sẽ kết thúc mà không được trả về máy khách, dẫn đến lỗi được trả về từ Load Balancing, ...
Trường hợp terminationGracePeriodSeconds ngắn
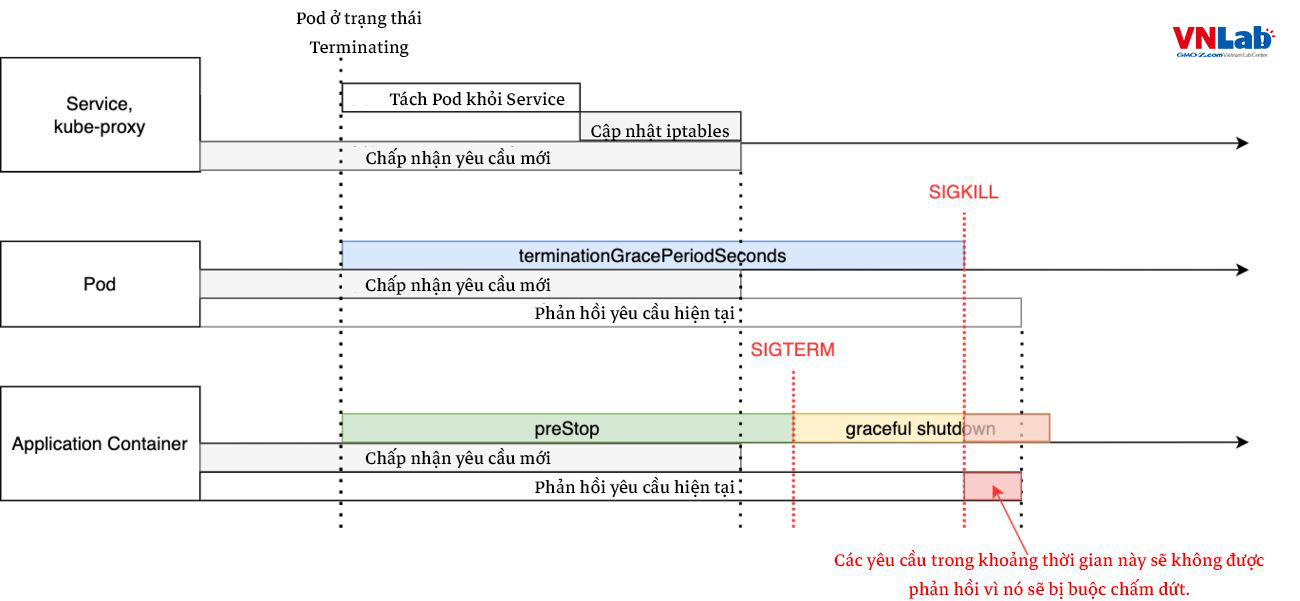
Nếu việc chấm terminationGracePeriodSeconds ngắn, một số yêu cầu hiện có sẽ không được return vì Graceful Shutdown sẽ bị buộc chấm dứt giữa chừng như đã đề cập trước đó.
Nên cho phép thời gian cần thiết là >= preStop + graceful shutdown.
Thực hiện
Tiếp theo, chúng ta sẽ đi vào các phương pháp cài đặt cụ thể.
Cài đặt preStop, terminationGracePeriodSeconds
preStop , terminationGracePeriodSeconds được đặt trong tài nguyên Pod.
Ví dụ với Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name:
spec:
selector:
matchLabels:
name: mypod
template:
metadata:
labels:
name: mypod
spec:
terminationGracePeriodSeconds: 30
containers:
- name: nginx
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10"]
image: nginx
env:
- name: ENV
value: production
...Nếu chạy trong distroless container thì không có shell nên cần phải copy /bin/sleep khi tạo image.
Graceful Shutdown
Sẽ tốt hơn nếu bạn thực hiện nó như thế này. Hãy tham khảo 2 bài viết dưới đây:
https://christina04.hatenablog.com/entry/go-graceful-shutdown
https://christina04.hatenablog.com/entry/go-shudown-hooks
Sleep trong ứng dụng thay vì preStop
Thay vì chèn chế độ sleep từ bên ngoài bằng preStop, tất nhiên cũng có thể triển khai chế độ sleep trực tiếp ở phía ứng dụng.
case <-ctx.Done():
logger.Info("Received TERM signal, attempting to gracefully shutdown servers.")
healthState.Shutdown(func() {
logger.Infof("Sleeping %v to allow K8s propagation of non-ready state", drainSleepDuration)
time.Sleep(drainSleepDuration)
// Calling server.Shutdown() allows pending requests to
// complete, while no new work is accepted.
logger.Info("Shutting down main server")
if err := mainServer.Shutdown(context.Background()); err != nil {
logger.Errorw("Failed to shutdown proxy server", zap.Error(err))
}
// Removing the main server from the shutdown logic as we've already shut it down.
delete(servers, "main")
})Ứng dụng thực tế
Mô tả
Trong quá trình làm dự án, tôi gặp phải một lỗi thuộc Trường hợp preStop bị thiếu hoặc ngắn ở bên trên. Mô tả cụ thể như sau:
- Trong quá trình deploy, sẽ xảy ra sự thay thế Pod (chứa php-fpm container), gồm quá trình Terminate Pod cũ và tạo Pod mới.
kubectl get pod my-pod
NAME READY STATUS RESTARTS AGE
my-pod 1/1 Terminating 0 5s- Trong cùng một thời điểm, phía client gửi request liên tục.
- Có một số ít request được K8s điều hướng đến Application Container (php-fpm). Tuy nhiên lúc này pod cũ đang trong trạng thái Terminating.
[31-Jul-2023 10:30:13] NOTICE: Terminating ...
[31-Jul-2023 10:30:13] NOTICE: exiting, bye-bye!- Do
preStopkhông được set nên request bị từ chối tiếp nhận bởi quá trìnhgraceful shutdowntrong php-fpm và client nhận được lỗi 502 từ Nginx trả về.
13.114.222.10 - - [20/Jul/2023:16:07:22 +0900] "POST /api/v1/connect/get HTTP/1.1" 502 150 "-" "-" "13.114.222.10" 0.299
Giải pháp
Sleep 5 giây ở preStop hook.
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","sleep 5"]Việc này giúp cho số ít request còn bị lọt vào Pod đang ở trạng thái Terminating vẫn sẽ được tiếp nhận trong 5 giây và được xử lý nốt ở bước Graceful Shutdown sau đó. Từ đó, khi deploy ứng dụng sẽ không xảy ra lỗi đối với một số request nữa vì chúng cuối cùng vẫn sẽ được xử lý và trả về kết quả.
Tóm tắt
Cách chấm dứt Pod một cách an toàn
- Sử dụng
preStopđể đợi cho đến khi vùng chứa ứng dụng của Pod bắt đầu chấm dứt cho đến khi không còn yêu cầu mới nào được điều hướng nữa. - Thực hiện graceful shutdown ở phía ứng dụng cho đến khi tất cả các yêu cầu hiện có được xử lý.
- Kéo dài thời gian
terminationGracePeriodSecondscho đến khi hoàn thành 2 bước trên để tránh bịSIGKILLkill.
Hãy thực hiện ba bước này.






