

ANOVA (Analysis of Variance) là công cụ dùng để phân tích phương sai trong toán thống kê. ANOVA được sử dụng chủ yếu để so sánh trung bình của 2 đến 3 nhóm dữ liệu trở lên có bằng nhau hay không. ANOVA sử dụng giá trị thống kê F, tỷ lệ giữa hai phương sai.
Bài viết dưới sẽ đề cập đến cách sử dụng ANOVA một chiều để đưa ra kết luận 3 tập dữ liệu có trung bình bằng nhau hay không.
Bài toán
Để hiểu hơn về cách sử dụng ANOVA. Chúng ta có thể áp dụng vào bài toán thử nghiệm như sau.
Giả sử chúng ta có lợi nhuận 3 sản phẩm tính theo ngày. Chúng ta muốn biết 3 sản phẩm có lợi nhuận trung bình bằng nhau hay không. Dưới là code để tạo dữ liệu thử nghiệm.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy
np.random.seed(42)
data_1 = np.random.normal(size=100, loc=70, scale=4.2)
data_2 = np.random.normal(size=80, loc=74, scale=4.5)
data_3 = np.random.normal(size=70, loc=71, scale=4.0)
bins = 50
fig, ax = plt.subplots(1, 1, figsize=(10, 6))
sns.distplot(data_1, bins=bins, ax=ax, label="product 1 ($)")
sns.distplot(data_2, bins=bins, ax=ax, label="product 2 ($)")
sns.distplot(data_3, bins=bins, ax=ax, label="product 3 ($)")
ax.legend()
plt.show()
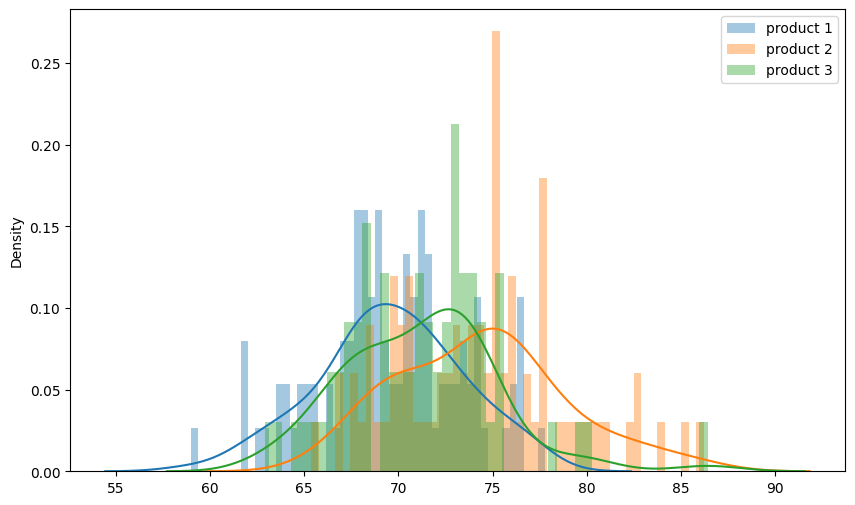
Hình 1: Histogram cho thấy phân phối của 3 dữ liệu doanh thu trung bình từng ngày (dữ liệu tư tạo). Mẫu 1 có 100 ngày, mẫu 2 có 80 ngày, mẫu 3 có 70 ngày. 3 phân phối có hình giống phân phối chuẩn
ANOVA
Kiểm tra điều kiện sử dụng F-test
- Các mẫu đều độc lập: lấy dữ liệu cho mẫu không làm ảnh hưởng đến việc lấy dữ liệu cho mẫu khác.
- Các mẫu được lấy từ tập hợp mẹ có phân phối chuẩn: bình thường nếu dữ liệu mẫu có phân phối chuẩn thì dữ liệu mẹ cũng có phân phối chuẩn.
- Hiệp phương sai đồng nhất: các tập hợp mẹ (mà ta lấy mẫu) có độ lệch chuẩn bằng nhau. Bình thường ta có thể sử dụng Levene test để kiểm tra. Nếu Levene test cho thấy là ta không thể bác bỏ null hypothesis, có nghĩa là các phương sai bằng nhau và độ lệch chuẩn của mẫu có nhiều khả năng là bằng nhau.
Trong bài toán trên, ta áp dụng hàm random.normal cho từng nhóm, nên thỏa mãn điều kiện 1.
Đồng thới dữ liệu mẫu có phân phối chuẩn nên tập hợp dự liệu mẹ cũng sẽ có phân phối chuẩn, thỏa mãn điều kiện 2. Thực ra, ta tạo dữ liệu từ hàm random.normal nên tập hợp mẹ sẽ có phân phối chuẩn.
Sau đó ta có thể dùng levene test sẽ cho p-value lớn hơn 0.05: các phương sai bằng nhau, thỏa mãn điều kiện 3.
levene_stats, levene_p_value = scipy.stats.levene(data_1, data_2, data_3)
# levene_p_value = 0.3813
Các điều kiện được thỏa mãn, nên ta có thể áp dụng ANOVA.
Giải bài toán bằng code
Giả thuyết
Đầu tiên ta sẽ phải lập giả thuyết:
- H0(giả thuyết không): Trung bình của các tập hợp mẹ (tập hợp mẹ của mẫu data_1, data_2, data_3) bằng nhau.
- H1(giả thuyết đối lập): Trung bình của các tập hợp mẹ khác nhau.
Sử dụng kết quả của ANOVA ta có thể kết luận một trong 2:
- Bác bỏ giả thuyết H0 và chấp nhận giả thuyết H1 là đúng.
- Ta không thể bác bỏ giả thuyết H0
Tổng bình phương
Để áp dụng ANOVA chúng ta sẽ tính 3 giá trị:
- Sum of Squares Between Group (SSB): Tổng bình phương giữa các nhóm dữ liệu.
- Sum of Squares Within Group (SSW): Tổng bình phương trong các nhóm dữ liệu.
- Sum of Squares Total (SST): Tổng bình phương của toàn bộ dữ liệu. Chúng ta không sử dụng giá trị này trong ANOVA nhưng chỉ tính để hiểu rõ hơn.
Tính SSB
Ta lấy trung bình của từng nhóm trừ đi cho trung bình của toàn bộ dữ liệu. Bình phương lên, nhân với số dữ liệu trong từng nhóm. Cuối cùng ta sẽ tính tổng.
ssb = 0
for group in all_groups:
g_mean = group.mean()
all_mean = all_obs.mean()
ssb += group.size * ((g_mean - all_mean)**2).sum()
# ssb = 1035.058973169103
Tính SSW
Ta lấy dữ liệu trong từng nhóm trừ đi trung bình của nhóm mẫu. Bình phương lên và tính tổng.
all_groups = [data_1, data_2, data_3]
ssw = 0
for group in all_groups:
g_mean = group.mean()
# Mean of each group
print(g_mean)
ssw += ((group - g_mean)**2).sum()
# ssw = 4157.383001231592
Tính SST
Ta lấy từng dữ liệu trừ đi cho trung bình của toàn bộ dữ liệu. Bình phương lên và tính tổng.
sst = np.sum((all_obs - all_obs.mean())**2)
# sst = 5192.441974400697
SST không được sử dụng trực tiếp trong ANOVA. Tuy nhiên có điểm đặc biệt là SSW + SSB = SST.
assert (round(ssw + ssb, 5) == round(sst,5))
Tính giá trị thống kê F
Tính bậc tự do của SSB và SSW. Chỉ cần sử dụng công thức dưới:
# 3 nhóm trừ 1
ssb_df = (len(all_groups) -1)
# ssb_df = 2
# tổng cộng 230 dữ liệu của cả ba nhóm, trừ 1 dữ liệu của từng nhóm (trừ 3 cho tất cả nhóm)
ssw_df = (all_obs.size - len(all_groups))
# ssw_df = 247
Lưu ý đầu tiên chúng ta tính MSB và MSW, có thể nghĩ đơn giản:
- MSB: phương sai của trung bình giữa các nhóm
- MSW: phương sai trong nhóm.
msb = ssb/ssb_df
msw = ssw/ssw_df
Sau dó chúng ta tính giá trị thống kê F, tỷ lệ của phương sai: MSB/MSW
f_stats = msb/msw
# f_stats = 30.747656193455267
# Hiểu đơn giản là phương sai MSB lớn hơn MSW 31 lần
Sau đó ta có thể tính p-value, nếu giả thuyết H0 đúng xác xuất mà F=30.747 là bao nhiêu:
# Survival function (SF) = 1 - cumulative distribution function (CDF
p_value = f.sf(f_stats, ssb_df, ssw_df)
# p_value = 1.1909003471573717e-12
Sử dụng code ngắn
Sử dụng code này sẽ cho ta kết quả giống như trên. Lúc áp dụng vào bài toán thực tế, nên sử dụng code dưới.
from scipy.stats import f_oneway
f_stats, p_value = f_oneway(data_1, data_2, data_3)
# f_stats = 30.747656193455335
# p_value = 1.1909003471573105e-12
Cách đánh giá
Giống như các cách kiểm định giả thuyết thống kê khác chúng ta sẽ sử dụng giá trị alpha là 0.05. Có thể hiểu đây là ngưỡng xác xuất, ta chỉ cho phép khả năng chúng ta lấy mẫu một cách ngẫu nhiên, mà tình cờ cho ra trung bình rất khác là 0.05.
So sánh p value và alpha
- Nếu p_value lớn hơn alpha, thì có nghĩa là ta không thể bác bỏ được H0
- Nếu p_value nhỏ hơn alpha, ta bác bỏ H0 và chấp nhận H1.
alpha = 0.05
p_value < alpha
# True
Với kết quả trên, p_value nhỏ hơn alpha, nên ta có thể bác bỏ giả thuyết H0 và chấp nhận giả thuyết H1. Có nghĩa là ta có thể tự tin 99.99...% (1 - p_value) là ba sản phẩm đưa ra lợi nhuận khác nhau. Chúng ta có thể cân nhắc bán sản phẩm có lợi nhuận cao nhất.
Kết luận
Vậy trong bài viết này chúng ta đã tìm hiểu ANOVA là gì, điều kiện áp dụng, công thức, code sử dụng trong thực tế. Cuối cùng ta đưa ra kết luận về dữ liệu sau khi dùng ANOVA một chiều.
Điểm lưu ý là ANOVA chỉ cho ta biết là các nhóm khác nhau, nhưng không cho ta biết chắc chắn là nhóm nào khác. Bình thường ta có thể phán đoán từ dữ liệu: nhóm nào trung bình cao nhất hoặc thấp nhất. Tuy nhiên, có phương pháp chuẩn, Least Significant Difference (LSD), phương pháp này có thể được đề cập trong bài viết sau.
Bài viết tham khảo:
https://blog.minitab.com/en/adventures-in-statistics-2/understanding-analysis-of-variance-anova-and-the-f-test
Nếu có những khái niệm không rõ có thể tham khảo các bài viết liên quan:
Phân phối chuẩn:
/cac-loai-phan-phoi-va-tinh-chat/
Kiểm định giả thuyết thống kê:
/ghost/#/editor/post/5d6a6353bf919d0001802947/






