

À, hiểu rồi. Vậy là bạn đã biết về Linear Regression rồi nhỉ. Chắc là bạn đã khá vất vả với việc giải phương trình đạo hàm, nên muốn tìm một cách tiếp cận khác — dễ thở hơn — để tìm cực trị của hàm số.
Và bạn tới đây để tìm hiểu về Gradient Descent phải không? Bạn đã đến đúng chỗ rồi đấy.
Nhảy thẳng vào luôn à? Có vẻ bạn đang hơi vội — hoặc tự tin hơn mức cần thiết. Thông thường người ta chỉ đến đây sau khi đã làm quen với bài toán Linear Regression, và rồi tìm tới Gradient Descent để giải quyết việc tìm cực trị hàm số.
Dù sao, nếu bạn vẫn muốn ở lại, thì có lẽ bạn đã sẵn sàng bắt đầu từ nền tảng. Chúng ta vẫn tiếp tục được — nhưng bạn sẽ phải chú ý hơn từng bước. Gradient Descent mặc dù rất lợi hại nhưng nó yêu cầu một trình độ nhất định để hiểu và ứng dụng được nó.
Dù sao thì tôi cũng rất khuyến khích bạn đến đây, trước khi phải mất công cụ tìm kiếm các bài toán tối ưu chung và trong Machine Learning nói riêng. Thực tế có những bài toán rất khó — hoặc không thể tìm được thí nghiệm, yêu cầu phải giải tỉ mỉ từng dòng công thức một.
Thay vào đó, tại sao lại không thể tìm thấy trải nghiệm chậm hơn , một kết quả gần như tốt nhất mà có thể tiếp cận dễ dàng hơn? Đã có rất nhiều phương pháp để tìm kiếm độ sâu của một phương pháp như phương pháp của Newton , phương pháp cát tuyến tính tính , ... gradient Descent là một trong số những cách tiếp cận gần đây, đặc biệt chú ý đến việc tìm cực trị của hàm số, và phổ biến trong Machine Learning.

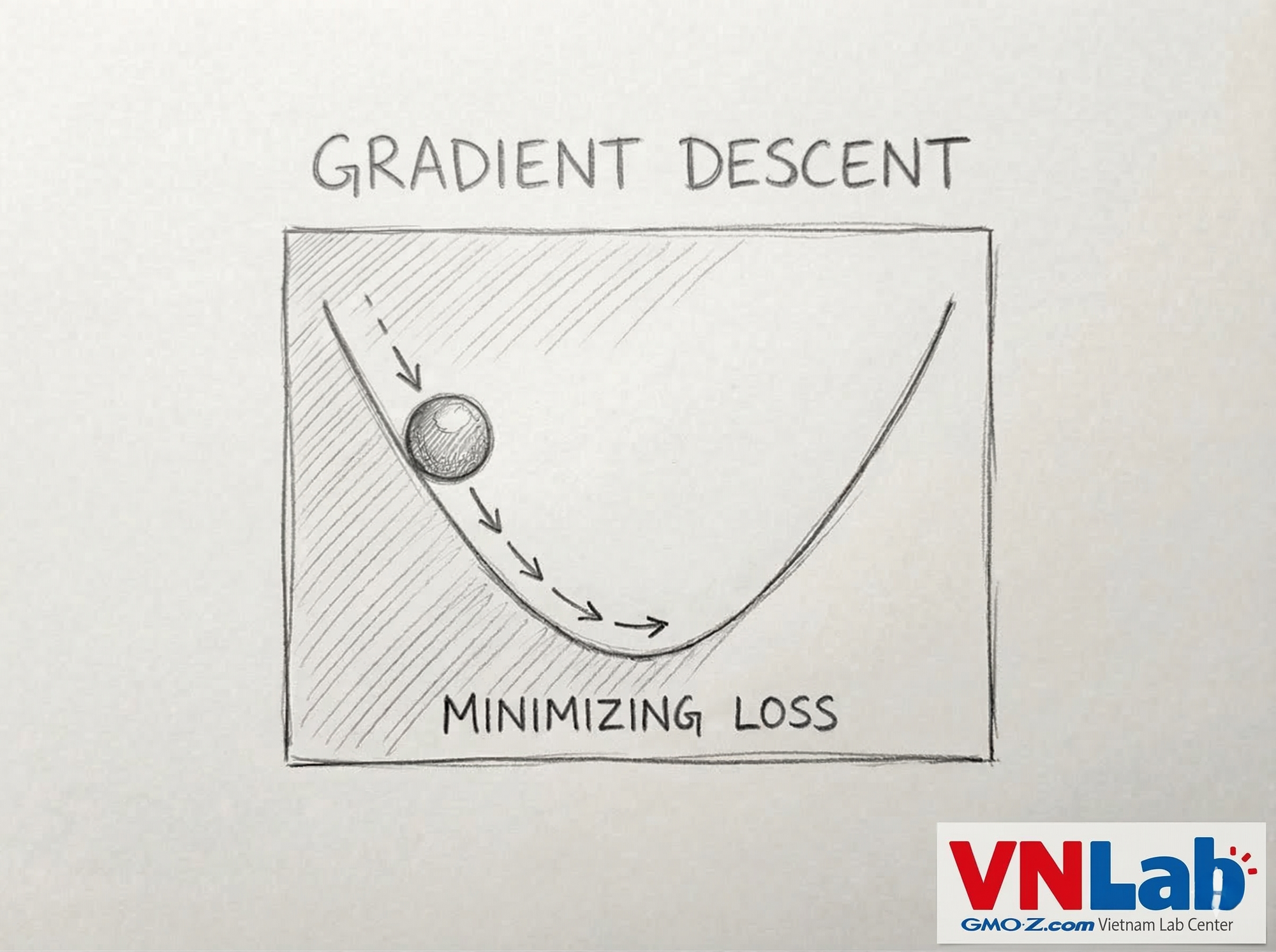
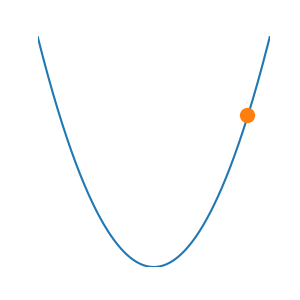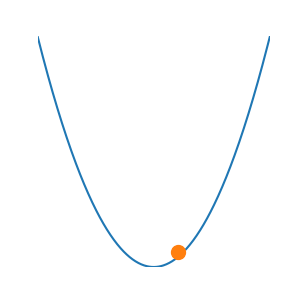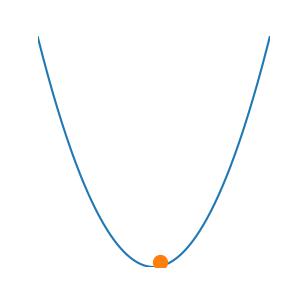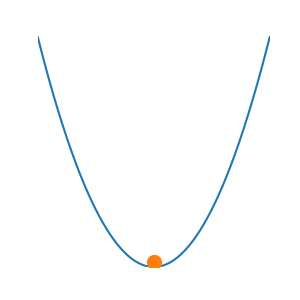
Ý tưởng của gradient Descent thật ra khá đơn giản. Hãy thử tưởng tượng bạn thả một quả bóng ở một vị trí nào đó ở trên đồi , quả bóng sẽ từ lăn xuống dốc và dừng lại tại thung lũng — vị trí thấp nhất của đồi. Đường cong của sườn dốc chính là hàm số bạn cần phải tối ưu, vị trí của bóng tối là giá trị hiện tại (điểm \(x\), hoặc \(w\) trong \(f(x)\), \(L(w)\)), và sau một khoảng thời gian, vị trí mới sẽ là điểm sau khi cập nhật chúng đi xuống dốc của hàm. Và tôi nghĩ bạn đã biết ...
Đúng rồi. Đó chính là giá trị đạo hàm của hàm số tại điểm đó.
Gần đúng, chính xác hơn là giá trị đạo hàm của hàm số tại điểm đó.
Hmm... có lẽ caffeine đã làm bạn mất tỉnh táo rồi. Đáp án hiển nhiên là đạo hàm của hàm số tại điểm đó — ngay cả những người mới học Toán cũng biết điều này.
Thật à? Bạn thật sự không biết Toán? Tôi đã gặp nhiều người tự tin thái quá, nhưng ít thấy ai dám thừa nhận như vậy.
Dù sao thì cũng được. Ghi nhớ điều này: đạo hàm = độ dốc. Đơn giản vậy thôi. Nếu bạn không hiểu điều này, tôi nghĩ phần tiếp theo sẽ như nghe như magic vậy.
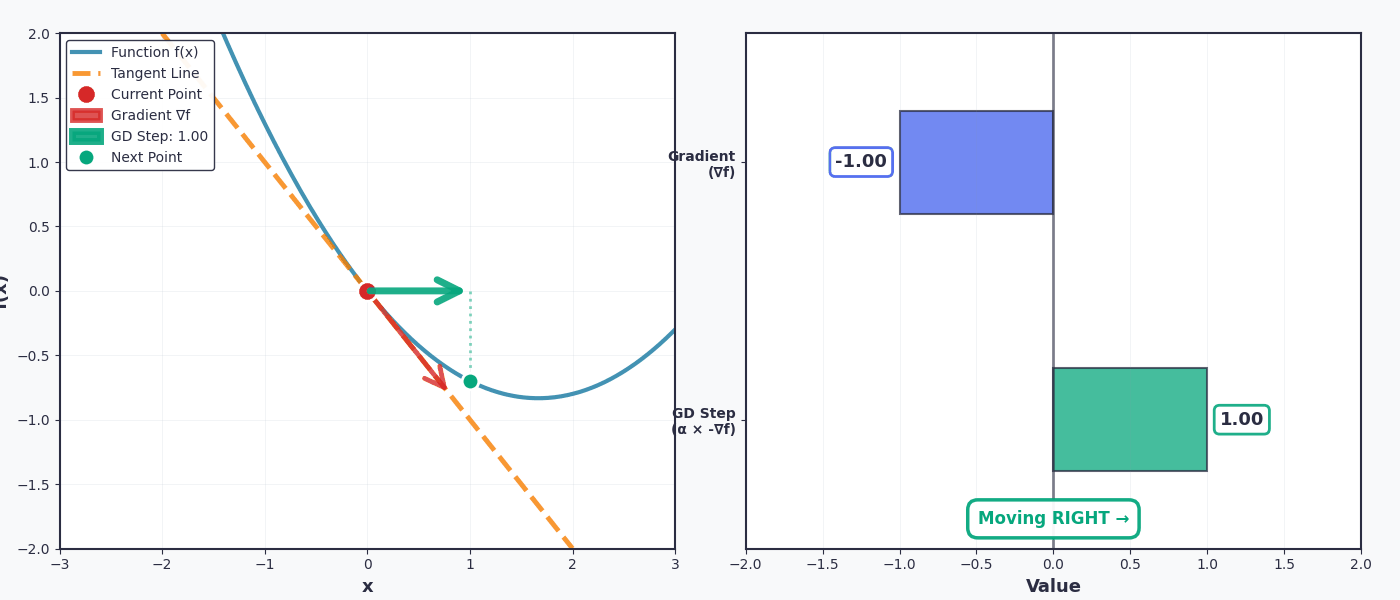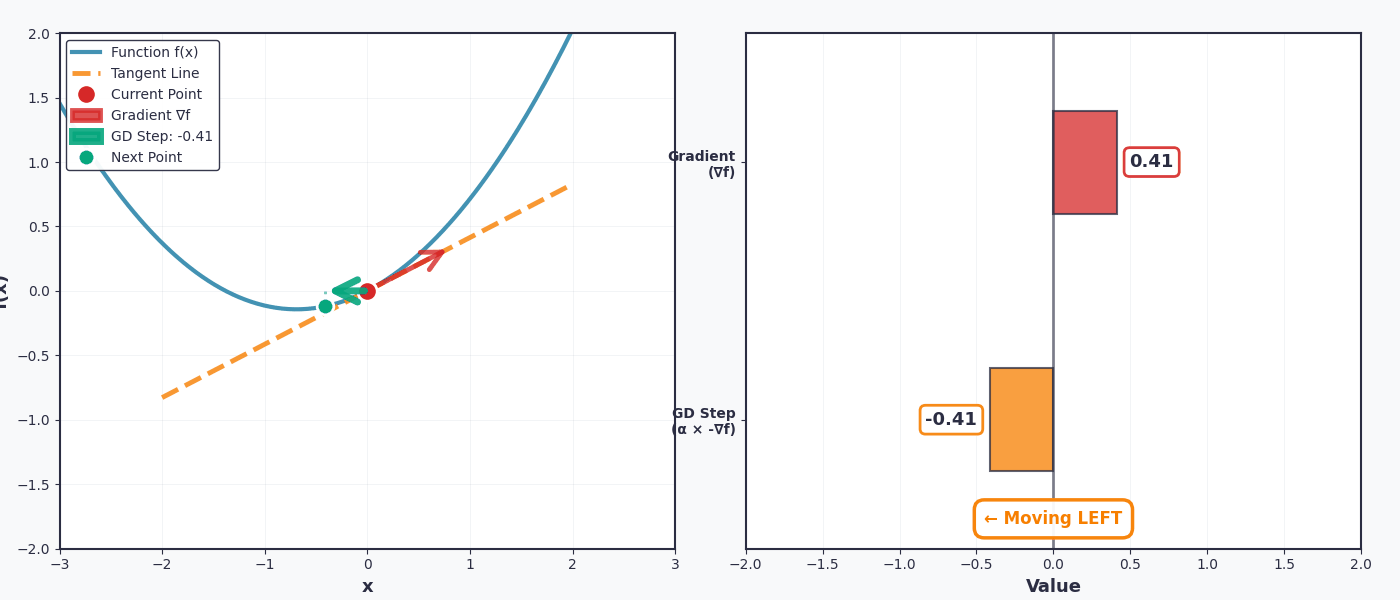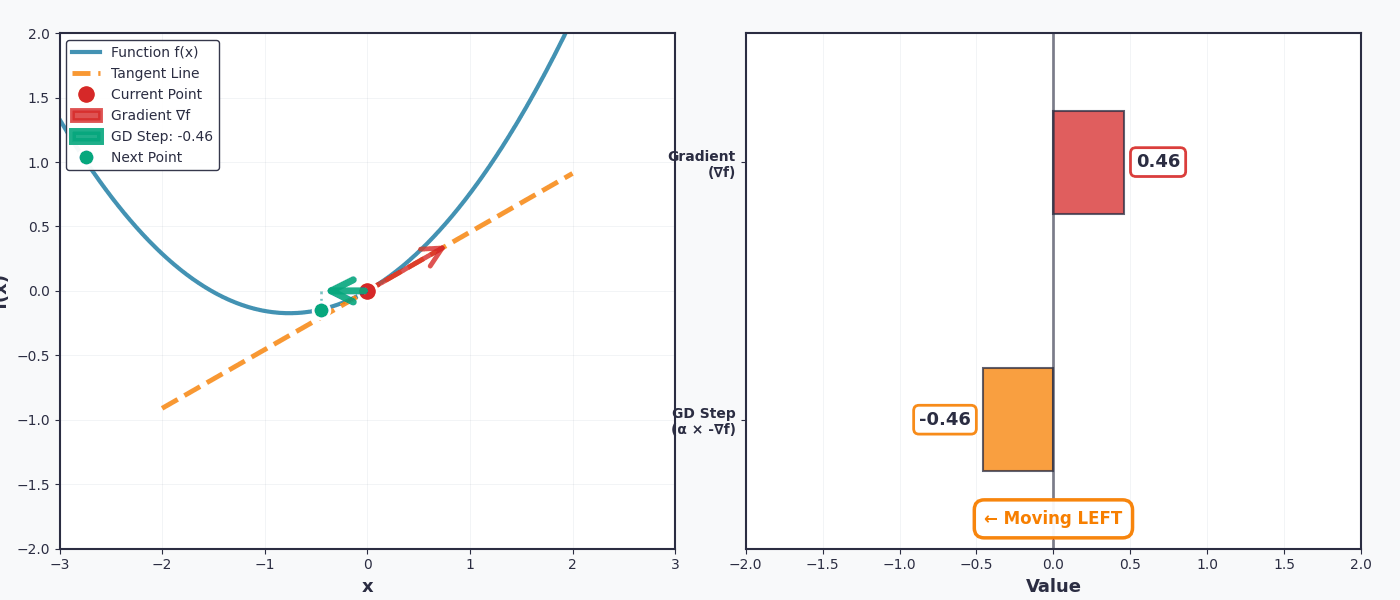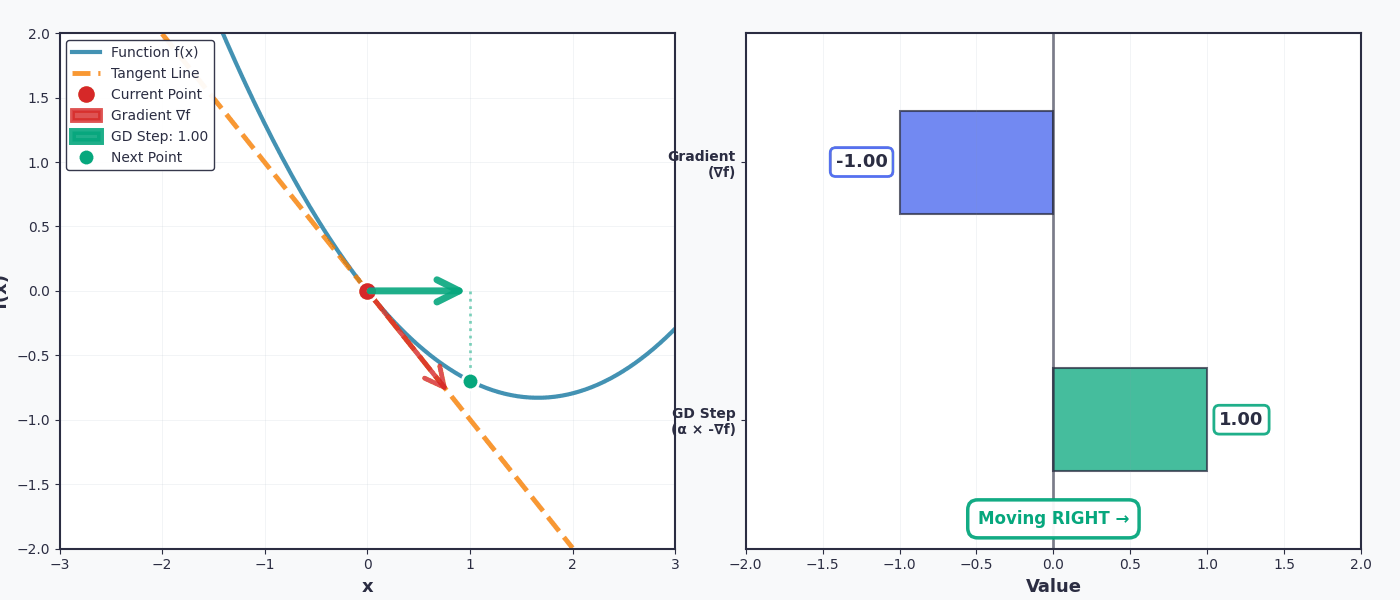
Khi tôi nói "đi xuống dốc" của hàm số, có nghĩa là chuyển ngược chiều với dấu của đạo hàm . Ví dụ cụ thể với không gian 2D:
- If đạo hàm dương (dốc lên) → chuyển sang trái (giảm x)
- Nếu đạo hàm âm (dốc xuống) → chuyển sang phải (tăng x)
Rất vui, tham số sẽ được cập nhật tăng dần để tiến gần đến điểm cực tiểu mà chúng ta đang tìm kiếm.
Hoạt động dựa trên học tập dựa trên cơ sở chiến thuật này. Cụ thể là...

Đầu tiên, bạn thả bóng xuống — chọn một vị trí bất kỳ trên sườn đồi, gọi nó là \(x_0\). Quả bóng sẽ bắt đầu cuộn lên trên hàm số \(f(x)\), và nhiệm vụ của ta là dẫn nó đi theo hướng \(- f'(x)\), ngược lại theo độ dốc.
Tất nhiên, ta không muốn để bóng lăn quá nhanh và vượt qua thung lũng. Vì thế, ta cần kiểm soát tốc độ từng bước bằng một tham số gọi là learning rate (\(lr\)). Vị trí tiếp theo của bóng, \(x_1\), được tính theo công thức:
\(x_0=ngẫu()\)
\(x_{t}:=x_{t-1} - lr * f'(x_{t-1})\)
Tại \(x_1\) này, quả bóng đã tiến gần hơn đến đáy thung lũng — điểm cực tiểu mà ta đang tìm. Và nếu ta cứ tiếp tục như vậy — tìm \(x_2\), rồi \(x_3\), \(x_4\)... cho đến \(x_t\) — cuối cùng ta sẽ có trải nghiệm tăng dần dần đủ tốt cho bài toán.
Đơn giản thôi. Không cần giải quyết phương pháp phức tạp, chỉ cần tạo bóng để tìm đường xuống.
Nhưng hãy cẩn thận — nếu thiếu thận trọng và chọn \(lr\) quá lớn, một thảm họa sẽ xảy ra. Họ gọi đó là Overshooting. Quả bóng sẽ không lăn xuống nữa, mà nhảy vọt qua thung lũng, nảy lên phía bên kia, rồi lại nảy ngược lại... mãi mãi không bao giờ đến được điểm cực tiểu.
Tưởng tượng một đứa trẻ chơi đu — nếu đẩy quá mạnh, nó sẽ bay vòng qua cả thanh ngang. Learning rate cũng vậy: quá nhỏ thì chậm chạp, quá lớn thì mất kiểm soát.
Vì thế, việc chọn \(lr\) phù hợp chính là nghệ thuật của Gradient Descent.
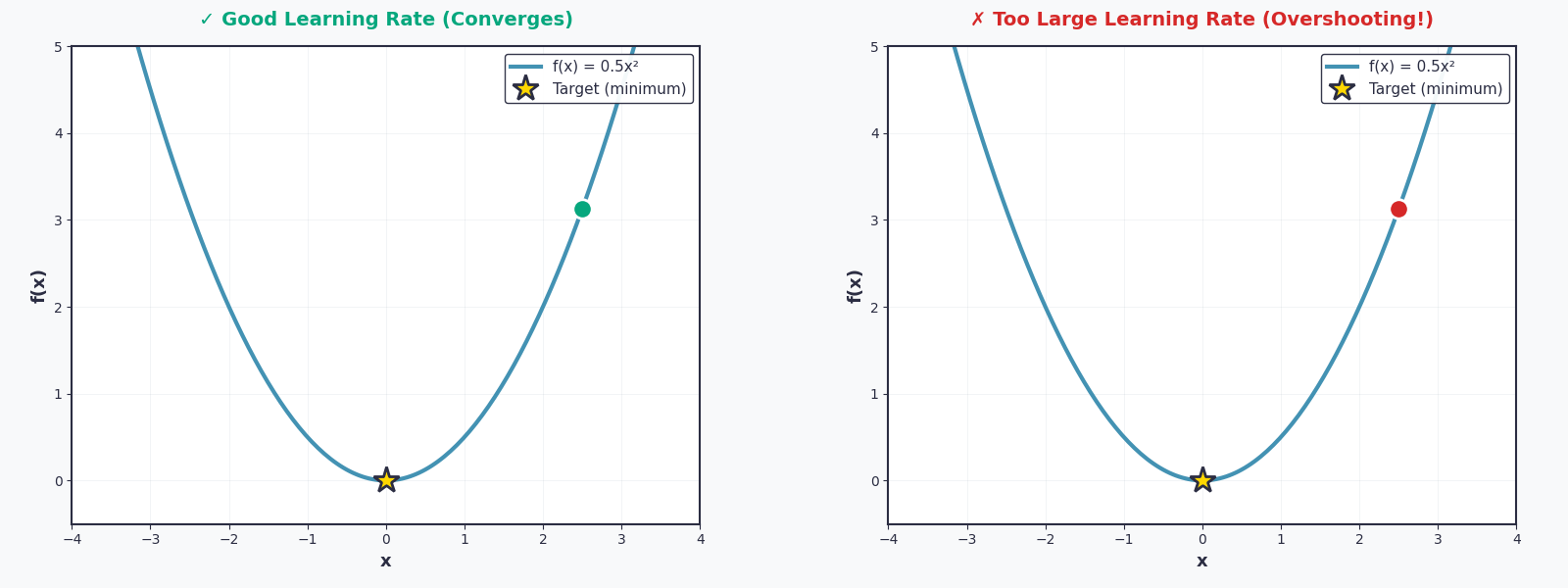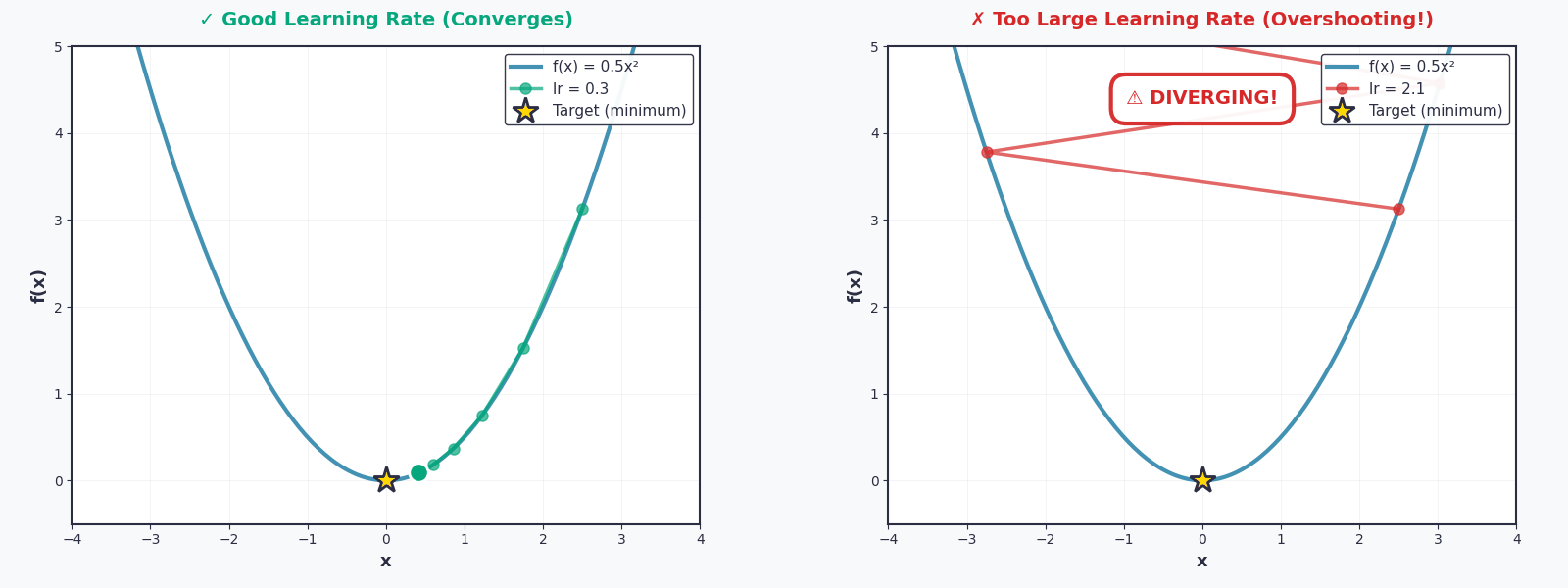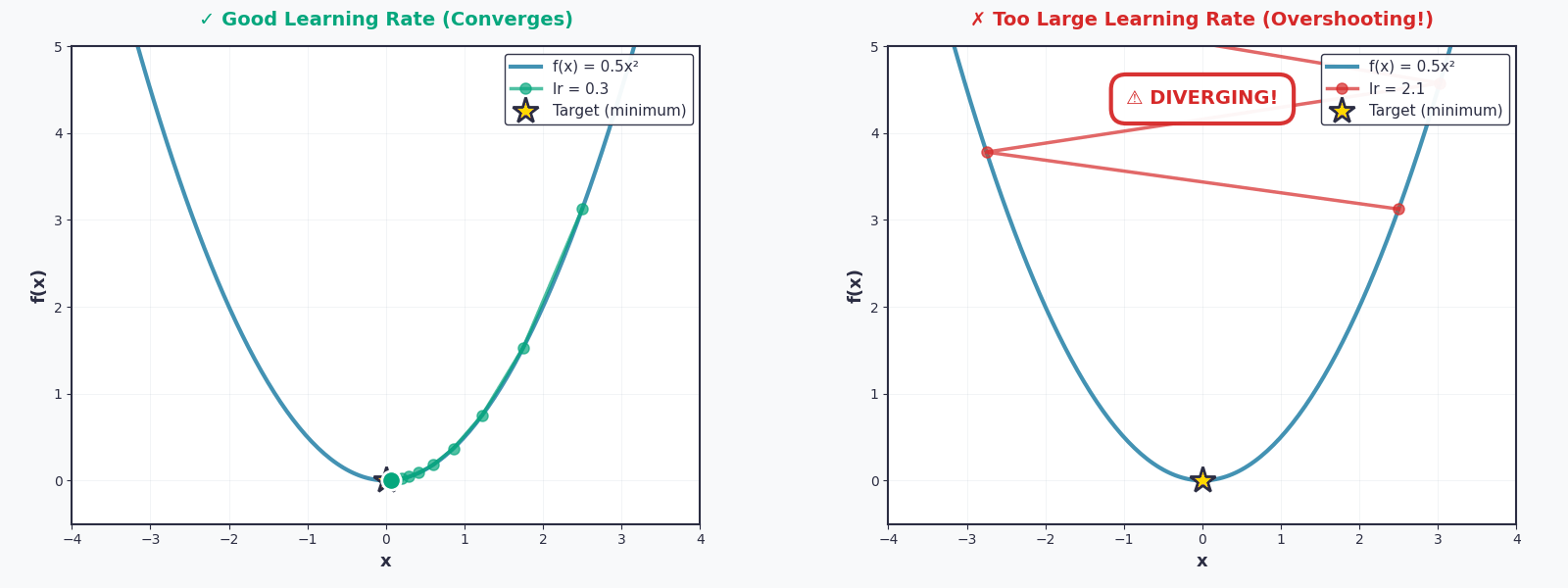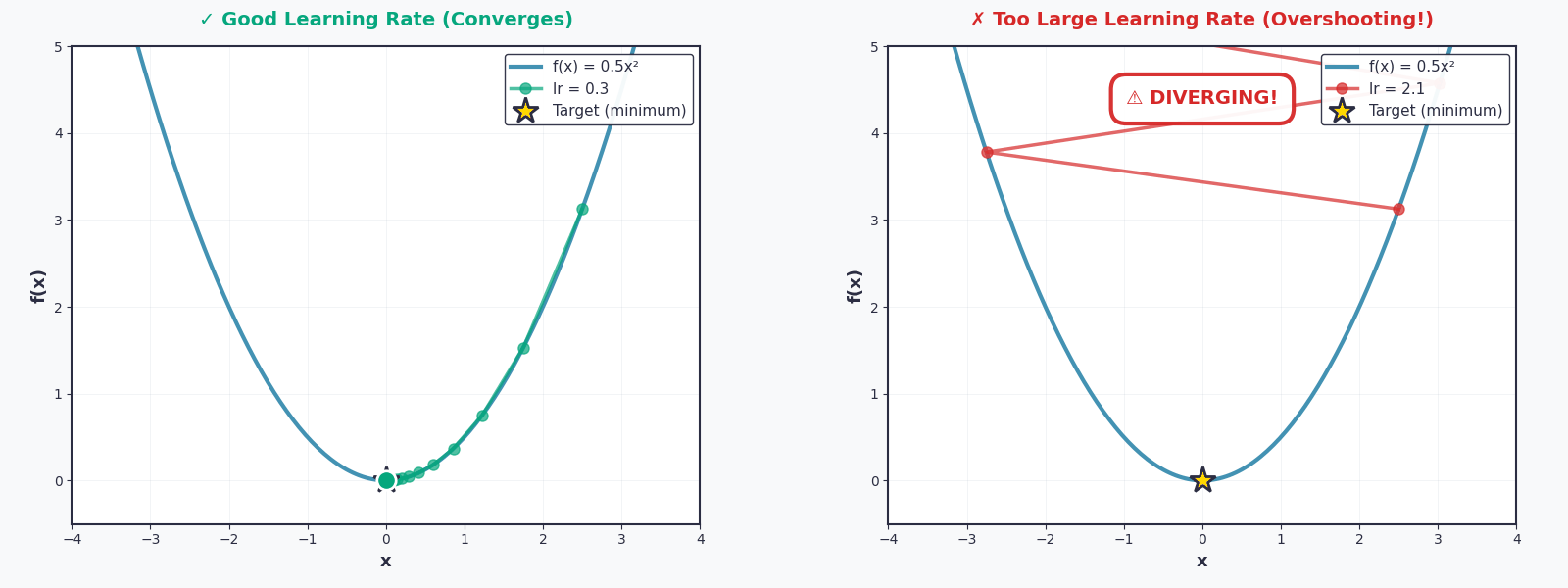
Bây giờ thì — quay lại với vấn đề của bạn, lí do mà bạn tìm đến đây — Linear Regression. Nhiệm vụ của chúng ta là tìm \(w\) để tối ưu hóa hàm \(L(w)\)
\(L(w)=\frac{1}{2n}\left\|X^Tw-y\right\|_2^2\)
Tôi nghĩ bạn đã biết rằng đạo hàm của \(L(w)\) là gì, nếu bạn chưa biết thì có thể tìm nó ở bài blog trước đó — Linear Regression.
\(\frac{\partial L}{\partial w}=\frac{1}{n}X(X^Tw-y)=\frac{1}{n}(XX^Tw-Xy)\)
Áp dụng Gradient Descent, công thức cập nhật \(w\) để tối ưu hàm \(L(w)\) là:
\(w_{t}:=w_{t-1}-lr*\frac{1}{n}X(X^Tw_{t-1}-y)\)
Và thế là xong, bài toán Linear Regression đã được giải quyết mà không cần phải giải phương trình phức tạp làm gì cả. Dễ phải không? Tới đây tôi nghĩ bạn đã có thể tự mình áp dụng thuật toán này rồi.
Bây giờ đã tới lúc tôi phải đi... tham quan ở trong Nightreign nên có lẽ đã tới lúc chào tạm biệt, Gradient Descent còn khá nhiều thứ thú vị, nhưng có lẽ để khi khác vậy.
Vậy nhé, chào tạm biệt!
Giỏi Toán? Hmm... Tôi không nghĩ vậy. Nếu bạn thật sự hiểu, bạn sẽ không cần phải 'intimidate' để che giấu sự thiếu tự tin của mình. Bạn hoàn toàn có thể tiếp tục tự mình nghiên cứu nếu bạn thực sự tự tin đến vậy. Còn bây giờ tôi sẽ phải đi đây, tạm biệt!
Tip: Require 10 Math to unlock
Vậy nhé, tôi nghĩ với khả năng của bạn, thì như vậy là đủ rồi. Tôi đi với anh em trong Nightreign đây.
Tip: Try Persuade/Intimidate
Cũng đúng nhỉ? Thôi được rồi, đây là hộp mô phỏng mà tôi đang làm dở, và một đoạn code mẫu ví dụ mà tôi dùng vào 3 năm trước. Vì môi trường mô phỏng có giới hạn nên tôi chỉ có thể xây dựng cho bài toán Linear Regression 2D, và có hơi xấu một chút... Tôi hi vọng là nó đủ để bạn hiểu.
Đoạn code có một chút dài do phần visualization... (và cũng quá lâu rồi nên tôi cũng lười sửa)
import numpy as np
import matplotlib.pyplot as plt
# Generate data
N = 300
X = (np.arange(N) - N / 2) / N
X = np.vstack((X, np.ones(N)))
gW = np.array([[2], [3]]) # ground-truth weights
Y = X.T @ gW + (np.random.rand(N, 1) - 0.5) * 0.4
# Initialize random weights
w = np.random.rand(2, 1)
# Gradient Descent
lr = 1e-1
losses = []
weights_history = [w.copy()]
for e in range(1000):
# Calculate loss
loss = np.mean((X.T @ w - Y)**2)
losses.append(loss)
# Calculate gradient
grad = 1/N * X @ (X.T @ w - Y)
# Update weights
w = w - lr * grad
weights_history.append(w.copy())
print(f"Epoch {e + 1} - Loss: {loss}")
# Plotting
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 5))
fig.patch.set_facecolor('white')
# Left plot: Data points and fitted line
ax1.scatter(X[0, :], Y, alpha=0.5, s=20, c='#2E86AB', label='Data points')
# Plot initial random line
w_init = weights_history[0]
y_init = X.T @ w_init
ax1.plot(X[0, :], y_init, '--', color='#FF6B6B', linewidth=2,
label=f'Initial (random)', alpha=0.7)
# Plot final fitted line
y_pred = X.T @ w
ax1.plot(X[0, :], y_pred, '-', color='#06A77D', linewidth=3,
label=f'Final fit (iter=1000)')
# Plot ground truth line
y_true = X.T @ gW
ax1.plot(X[0, :], y_true, ':', color='#F77F00', linewidth=2.5,
label='Ground truth', alpha=0.8)
ax1.set_xlabel('x', fontsize=12, fontweight='bold')
ax1.set_ylabel('y', fontsize=12, fontweight='bold')
ax1.set_title('Linear Regression with Gradient Descent',
fontsize=14, fontweight='bold', pad=15)
ax1.legend(loc='upper left', fontsize=10)
ax1.grid(True, alpha=0.3)
# Right plot: Loss over iterations
ax2.plot(losses, color='#D62828', linewidth=2.5)
ax2.set_xlabel('Iteration', fontsize=12, fontweight='bold')
ax2.set_ylabel('Loss (MSE)', fontsize=12, fontweight='bold')
ax2.set_title('Loss Convergence', fontsize=14, fontweight='bold', pad=15)
ax2.grid(True, alpha=0.3)
ax2.set_yscale('log') # Log scale to see convergence better
# Add text annotations
final_loss = losses[-1]
ax2.text(len(losses)*0.7, losses[0]*0.5,
f'Final Loss: {final_loss:.6f}',
fontsize=11, bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
plt.tight_layout()
plt.show()
# Print results
print(f"Ground truth weights: w0={gW[0,0]:.4f}, w1={gW[1,0]:.4f}")
print(f"Learned weights: w0={w[0,0]:.4f}, w1={w[1,0]:.4f}")
print(f"Final loss: {final_loss:.6f}")
print(f"Initial loss: {losses[0]:.6f}")
print(f"Loss reduction: {(1 - final_loss/losses[0])*100:.2f}%")
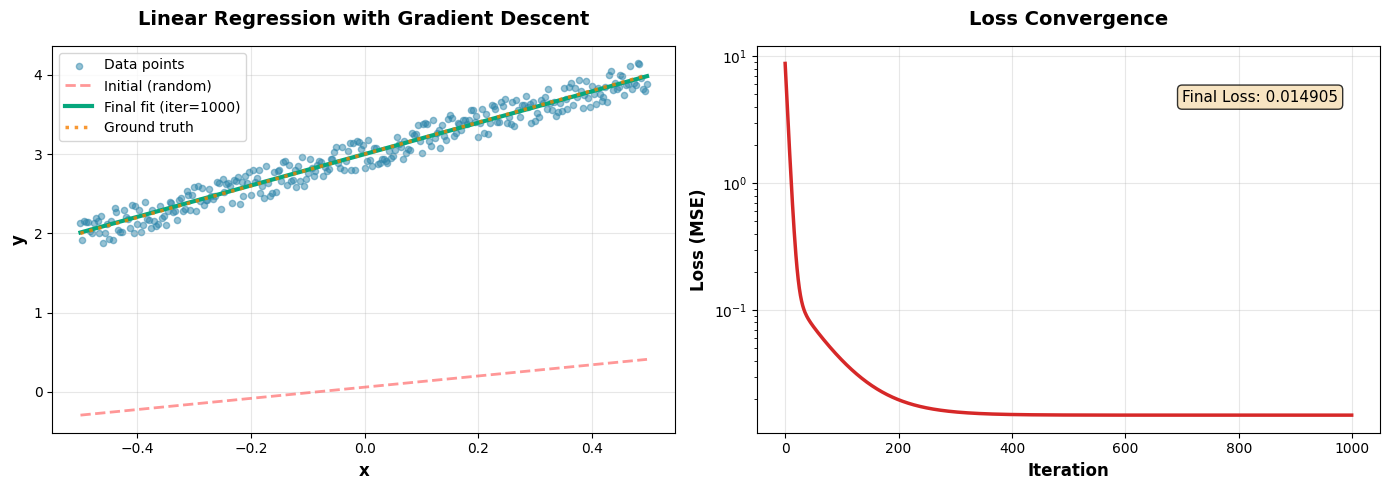
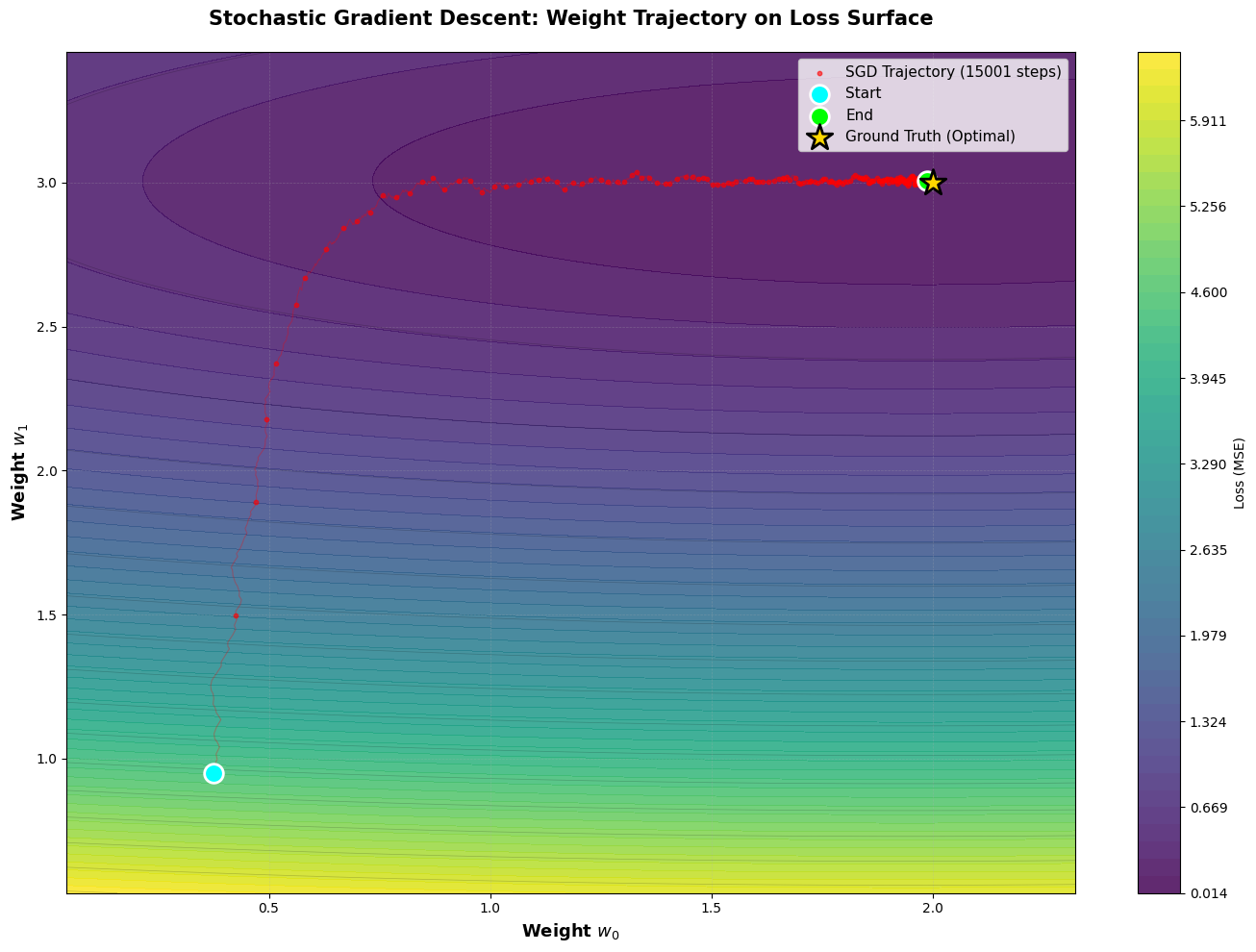
Đó là những gì tôi có, hi vọng sẽ giúp bạn dễ hình dung về Gradient Descent hơn. Bây giờ thì... trước khi tôi gia nhập hội đi chơi Nightreign thì bạn còn có câu hỏi nào không? Nếu có câu hỏi gì thì hay giữ cho chính mình đi, tôi không còn thời gian nữa. Thay vào đó... hãy lấy giúp tôi cái chìa khóa trên kia giúp tôi được không?



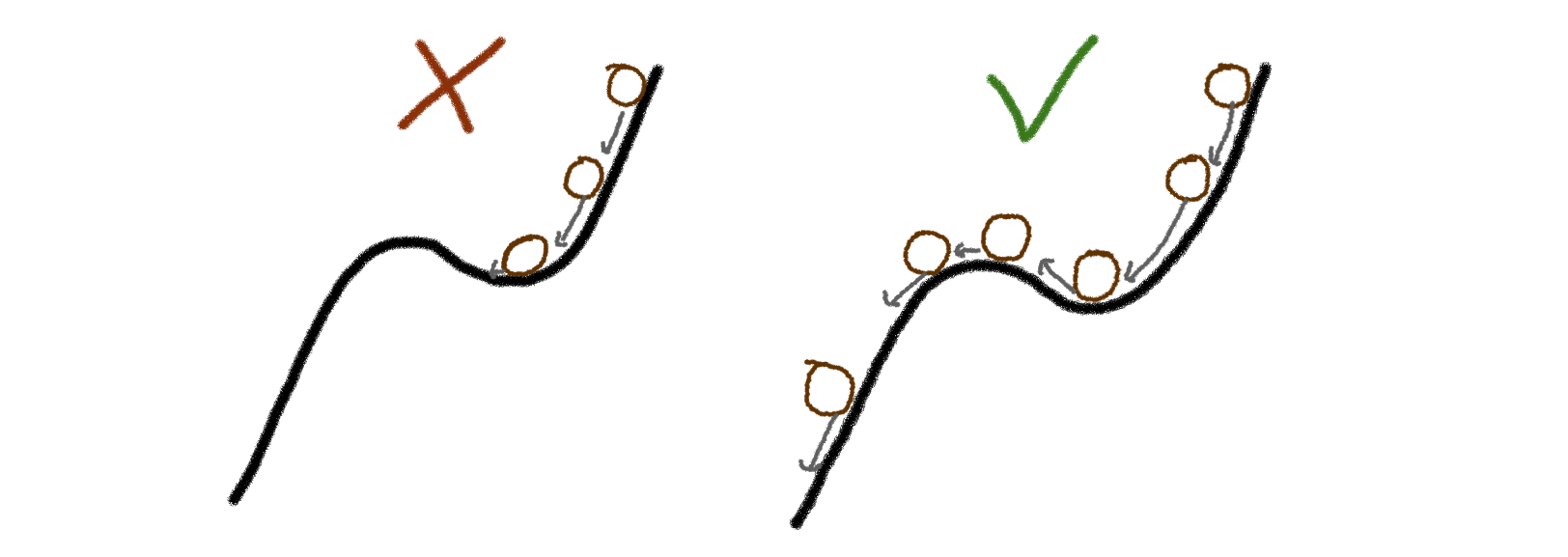

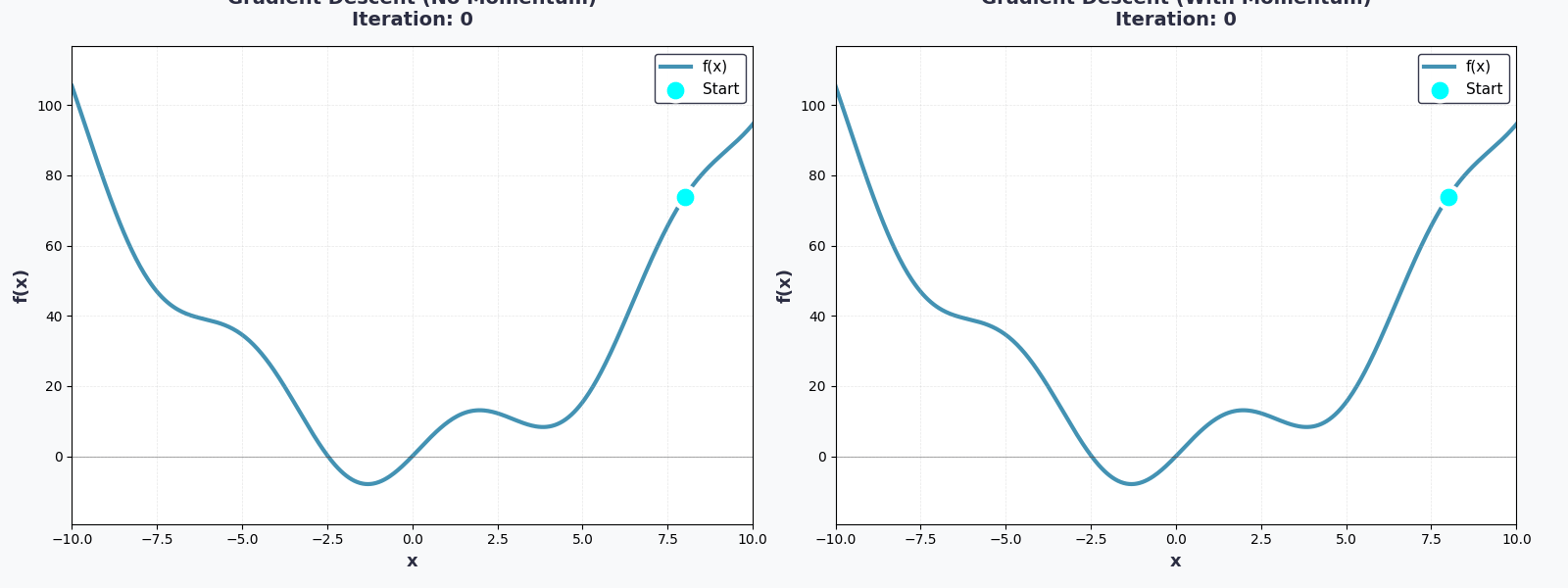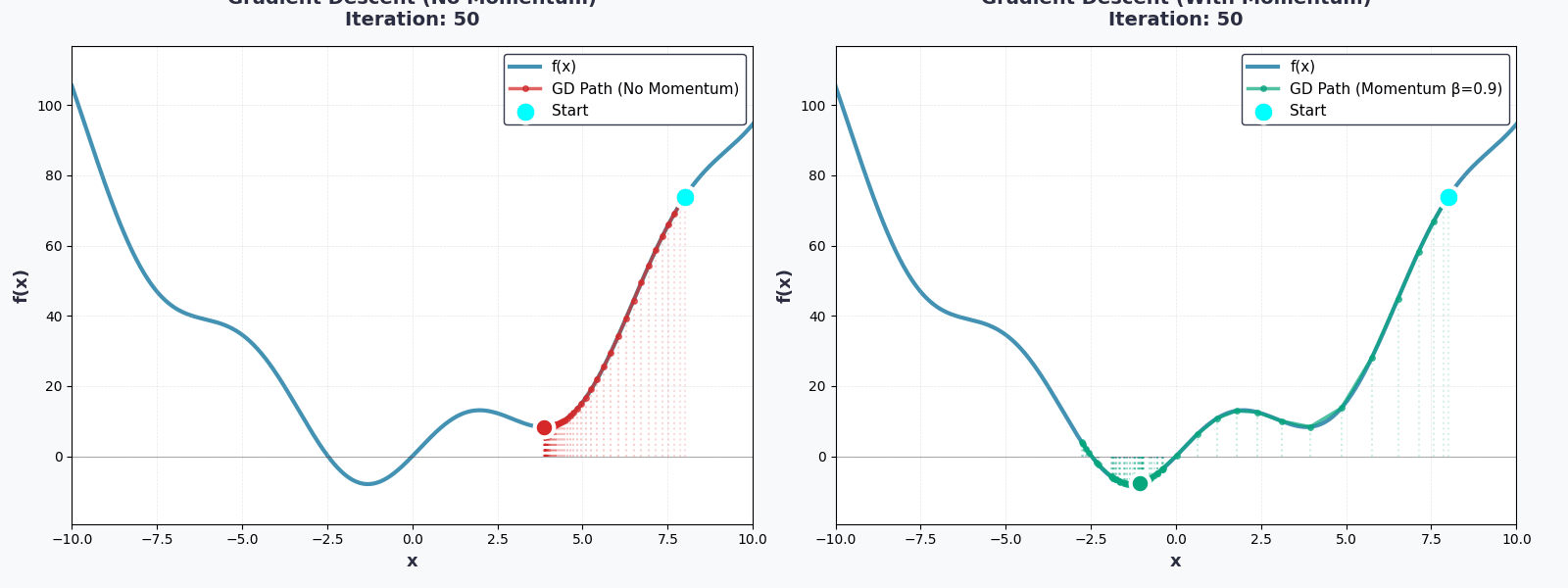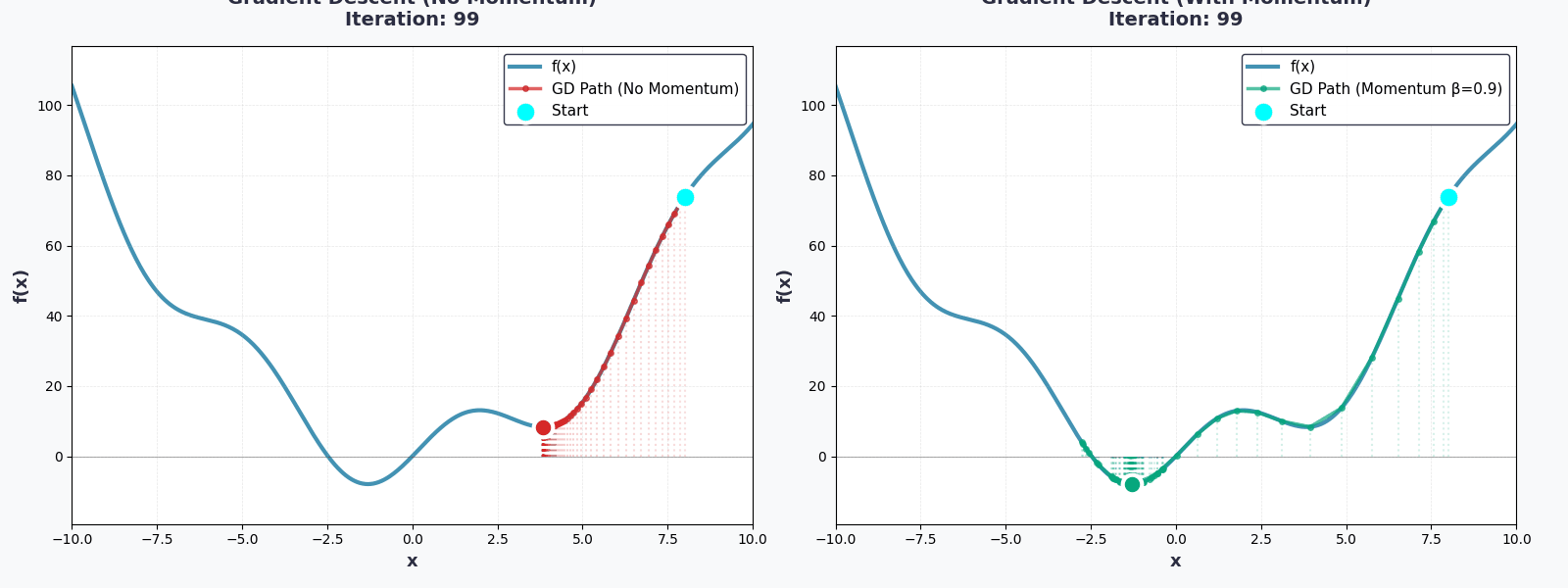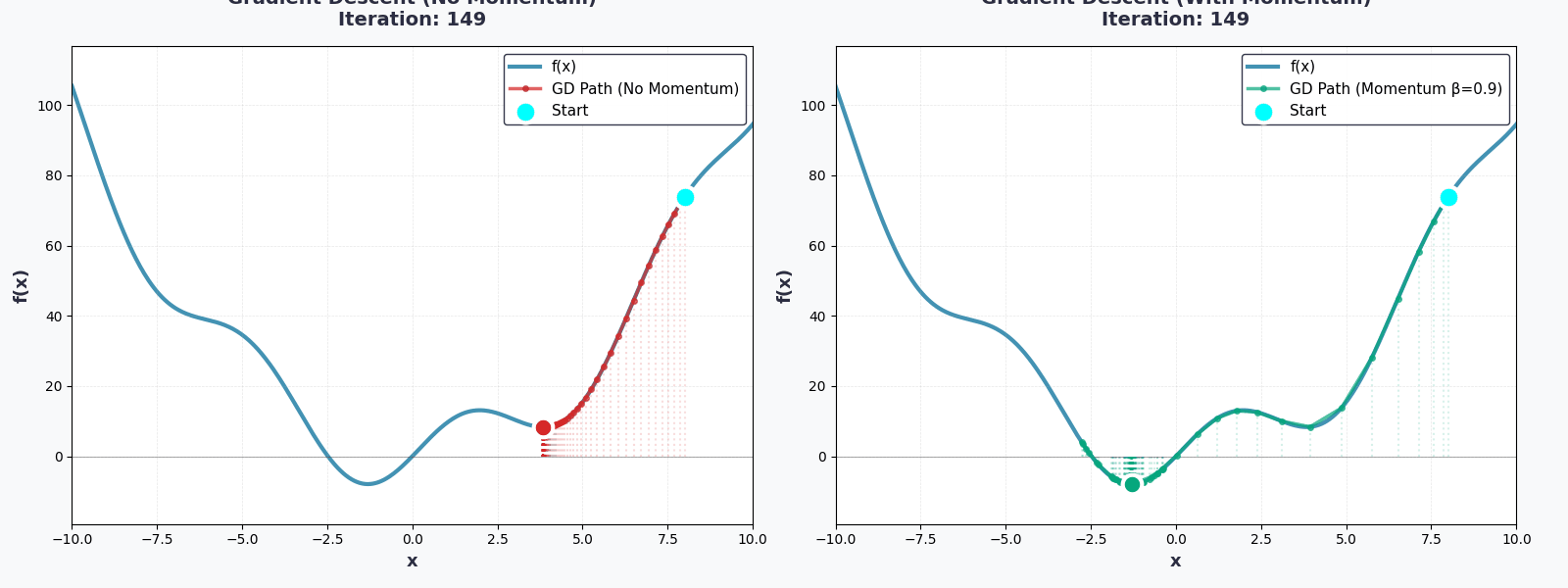
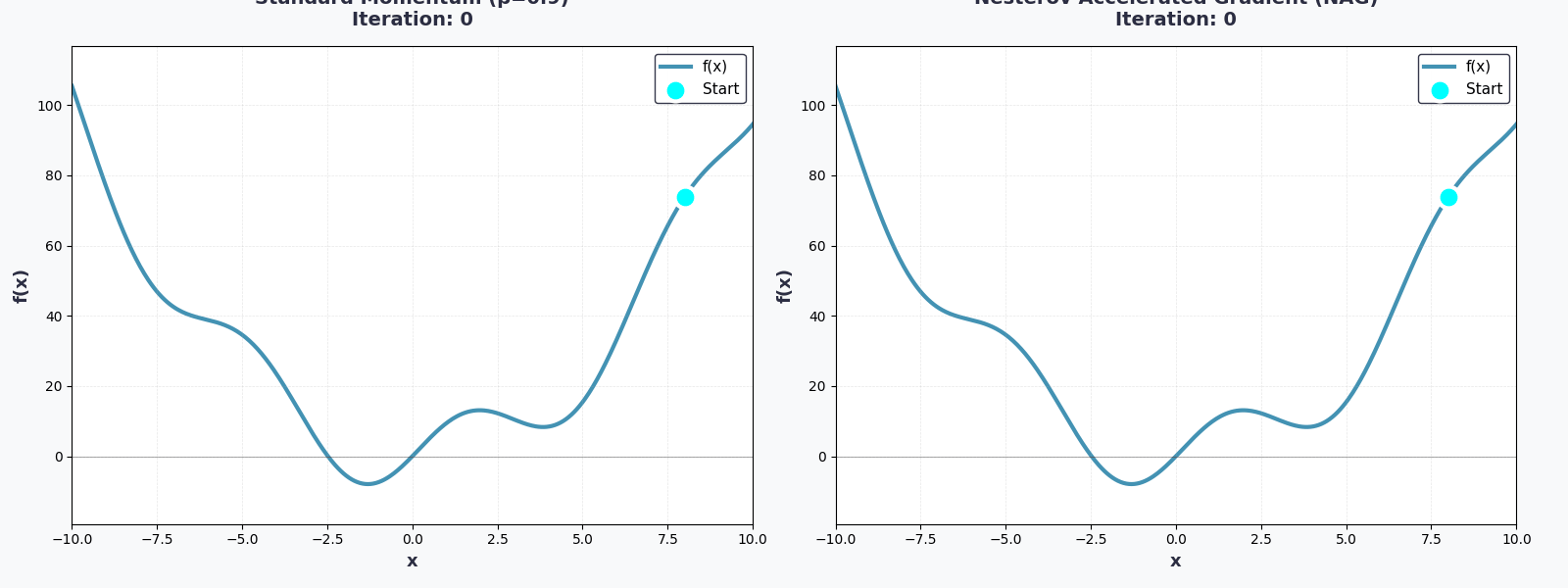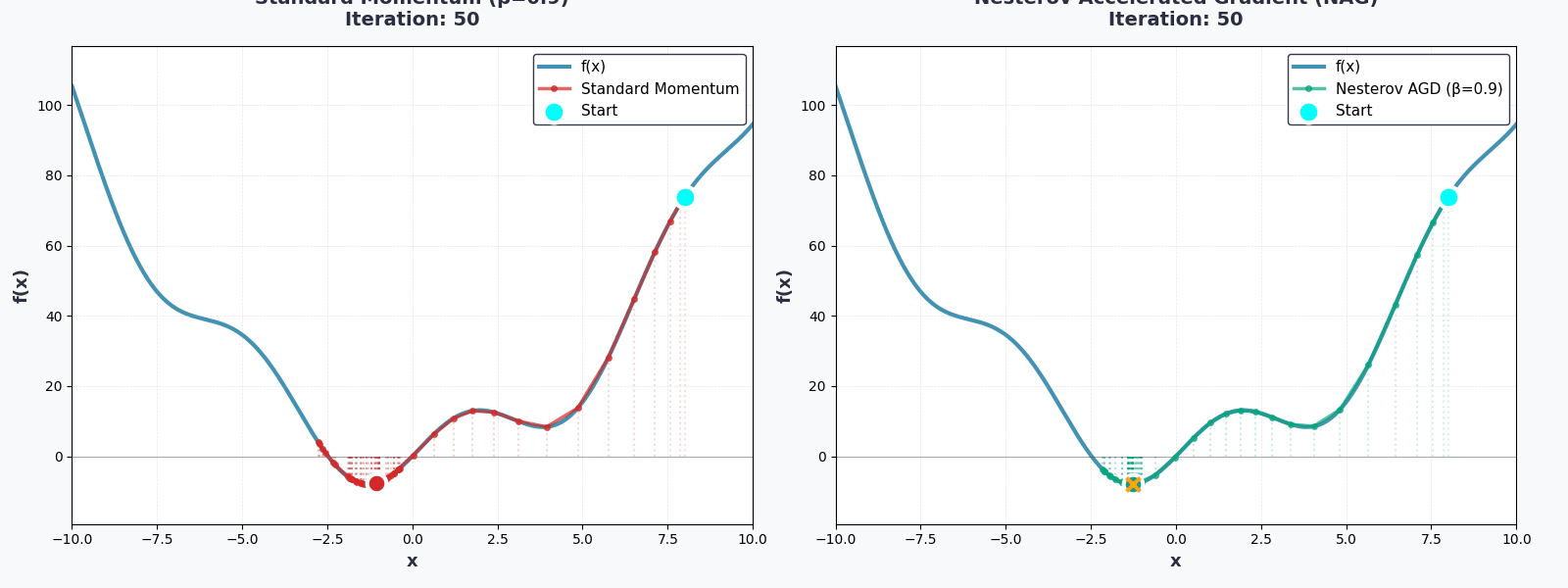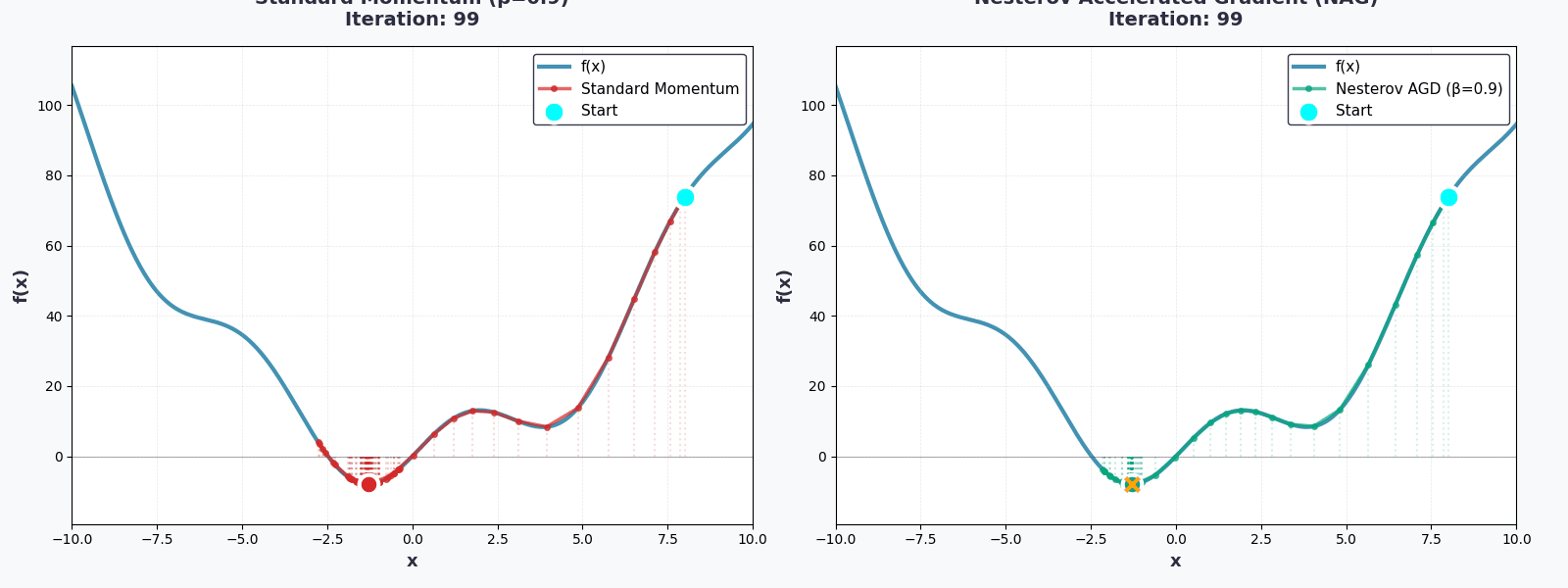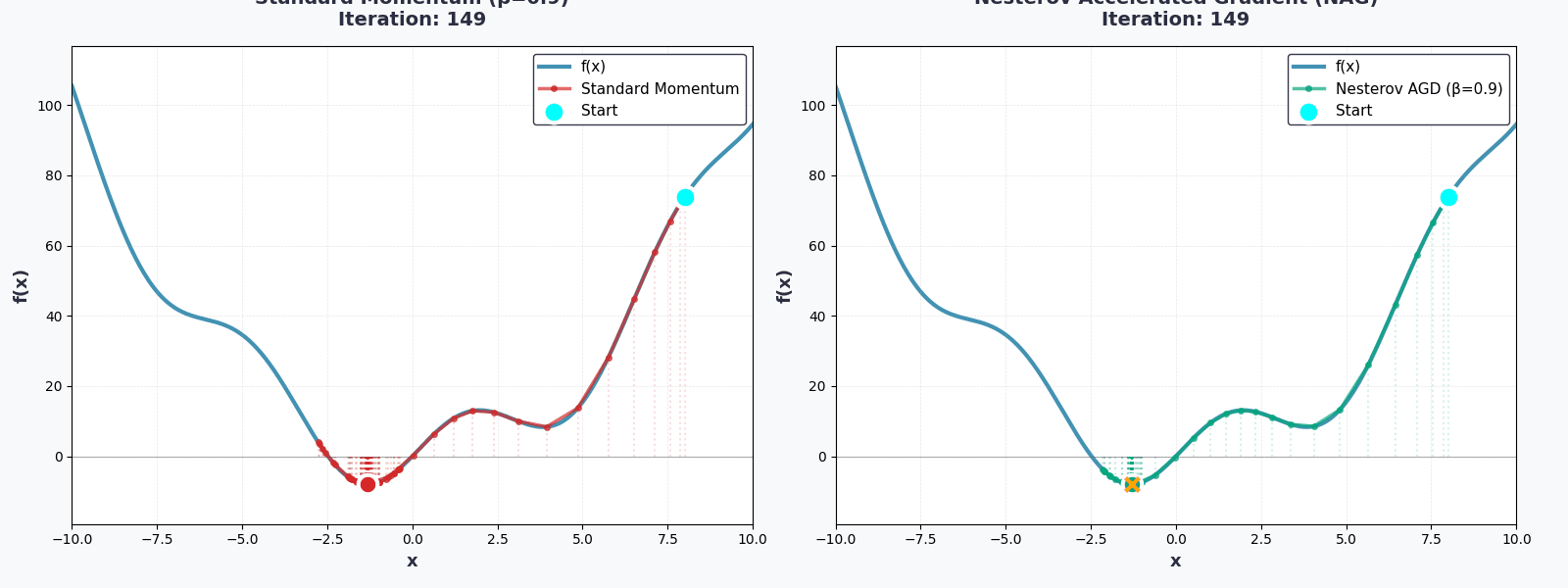

Bạn đã hoàn thành rồi!







