

ChatGPT Memory hoạt động như thế nào — và cách tự build Memory System cho AI Agent của bạn
Tổng quan
Chắc anh em nào cũng đã gặp cảnh này rồi:
Mở ChatGPT lên, chat một hồi, hỏi đủ thứ về dự án. Rồi đóng trình duyệt. Hôm sau mở lại — con bot nhìn mình như người lạ. "Bạn là ai? Bạn đang làm gì vậy?" (sad)
Xong tự hỏi: Sao nó không nhớ gì cả?
Rồi OpenAI tung ra tính năng Memory — ChatGPT giờ nhớ bạn thích viết TypeScript, nhớ bạn đang build SaaS, nhớ bạn đang dùng Next.js App Router… Mà không cần bạn phải nói lại từ đầu mỗi lần.
Và câu hỏi đặt ra là: Cơ chế đằng sau cái "nhớ" đó là gì? Nó lưu ở đâu? Và nếu muốn build một agent có khả năng tương tự thì phải làm sao?
Bài này mình sẽ đi sâu vào:
1. ChatGPT Memory thật sự hoạt động như thế nào bên dưới?
2. Kiến trúc 4 lớp và 4 loại memory
3. Luồng retrieval từng bước khi user gửi tin nhắn
4. Cách tự build memory system cho AI agent của bạn
5. Privacy controls — phần hay bị bỏ qua
Let's go!
1. ChatGPT "nhớ" bằng cách nào?
Trước khi đi vào kỹ thuật, mình muốn phá bỏ một hiểu lầm phổ biến:
ChatGPT không có bộ nhớ như não người. Nó không "nhớ" theo nghĩa liên tục. Mỗi request gửi lên vẫn là stateless.
Vậy cái "nhớ" đó đến từ đâu?
Hãy tưởng tượng thế này:
Bạn đi khám bác sĩ. Ông ấy không nhớ bạn từng gặp, nhưng trước khi vào phòng khám, y tá đã đưa cho ông ấy tờ hồ sơ ghi rõ: "Bệnh nhân dị ứng penicillin, năm ngoái gãy tay phải, thích hỏi về tác dụng phụ thuốc…"
Bác sĩ đọc tờ hồ sơ đó → nói chuyện với bạn như thể đã quen từ lâu.
ChatGPT Memory hoạt động y hệt như vậy.
Trước khi model nhận tin nhắn của bạn, hệ thống đã nhét vào đầu nó một đống context về bạn dưới dạng system prompt. Cụ thể là 3 phần:
- Model Set Context: Những thông tin cố định về bạn (tên, nghề nghiệp, sở thích…)
- Assistant Response Preferences: Bạn thích được trả lời kiểu gì (ngắn gọn, có code, có ví dụ thực tế…)
- Recent Conversation Content: Tóm tắt từ các cuộc hội thoại gần đây liên quan
→ Model "nhớ" vì nó đọc hồ sơ của bạn, không phải vì nó thật sự có long-term memory.
Đây là lý do tại sao bạn có thể xem và xóa từng memory trong Settings → Personalization → Memory — vì chúng chỉ là văn bản được lưu trong database, không phải gì "huyền bí" trong não model.
2. Kiến trúc 4 lớp bên trong
Nhìn tổng thể, hệ thống memory của ChatGPT (và các AI assistant tương tự) gồm 4 lớp chính:
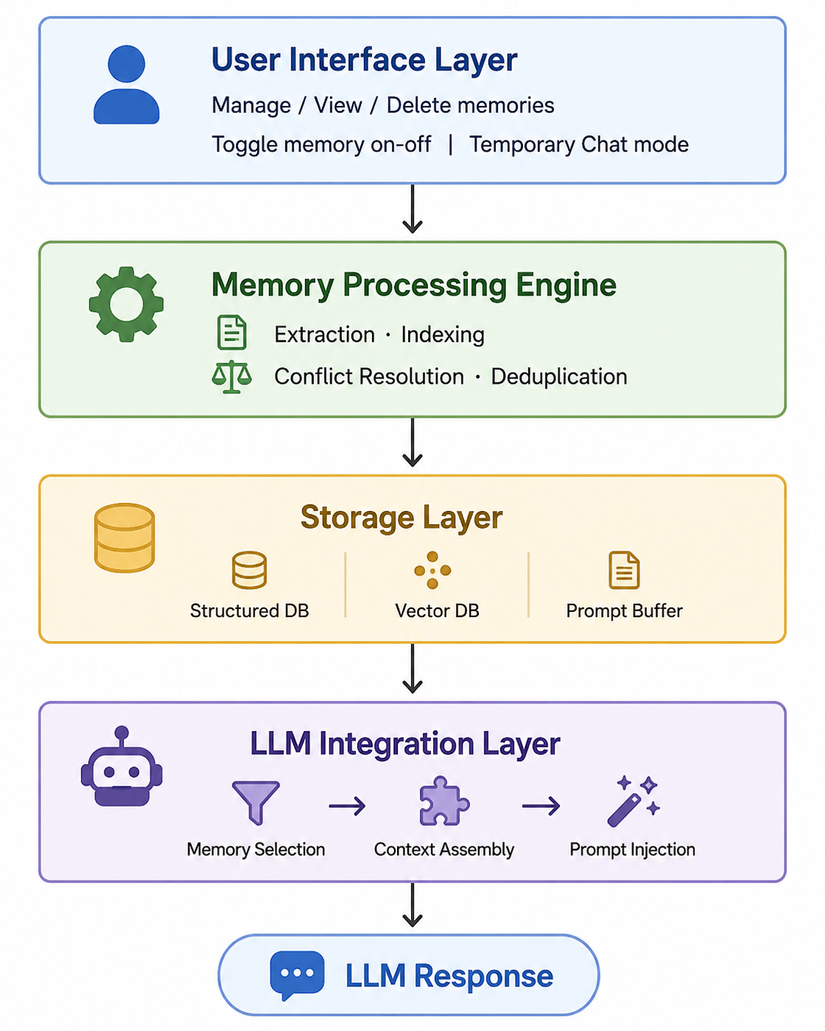
Lớp 1: User Interface Layer
Phần người dùng nhìn thấy và tương tác được:
- Màn hình quản lý memories (xem, chỉnh, xóa từng item)
- Toggle bật/tắt toàn bộ tính năng Memory
- Chế độ Temporary Chat — chat không lưu gì, như incognito mode của trình duyệt
Đây là lớp mà OpenAI thiết kế rất kỹ để đảm bảo user luôn có quyền kiểm soát.
Lớp 2: Memory Processing Engine
Đây là "bộ não xử lý" — phần phức tạp nhất và ít được nói đến nhất:
- Extraction: Sau mỗi cuộc hội thoại, một LLM nhỏ (extraction model) đọc lại toàn bộ conversation và trích xuất những thông tin đáng lưu. Ví dụ: từ đoạn hội thoại về việc bạn đang build app, nó extract ra "User đang dùng Next.js 14 App Router, deploy trên Vercel"
- Deduplication: Nếu thông tin mới giống với memory đã có, thay vì tạo duplicate, engine sẽ merge hoặc update.
- Conflict Resolution: Bạn từng nói dùng Vue, hôm nay nói dùng React — engine phải xử lý mâu thuẫn. Cách phổ biến: memory mới hơn thường override memory cũ, nhưng cũng có thể merge thành "User đã chuyển từ Vue sang React".
- Indexing: Tạo vector embedding cho mỗi memory để phục vụ semantic search sau này.
Lớp 3: Storage Layer
Nơi thật sự lưu dữ liệu — không phải một database duy nhất mà là nhiều loại storage cho từng mục đích:
| Storage Type | Dùng cho | Ví dụ |
|---|---|---|
| Relational DB (PostgreSQL) | User profile, preferences | user_id, language, timezone |
| Vector DB (Pinecone, Weaviate) | Episodic memories, semantic search | Embeddings của conversation summaries |
| Key-Value Store (Redis) | Session cache, active context | 5-10 tin nhắn gần nhất |
| Object Storage (S3) | Long-term archives | Toàn bộ conversation history (compressed) |
Lớp 4: LLM Integration Layer
Lớp ghép nối memory vào prompt context trước khi gửi cho model. Đây là nơi quyết định memory nào được chọn để đưa vào context hiện tại.
Quan trọng nhất là lớp này — vì context window có giới hạn, không thể nhét hết toàn bộ memory vào. Cần có cơ chế chọn lọc thông minh: chỉ lấy những memories liên quan nhất với câu hỏi hiện tại của user.
Cơ chế chọn lọc này thường là kết hợp:
- Semantic similarity (embedding cosine similarity): memory nào nói về chủ đề gần với câu hỏi hiện tại?
- Recency weight: memory gần đây được ưu tiên hơn memory cũ
- Explicit keyword match: nếu user nhắc đến tên project, tên tool cụ thể
3. 4 loại Memory — Không phải tất cả đều giống nhau
Đây là phần nhiều người hay nhầm. Memory không phải một khái niệm đồng nhất. Có 4 loại khác nhau, mỗi loại có cách lưu, cách truy vấn và lifecycle riêng:
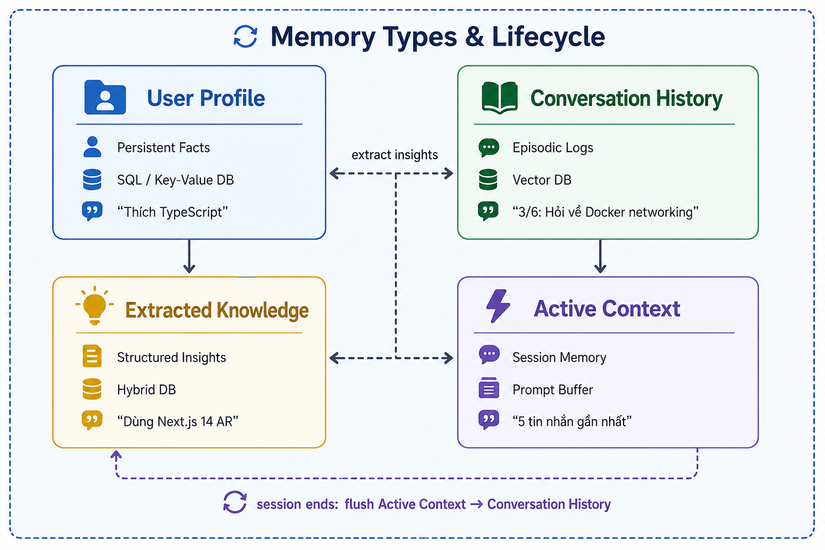
Loại 1: User Profile Memory (Persistent Facts)
Ví von: Đây như tờ hồ sơ cá nhân trong ngăn kéo của bác sĩ — thông tin cố định, ít thay đổi, nhưng rất quan trọng để cá nhân hóa.
- Lưu ở: Structured database (SQL, key-value)
- Ví dụ nội dung: tên, nghề nghiệp, stack yêu thích, timezone, ngôn ngữ ưa dùng, sở thích về response style (ngắn gọn vs chi tiết)
- Lifetime: Indefinite — tồn tại cho đến khi user chủ động xóa
- Cập nhật khi: Có thông tin mới rõ ràng hoặc conflict với thông tin cũ
Trong ChatGPT, đây là những gì bạn thấy khi vào Settings → Personalization → Manage Memories. Mỗi item là một "fact" về bạn.
Loại 2: Conversation History (Episodic Memory)
Ví von: Như nhật ký — ghi lại đúng những gì đã xảy ra, theo thứ tự thời gian, kèm timestamp và context.
Loại memory này quan trọng bởi vì nó cho phép agent hồi tưởng: "À, tuần trước mình và user đã thảo luận về vấn đề JWT expiration — liên quan đến câu hỏi hôm nay không nhỉ?"
- Lưu ở: Vector database (để semantic search)
- Ví dụ: "Ngày 20/3, user hỏi về Docker networking issue và mình đề xuất dùng overlay network", "Ngày 22/3, user báo overlay network hoạt động tốt, đóng ticket"
- Lifetime: Indefinite với optional archiving (move sang cold storage sau 6 tháng)
- Truy vấn: Kết hợp semantic similarity + timestamp filtering
ChatGPT hiện tại đưa vào context khoảng 40 entries gần nhất trong prompt. Phần còn lại vẫn được lưu nhưng cần explicit retrieval khi có semantic match đủ mạnh.
Đây chính là lý do tại sao ChatGPT có thể nhớ "Anh đang build SaaS về HR management" dù bạn mention điều đó 3 tuần trước — episodic memory của câu đó vẫn còn trong vector DB, và khi bạn hỏi câu liên quan, retrieval engine tìm ra nó.
Loại 3: Extracted Knowledge (Semantic Memory)
Ví von: Như ghi chú tóm tắt của một sinh viên giỏi — không phải chép nguyên bài giảng, mà trích lọc ra những insight quan trọng, có cấu trúc, dễ tra cứu.
Đây là kết quả của bước information extraction từ Conversation History. Thay vì lưu nguyên cuộc hội thoại dài 50 tin nhắn, engine trích xuất ra:
"User đang build B2B SaaS về HR management, tech stack: Next.js 14 App Router + Supabase + Tailwind, deploy Vercel, prefer Server Components, tránh client-side fetching khi không cần thiết."
Chỉ vài dòng nhưng capture được đủ context để cá nhân hóa.
- Lưu ở: Hybrid (structured + vector) để vừa tìm kiếm semantic vừa filter chính xác
- Lifecycle: Được update và merge khi có thông tin mới. Ví dụ: nếu sau đó bạn nói "Mình vừa chuyển từ Supabase sang PlanetScale", engine update memory thay vì tạo duplicate
- Đặc điểm: Đây là loại memory "cao cấp" nhất — nó không phải raw data mà là curated knowledge về user
Loại 4: Active Context (Working Memory)
Ví von: Như RAM trong máy tính — cực nhanh, cực accessible, nhưng chỉ tồn tại khi đang chạy. Tắt máy là mất.
Đây là cái mà dân AI hay gọi là "in-context memory" — toàn bộ conversation hiện tại đang nằm trong context window của model.
- Lưu ở: Prompt buffer (trực tiếp trong context window)
- Ví dụ: 5–10 tin nhắn gần nhất trong session hiện tại
- Lifetime: Session only — hết session là flush vào Episodic Memory (nếu có gì đáng lưu) rồi xóa
- Tốc độ truy cập: Instant — vì model đang đọc trực tiếp, không cần retrieval
Mối quan hệ giữa 4 loại: Active Context → kết thúc session → flush vào Conversation History → extraction engine chạy → tạo Extracted Knowledge → cập nhật User Profile (nếu có thay đổi quan trọng). Đây là vòng lifecycle của memory.
4. Luồng hoạt động khi bạn gửi một tin nhắn
Mình sẽ trace từng bước để mọi người thấy rõ. Ví dụ bạn gõ: "Hôm nay mình muốn refactor cái authentication module"
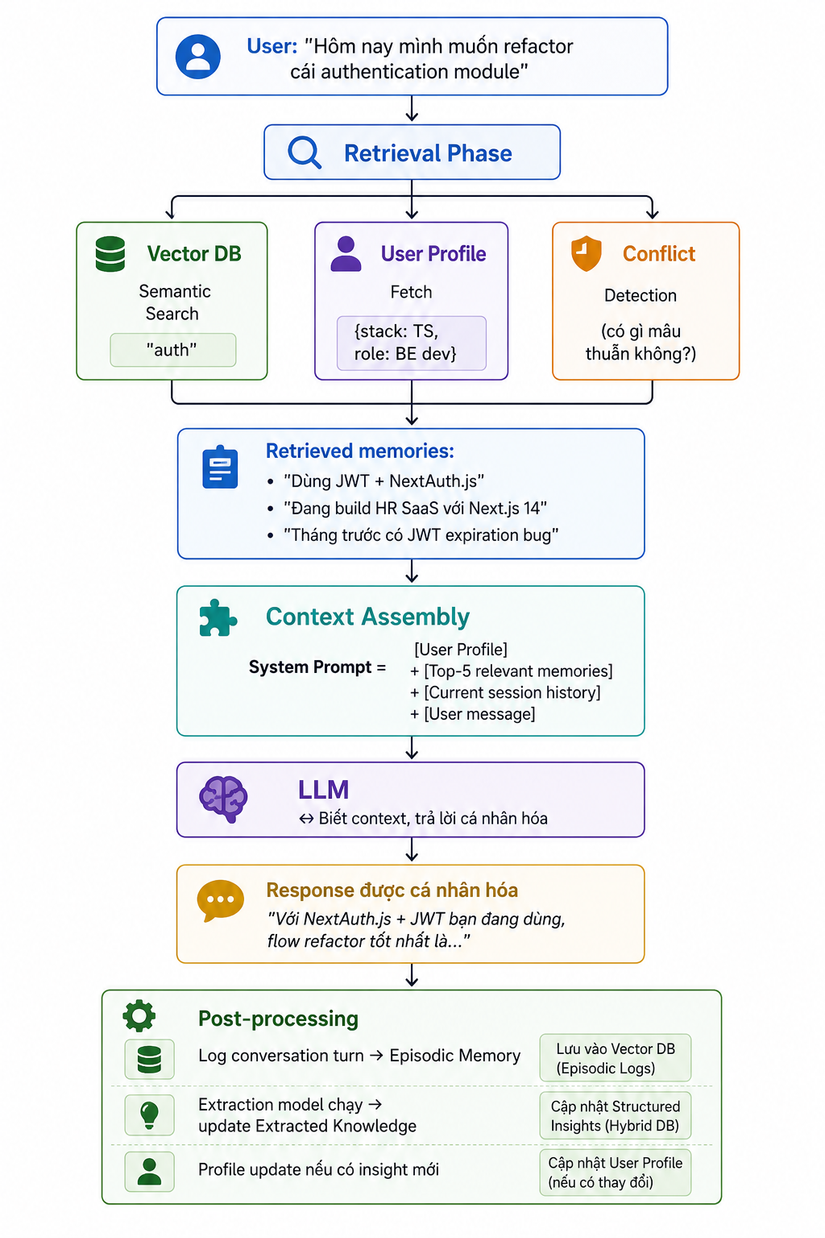
Bước quan trọng nhất chính là Retrieval Phase — hệ thống tìm kiếm memories nào liên quan nhất với câu hỏi hiện tại, không phải nhét hết tất cả vào.
Cả flow này diễn ra trong vài hundred milliseconds — đó là lý do response vẫn nhanh dù phải query thêm database.
Điểm thú vị về Conflict Detection:
Hệ thống phải check xem memories có mâu thuẫn nhau không trước khi đưa vào context. Ví dụ: memory A nói "Dùng Pages Router", memory B nói "Dùng App Router" — nếu nhét cả hai vào context, model bị confuse.
Giải pháp phổ biến: timestamp-based resolution — memory mới hơn được ưu tiên, memory cũ được đánh dấu là deprecated hoặc xóa.
5. Tự build Memory System cho Agent của bạn
Phần thú vị nhất. Mình sẽ đi qua 3-tier architecture — kiến trúc đơn giản nhất nhưng đủ mạnh cho hầu hết use cases.
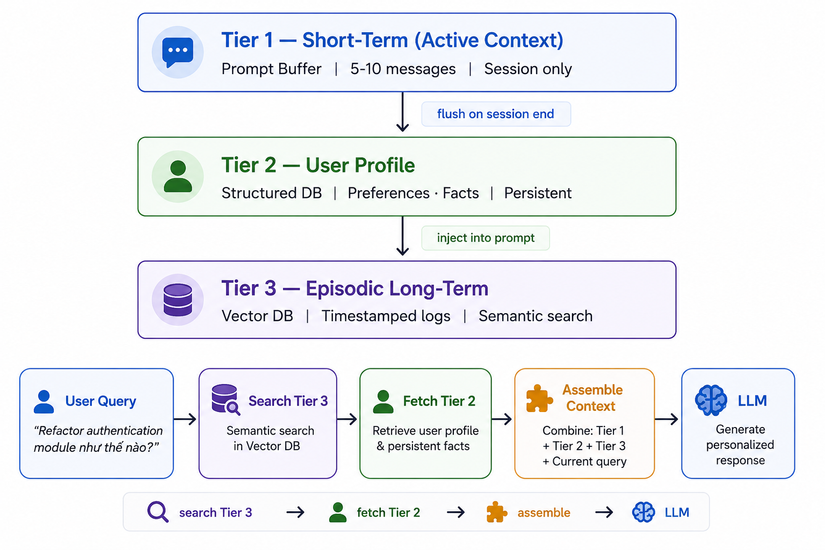
Tier 1: Short-Term Context Memory — Cái đơn giản nhất
Chỉ là một list các messages được giữ trong session, tự động trim khi vượt quá giới hạn:
# short_term_memory.py
conversation_history = []
MAX_HISTORY = 10
def add_message(role: str, content: str):
"""Thêm message vào short-term memory"""
conversation_history.append({
"role": role,
"content": content
})
# Trim nếu vượt quá giới hạn — xóa message cũ nhất
if len(conversation_history) > MAX_HISTORY:
conversation_history.pop(0)
def get_history() -> list:
return conversation_history
def clear_history():
conversation_history.clear()
Dùng cho: Context tức thời trong session hiện tại. Không cần database, không cần embedding — đơn giản nhất nhưng hiệu quả cho chat thông thường.
Tier 2: User Profile Memory — Dữ liệu người dùng lâu dài
Lưu trong structured database. Với prototype, SQLite hoặc thậm chí JSON file là đủ:
# user_profile.py
import json
import os
from datetime import datetime
PROFILE_DB_PATH = "user_profiles.json"
def load_profiles():
if os.path.exists(PROFILE_DB_PATH):
with open(PROFILE_DB_PATH, "r") as f:
return json.load(f)
return {}
def save_profiles(profiles):
with open(PROFILE_DB_PATH, "w") as f:
json.dump(profiles, f, indent=2, ensure_ascii=False)
def get_user_profile(user_id: str) -> dict:
profiles = load_profiles()
return profiles.get(user_id, {})
def update_user_profile(user_id: str, updates: dict):
"""Update profile — merge với data hiện có"""
profiles = load_profiles()
if user_id not in profiles:
profiles[user_id] = {"created_at": datetime.now().isoformat()}
profiles[user_id].update(updates)
profiles[user_id]["updated_at"] = datetime.now().isoformat()
save_profiles(profiles)
# Ví dụ sử dụng
update_user_profile("user_123", {
"preferences": {
"language": "Vietnamese",
"programming_language": "TypeScript",
"framework": "Next.js",
"response_style": "concise_with_examples"
},
"facts": {
"role": "Backend Developer",
"project": "HR SaaS startup",
"timezone": "Asia/Ho_Chi_Minh"
}
})
Trong production, replace JSON file bằng PostgreSQL hoặc MongoDB. Schema tương tự, chỉ đổi storage layer.
Tier 3: Episodic Long-Term Memory với Vector Database
Đây là phần quan trọng nhất khi muốn agent "nhớ" long-term. Cần một vector database để lưu và tìm kiếm theo semantic similarity.
So sánh 3 lựa chọn phổ biến:
| Vector DB | Ưu điểm | Nhược điểm | Phù hợp |
|---|---|---|---|
| Chroma | Lightweight, local, zero setup, free | Không scale tốt | Prototype, dev local |
| Pinecone | Cloud managed, scale cao, latency thấp, API đơn giản | Tốn tiền ở scale lớn | Production apps |
| Weaviate | Open-source, self-hosted, GraphQL API, hybrid search | Setup phức tạp hơn | Enterprise, tự host |
| Qdrant | Open-source, Rust performance, filter mạnh | Ecosystem nhỏ hơn | Performance-critical |
Implement với Chroma (nhanh nhất để bắt đầu):
# episodic_memory.py
import chromadb
from datetime import datetime
from openai import OpenAI
# Chroma client — local, không cần server
chroma_client = chromadb.Client()
collection = chroma_client.get_or_create_collection(
name="episodic_memories",
metadata={"hnsw:space": "cosine"} # Dùng cosine similarity
)
openai_client = OpenAI()
def get_embedding(text: str) -> list:
"""Tạo embedding từ text dùng OpenAI"""
response = openai_client.embeddings.create(
input=text,
model="text-embedding-3-small" # 1536 dimensions, rẻ và tốt
)
return response.data[0].embedding
def save_episodic_memory(
user_id: str,
content: str,
metadata: dict = None
):
"""Lưu một memory mới vào vector DB"""
embedding = get_embedding(content)
memory_id = f"{user_id}_{datetime.now().timestamp()}"
collection.add(
documents=[content],
embeddings=[embedding],
metadatas=[{
"user_id": user_id,
"timestamp": datetime.now().isoformat(),
"topic": metadata.get("topic", "general") if metadata else "general",
**(metadata or {})
}],
ids=[memory_id]
)
return memory_id
def search_relevant_memories(
user_id: str,
query: str,
n_results: int = 5
) -> list[str]:
"""Tìm top-N memories liên quan nhất với query"""
query_embedding = get_embedding(query)
results = collection.query(
query_embeddings=[query_embedding],
n_results=n_results,
where={"user_id": user_id}, # Filter theo user — quan trọng!
include=["documents", "metadatas", "distances"]
)
if not results["documents"][0]:
return []
# Trả về danh sách memories đã sort theo relevance
memories = []
for doc, meta, dist in zip(
results["documents"][0],
results["metadatas"][0],
results["distances"][0]
):
memories.append({
"content": doc,
"timestamp": meta.get("timestamp"),
"relevance_score": 1 - dist # Convert distance → similarity score
})
return memories
def delete_user_memories(user_id: str):
"""Xóa toàn bộ memories của một user — cho privacy control"""
results = collection.get(where={"user_id": user_id})
if results["ids"]:
collection.delete(ids=results["ids"])
6. Dùng Mem0 — Thư viện memory all-in-one
Nếu không muốn tự build từ đầu, Mem0 là lựa chọn cực hay. Nó wrap cả 3 tiers trên vào một interface đơn giản, cộng thêm conflict resolution và deduplication tự động:
pip install mem0ai
Cấu hình cơ bản với OpenAI + Chroma (local):
# mem0_basic.py
from mem0 import Memory
# Config đơn giản nhất — dùng OpenAI embedding, Chroma local
config = {
"llm": {
"provider": "openai",
"config": {
"model": "gpt-4o-mini",
"api_key": "your-openai-api-key"
}
},
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-3-small"
}
},
"vector_store": {
"provider": "chroma",
"config": {
"collection_name": "agent_memories",
"path": "./chroma_db" # Local storage
}
}
}
m = Memory.from_config(config)
# Lưu memories từ conversation
messages = [
{"role": "user", "content": "Mình đang build một SaaS dùng Next.js và Supabase"},
{"role": "assistant", "content": "Hay đó! Bạn đang dùng App Router hay Pages Router?"},
{"role": "user", "content": "App Router, và mình thích Server Components hơn"},
]
result = m.add(messages, user_id="user_123")
print(result)
# → {'results': [{'memory': 'User đang build SaaS với Next.js App Router + Supabase, thích Server Components', 'event': 'ADD'}]}
# Mem0 tự extract insight từ conversation — không cần bạn làm thủ công!
# Search memories liên quan
relevant = m.search(query="Next.js setup và deployment", user_id="user_123")
for mem in relevant["results"]:
print(f"Memory: {mem['memory']}")
print(f"Score: {mem['score']:.3f}")
# → Memory: User đang build SaaS với Next.js App Router + Supabase, thích Server Components
# → Score: 0.892
Config production với Pinecone:
# mem0_production.py
from mem0 import Memory
config = {
"llm": {
"provider": "openai",
"config": {
"model": "gpt-4o-mini",
"api_key": "your-openai-api-key"
}
},
"embedder": {
"provider": "openai",
"config": {
"model": "text-embedding-3-small"
}
},
"vector_store": {
"provider": "pinecone",
"config": {
"api_key": "your-pinecone-api-key",
"index_name": "agent-memory-prod",
"dimension": 1536,
"metric": "cosine",
"spec": {
"serverless": {
"cloud": "aws",
"region": "us-east-1"
}
}
}
},
# Thêm graph store nếu muốn relationship-based memory
"graph_store": {
"provider": "neo4j",
"config": {
"url": "bolt://localhost:7687",
"username": "neo4j",
"password": "your-password"
}
}
}
m = Memory.from_config(config)
Các operations quan trọng của Mem0:
# Thêm memory
m.add(messages, user_id="user_123")
# Search
results = m.search("deployment setup", user_id="user_123", limit=5)
# Xem tất cả memories của user
all_memories = m.get_all(user_id="user_123")
# Update một memory cụ thể
m.update(memory_id="abc123", data="User đã chuyển sang PlanetScale thay Supabase")
# Xóa một memory
m.delete(memory_id="abc123")
# Xóa toàn bộ memories của user (quan trọng cho privacy!)
m.delete_all(user_id="user_123")
# Memory history — xem quá trình thay đổi của một memory
history = m.history(memory_id="abc123")
7. Tích hợp vào Agent pipeline hoàn chỉnh
Giờ ghép tất cả lại thành một agent thực sự có memory:
# memory_agent.py
from mem0 import Memory
from openai import OpenAI
from user_profile import get_user_profile, update_user_profile
# Initialize
mem0 = Memory.from_config(config) # Config từ phần trên
openai_client = OpenAI()
# Short-term: giữ 10 tin nhắn gần nhất
session_history = []
MAX_SESSION_HISTORY = 10
def build_system_prompt(user_id: str, user_query: str) -> str:
"""Build system prompt có đầy đủ memory context"""
# 1. Lấy user profile
profile = get_user_profile(user_id)
profile_text = ""
if profile:
prefs = profile.get("preferences", {})
facts = profile.get("facts", {})
profile_text = f"""
Thông tin về user:
- Role: {facts.get('role', 'Unknown')}
- Tech stack: {prefs.get('programming_language', 'Unknown')} / {prefs.get('framework', 'Unknown')}
- Project: {facts.get('project', 'Unknown')}
- Response style: {prefs.get('response_style', 'balanced')}
"""
# 2. Search episodic memories liên quan đến query hiện tại
relevant_memories = mem0.search(
query=user_query,
user_id=user_id,
limit=5 # Chỉ lấy top-5 để tránh context overload
)
memories_text = ""
if relevant_memories["results"]:
memories_text = "\nNhững gì bạn biết về user từ các cuộc hội thoại trước:\n"
for mem in relevant_memories["results"]:
score = mem.get("score", 0)
if score > 0.7: # Chỉ lấy memories đủ relevant
memories_text += f"- {mem['memory']}\n"
system_prompt = f"""Bạn là một AI assistant thông minh và luôn nhớ context về user.
{profile_text}
{memories_text}
Hãy sử dụng context trên để trả lời một cách cá nhân hóa và nhất quán.
Đừng hỏi lại những thông tin bạn đã biết về user.
"""
return system_prompt
def chat_with_memory(user_id: str, user_message: str) -> str:
"""Main chat function với full memory support"""
# 1. Thêm user message vào session history
session_history.append({"role": "user", "content": user_message})
if len(session_history) > MAX_SESSION_HISTORY:
session_history.pop(0)
# 2. Build system prompt với memories
system_prompt = build_system_prompt(user_id, user_message)
# 3. Gọi LLM với full context
messages = [{"role": "system", "content": system_prompt}] + session_history
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=messages,
temperature=0.7
)
assistant_response = response.choices[0].message.content
# 4. Thêm response vào session history
session_history.append({"role": "assistant", "content": assistant_response})
if len(session_history) > MAX_SESSION_HISTORY:
session_history.pop(0)
# 5. Lưu cặp conversation vào long-term memory (async tốt hơn)
mem0.add(
messages=[
{"role": "user", "content": user_message},
{"role": "assistant", "content": assistant_response}
],
user_id=user_id
)
# 6. Extract và update profile nếu có info mới
_auto_update_profile(user_id, user_message)
return assistant_response
def _auto_update_profile(user_id: str, user_message: str):
"""Tự động detect và update profile từ message"""
# Simple heuristics — production cần dùng LLM để extract
message_lower = user_message.lower()
updates = {}
if "typescript" in message_lower or " ts " in message_lower:
updates["programming_language"] = "TypeScript"
if "next.js" in message_lower or "nextjs" in message_lower:
updates["framework"] = "Next.js"
if "react" in message_lower and "native" not in message_lower:
updates["framework"] = "React"
if updates:
current = get_user_profile(user_id)
prefs = current.get("preferences", {})
prefs.update(updates)
update_user_profile(user_id, {"preferences": prefs})
# ============================================================
# Demo sử dụng
# ============================================================
if __name__ == "__main__":
user_id = "user_123"
# Lần 1: Giới thiệu về dự án
response1 = chat_with_memory(
user_id,
"Mình đang build một app HR management với Next.js 14 và Supabase"
)
print("Response 1:", response1[:200])
# Lần 2: Câu hỏi về auth (agent sẽ nhớ context từ lần 1)
response2 = chat_with_memory(
user_id,
"Cách tốt nhất để implement authentication là gì?"
)
print("Response 2:", response2[:200])
# Agent biết bạn dùng Next.js + Supabase → recommend Supabase Auth, không phải generic answer
print("\n--- Memories được lưu: ---")
all_mems = mem0.get_all(user_id=user_id)
for mem in all_mems["results"]:
print(f" • {mem['memory']}")
8. Recency + Relevance Scoring — Bí quyết chọn đúng memory
Không phải memory nào cũng quan trọng như nhau. Memory từ tuần trước về cùng topic thì relevant hơn memory từ 6 tháng trước về topic khác. Cần kết hợp semantic similarity và recency decay:
# memory_scorer.py
import math
from datetime import datetime, timezone
def compute_recency_weight(
memory_timestamp: str,
decay_rate: float = 0.1
) -> float:
"""
Tính recency weight theo exponential decay.
Memory càng cũ → weight càng thấp.
decay_rate: 0.1 ≈ half-life ~7 ngày
"""
memory_dt = datetime.fromisoformat(memory_timestamp)
if memory_dt.tzinfo is None:
memory_dt = memory_dt.replace(tzinfo=timezone.utc)
now = datetime.now(timezone.utc)
days_ago = (now - memory_dt).total_seconds() / 86400 # Convert to days
return math.exp(-decay_rate * days_ago)
def score_and_rank_memories(
memories: list[dict],
semantic_weight: float = 0.7,
recency_weight: float = 0.3
) -> list[dict]:
"""
Rank memories dựa trên kết hợp:
- Semantic similarity score (từ vector search)
- Recency score (decay theo thời gian)
semantic_weight + recency_weight = 1.0
"""
scored = []
for mem in memories:
semantic_score = mem.get("score", 0.5) # Score từ vector DB
recency_score = compute_recency_weight(
mem.get("timestamp", datetime.now().isoformat())
)
# Combined score
final_score = (
semantic_weight * semantic_score +
recency_weight * recency_score
)
scored.append({
**mem,
"semantic_score": semantic_score,
"recency_score": recency_score,
"final_score": final_score
})
# Sort by final score descending
return sorted(scored, key=lambda x: x["final_score"], reverse=True)
# Ví dụ sử dụng
raw_memories = [
{
"memory": "Dùng Supabase cho database",
"score": 0.85,
"timestamp": "2026-01-15T10:00:00" # 5 tháng trước — cũ
},
{
"memory": "Vừa chuyển sang PlanetScale",
"score": 0.70,
"timestamp": "2026-05-30T14:00:00" # 1 tuần trước — mới
},
{
"memory": "Thích dùng TypeScript strict mode",
"score": 0.60,
"timestamp": "2026-06-01T09:00:00" # 5 ngày trước
}
]
ranked = score_and_rank_memories(raw_memories)
for mem in ranked:
print(f"Score: {mem['final_score']:.3f} | {mem['memory']}")
# Output:
# Score: 0.713 | Vừa chuyển sang PlanetScale ← Mới + khá relevant → top
# Score: 0.634 | Thích dùng TypeScript strict mode
# Score: 0.622 | Dùng Supabase cho database ← Cũ, bị đẩy xuống dù semantic score cao
Đây là lý do tại sao khi bạn nói "Vừa chuyển từ Supabase sang PlanetScale", ChatGPT sẽ dùng thông tin mới nhất chứ không tiếp tục nói về Supabase.
9. Privacy Controls — Đừng bỏ qua phần này
Đây là phần mà nhiều dev khi build memory system hay bỏ qua, nhưng lại cực kỳ quan trọng khi đưa lên production. Đặc biệt khi anh em có user thật, dữ liệu thật.

API endpoints bắt buộc phải có khi build memory system:
# privacy_controls.py
from fastapi import FastAPI, HTTPException
from mem0 import Memory
app = FastAPI()
m = Memory.from_config(config)
@app.get("/users/{user_id}/memories")
def list_memories(user_id: str):
"""
[BẮTBUỘC] User xem toàn bộ memories của mình.
Theo GDPR Article 15: "right to access"
"""
memories = m.get_all(user_id=user_id)
return {
"user_id": user_id,
"total_count": len(memories["results"]),
"memories": [
{
"id": mem["id"],
"content": mem["memory"],
"created_at": mem.get("created_at"),
"updated_at": mem.get("updated_at")
}
for mem in memories["results"]
]
}
@app.delete("/users/{user_id}/memories/{memory_id}")
def delete_memory(user_id: str, memory_id: str):
"""
[BẮTBUỘC] Xóa một memory cụ thể.
Theo GDPR Article 17: "right to be forgotten"
"""
# Verify memory belongs to this user trước khi xóa
all_mems = m.get_all(user_id=user_id)
memory_ids = [mem["id"] for mem in all_mems["results"]]
if memory_id not in memory_ids:
raise HTTPException(404, "Memory not found for this user")
m.delete(memory_id=memory_id)
return {"message": f"Memory {memory_id} deleted successfully"}
@app.delete("/users/{user_id}/memories")
def delete_all_memories(user_id: str):
"""
[BẮTBUỘC] Xóa toàn bộ memories — "Reset memory"
Cực kỳ quan trọng cho privacy compliance
"""
m.delete_all(user_id=user_id)
return {"message": f"All memories for user {user_id} deleted"}
@app.post("/chat/temporary")
def chat_temporary(message: str):
"""
[NÊN CÓ] Chat không lưu bất kỳ thứ gì — Temporary/Incognito mode
User dùng khi không muốn AI ghi nhớ conversation này
"""
response = openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": message}]
# KHÔNG gọi m.add() ở đây
# KHÔNG lưu vào session history
)
return {"response": response.choices[0].message.content}
Data Minimization — Những thứ KHÔNG được lưu:
# data_sanitizer.py
import re
SENSITIVE_PATTERNS = [
r'\b\d{3}-\d{2}-\d{4}\b', # SSN (US)
r'\b\d{9,12}\b', # CMND/CCCD
r'\b(?:\d{4}[\s-]?){3}\d{4}\b', # Credit card
r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b', # Email
r'\b(?:\+84|0)\d{9,10}\b', # Số điện thoại VN
]
def sanitize_before_storing(text: str) -> str:
"""
Xóa thông tin nhạy cảm trước khi lưu vào memory.
Luôn chạy function này trước khi gọi m.add()
"""
for pattern in SENSITIVE_PATTERNS:
text = re.sub(pattern, "[REDACTED]", text)
return text
# Sử dụng
safe_content = sanitize_before_storing(user_message)
m.add([{"role": "user", "content": safe_content}], user_id=user_id)
10. MemGPT / Letta — Khi bạn muốn đi sâu hơn nữa
Đây là phần bonus cho anh em muốn hiểu kiến trúc memory phức tạp hơn.
MemGPT (nay là Letta) là một kiến trúc khác hẳn. Thay vì memory được inject vào prompt từ bên ngoài, Letta cho phép LLM tự quyết định khi nào cần đọc/ghi memory.
Hình dung thế này:
Nếu hệ thống memory thông thường giống như y tá chuẩn bị hồ sơ sẵn cho bác sĩ, thì MemGPT giống như bác sĩ có quyền tự mở ngăn kéo hồ sơ bất cứ lúc nào trong quá trình khám — tự quyết định khi nào cần tra cứu thêm thông tin cũ.
# Letta client cơ bản
from letta import create_client
client = create_client()
# Tạo agent với memory capabilities
agent = client.create_agent(
name="memory_agent",
memory_blocks=[
{
"label": "human", # Memories về user
"value": "User là một Backend Developer đang build HR SaaS",
"limit": 2000 # Char limit cho memory block này
},
{
"label": "persona", # Personality của agent
"value": "Tôi là một AI assistant thông minh, luôn nhớ context",
"limit": 1000
}
],
tools=["archival_memory_insert", "archival_memory_search"]
# Agent có thể tự gọi tools này để đọc/ghi long-term memory
)
# Chat với agent — nó tự manage memory
response = client.send_message(
agent_id=agent.id,
message="Cách tốt nhất để optimize Postgres queries là gì?",
role="user"
)
print(response.messages[-1].text)
Điểm khác biệt then chốt của MemGPT:
- OS-inspired paging: LLM có "main context" (như RAM) và "archival storage" (như disk). Khi main context đầy, LLM tự quyết định gì cần "swap out" vào archival
- Self-directed retrieval: LLM chủ động search archival memory khi cần, không phải hệ thống tự inject
- Function calling: Dùng tool calls để đọc/ghi memory, tạo vòng lặp suy nghĩ phức tạp hơn
Letta phù hợp cho use cases cần long-horizon reasoning — agent phải nhớ và liên kết thông tin từ rất nhiều sessions khác nhau.
11. Bài học kinh nghiệm
BÀI HỌC KINH NGHIỆM:
Mình đã thử build memory system cho một internal chatbot của team và học được khá nhiều thứ theo cách... đau nhất.
Bài học 1: Context Window Budget — Đừng tham lam
Lần đầu build, mình nhét hết toàn bộ memories liên quan vào prompt. Kết quả: model bị context overload, response chất lượng giảm rõ rệt, thậm chí hallucinate khi phải "đọc" quá nhiều thứ cùng lúc.
Giải pháp: Hard limit ở 5–7 memories tối đa, kết hợp với relevance threshold (chỉ lấy memories có score > 0.7). Kém quantity nhưng quality tốt hơn rất nhiều.
Bài học 2: Conflict Resolution là mandatory, không phải optional
User thay đổi tech stack, đổi job, đổi project — những thứ này xảy ra thường xuyên hơn mình nghĩ. Nếu không có conflict resolution, agent sẽ nói những thứ mâu thuẫn nhau và mất đi sự tin tưởng của user.
Giải pháp: Dùng Mem0 (nó handle deduplication và conflict tốt hơn tự build từ đầu), hoặc nếu tự build thì implement "supersede" mechanism — khi có memory mới về cùng topic, mark memory cũ là deprecated.
Bài học 3: Lưu quá nhiều ≠ Nhớ tốt hơn
Lúc đầu mình lưu tất cả mọi thứ — kể cả những câu hỏi casual, những conversation không có giá trị. Kết quả: vector DB đầy toàn "rác", retrieval quality giảm vì nhiều irrelevant results.
Giải pháp: Implement memory worthiness filter — trước khi save, check xem memory này có đủ giá trị để lưu lâu dài không. Simple heuristic: chỉ lưu thông tin về preferences, facts, decisions — không lưu small talk.
def is_worth_storing(content: str) -> bool:
"""
Heuristic đơn giản để filter trước khi lưu.
Production nên dùng LLM để classify chính xác hơn.
"""
# Quá ngắn → probably không có value
if len(content.split()) < 5:
return False
# Các indicator của valuable memory
valuable_keywords = [
"đang dùng", "thích", "không thích", "prefer", "đang build",
"project", "stack", "framework", "database", "deploy", "team",
"requirement", "constraint", "goal", "objective"
]
content_lower = content.lower()
keyword_count = sum(1 for kw in valuable_keywords if kw in content_lower)
return keyword_count >= 1 # Ít nhất 1 keyword có giá trị
Bài học 4: Privacy phải là first-class citizen
Khi add user thật vào test, mình mới realize là chưa có cơ chế nào để user xóa memories. Phải refactor lại khá nhiều. Từ bây giờ mình luôn design privacy controls trước khi code feature memory.
Kết luận
Tóm gọn lại những gì mình đã đi qua:
- ChatGPT "nhớ" bằng cách nhét memory context vào system prompt trước mỗi request — không phải bộ nhớ thật sự, nhưng hiệu quả tương đương
- Có 4 loại memory khác nhau với lifecycle và storage riêng: Profile, Episodic, Extracted Knowledge, và Active Context
- Kiến trúc 4 lớp: UI → Processing Engine → Storage → LLM Integration
- Build memory system không khó: bắt đầu với Chroma + Mem0 cho prototype, scale lên Pinecone cho production
- Recency + relevance scoring là bí quyết để chọn đúng memory cần đưa vào context
- Privacy controls là bắt buộc, không phải optional — visibility, deletion, temporary mode
- MemGPT/Letta nếu muốn đi sâu vào self-directed memory management
Nếu anh em đang build AI agent và muốn nó "thông minh hơn" theo thời gian, nhớ người dùng như một người bạn thực sự — memory system chính là missing piece.
Nguồn tham khảo:






