

Bạn đã bao giờ gặp tình huống: tăng instance size lên gấp đôi, chi phí tăng gấp đôi, nhưng performance... gần như không đổi?
Bottleneck (nghẽn cổ chai) là hiện tượng một thành phần trong hệ thống trở thành điểm giới hạn, khiến toàn bộ pipeline không thể hoạt động nhanh hơn, bất kể các thành phần khác mạnh đến đâu.
Hãy hình dung một con đường 6 làn xe đang chạy bon bon, bỗng nhiên thu hẹp lại còn 1 làn vì đang sửa đường. Dù bạn có mở rộng đoạn đường phía trước thành 10 làn, tất cả xe vẫn phải xếp hàng chờ qua đoạn 1 làn đó.
Trong AWS, bottleneck có thể xuất hiện ở bất kỳ đâu: CPU, memory, disk I/O, network, hay thậm chí là những service quota mà bạn chưa bao giờ để ý đến. Và giải pháp không phải lúc nào cũng là "chọn instance to hơn".
1. Case study: Migrate RDS Oracle (400GB) sang Aurora PostgreSQL
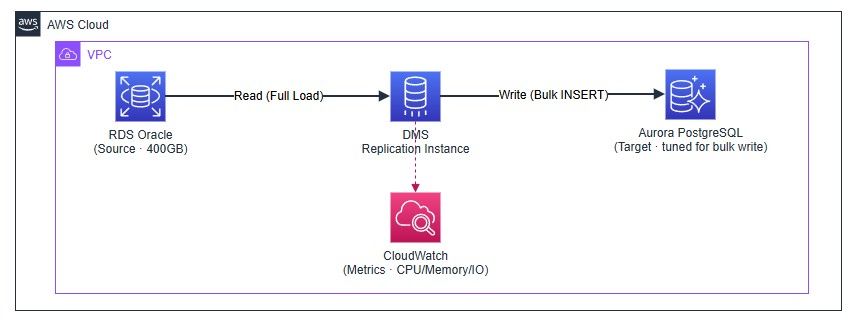
1.1. Bối cảnh
Dự án cần thực hiện migration từ RDS Oracle sang Aurora PostgreSQL. Đây là một bài toán khá phổ biến khi các tổ chức muốn thoát khỏi license cost của Oracle và chuyển sang open-source database.
- Source: RDS Oracle — 400GB data
- Target: Aurora PostgreSQL
- Tool: AWS Database Migration Service (DMS)
- Yêu cầu: Full load migration, chuyển đổi data type, không có transformation phức tạp
- Quy trình: Diễn tập ở môi trường STG trước, sẽ thực hiện trên PROD khi đã tối ưu hiệu năng để hạn chế tối thiểu downtime hệ thống.
Cấu hình ban đầu (lúc gặp vấn đề):
| Thành phần | Instance type | vCPU | RAM |
|---|---|---|---|
| RDS Oracle (source) | db.r6i.large | 2 vCPU | 16 GiB |
| DMS (replication) | c5.4xlarge | 16 vCPU | 32 GiB |
| Aurora PostgreSQL (target) | db.r6g.large | 2 vCPU | 16 GiB |
DMS instance type c5.4xlarge (1,826.10$/tháng)
1.2. Vấn đề
Mặc dù đã chọn instance type lớn cho cả 3 thành phần (Oracle source, Aurora target, DMS replication instance), quá trình migrate vẫn cực kỳ chậm.
Team bắt đầu debug bằng cách khoanh vùng. Nhìn phía hai đầu: CPU và throughput của cả Oracle (source) lẫn Postgres (target) đều thấp. Vậy nghẽn không nằm ở hai đầu — bottleneck gần như chắc chắn ở DMS.
Phân tích metric ngay tại DMS thì phát hiện một điều lạ: CPU vẫn thấp, nhưng memory lại full.
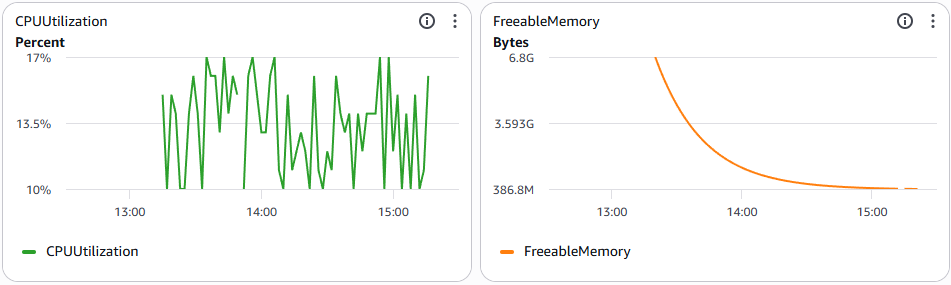
Lúc này team mới nhận ra mình đã đánh giá sai bài toán ngay từ đầu.
DMS replication instance được chọn là dòng compute-optimized (high CPU, low memory). Tuy nhiên:
- Bài toán migration này chủ yếu là đọc data → buffer → ghi data
- Không có heavy transformation hay tính toán phức tạp
- DMS cần memory để buffer data trong quá trình chuyển đổi, không cần CPU mạnh
👉Chọn instance "to" theo CPU là to sai chỗ.
👉Cuối cùng, chúng tôi quyết định đổi DMS instance sang dòng memory-optimized (r6i.2xlarge - 8 vCPU / 64 GiB - 1,227.50$/tháng) — nhiều RAM hơn để buffer data, không chạy theo CPU, nhưng giá lại rẻ hơn.
1.3. Xuất hiện vấn đề mới
Sau khi đổi DMS instance, CPU và memory cân bằng hơn, tốc độ migrate có vẻ tốt hơn — nhưng vẫn chưa đạt kỳ vọng.
Chúng tôi tiếp tục phân tích metric ở cả 3 thành phần. Lần này DMS đã ổn, Oracle vẫn rảnh, nhưng phía Aurora bắt đầu lộ vấn đề: WriteLatency và CommitLatency tăng cao, dù WriteIOPS chưa chạm trần.
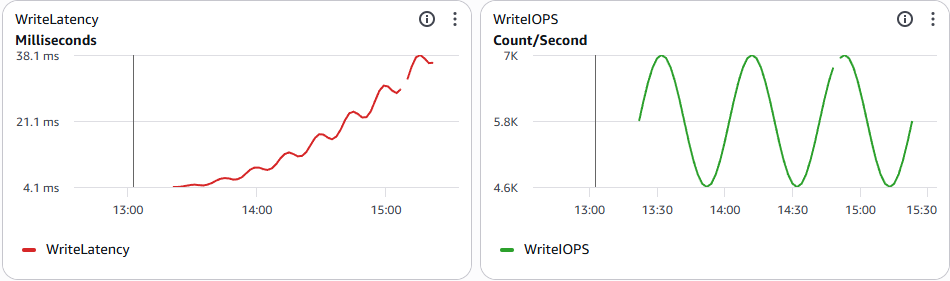
👉Bottleneck đã dịch chuyển. Sửa được điểm nghẽn này thì điểm nghẽn tiếp theo lộ ra.
Lần này, thay vì tiếp tục soi ở tầng hạ tầng AWS (instance type, CloudWatch metric), chúng tôi điều tra sâu xuống tầng database engine — tức cấu hình của PostgreSQL bên trong Aurora.
Và phát hiện ra vấn đề ở parameter group — bộ cấu hình của PostgreSQL engine. Mặc định nó được tune cho workload OLTP thông thường (nhiều transaction nhỏ), chứ không cho bulk write khối lượng lớn:
- Bài toán migration yêu cầu write throughput cao (bulk INSERT 400GB data)
max_wal_sizequá nhỏ → database cứ phải dừng lại "dọn dẹp" (checkpoint) liên tục để đẩy dữ liệu xuống ổ đĩa, khiến việc ghi bị khựng theo từng nhịp- Index vẫn bật → mỗi dòng ghi vào phải cập nhật lại index.
👉Tổng lại: Aurora ghi không kịp tốc độ DMS đẩy data vào
👉Giải pháp: Tune cho bulk write:
- Tăng
max_wal_size - Drop secondary indexes, sẽ create lại index sau khi migration thành công.
1.4. Kết quả cuối cùng
Thời gian migration giảm từ 16 giờ xuống còn 4 giờ — nhanh gấp 4 lần.
Điều bất ngờ nhất: chi phí không hề tăng, thậm chí còn giảm. Vì chúng tôi không scale up gì cả — chỉ đổi đúng instance family và tune đúng parameter. Và instance memory-optimized lại rẻ hơn dòng compute-optimized cùng size.
2. Tính trước thay vì debug sau
Cả case study trên thực ra có thể tránh được hoàn toàn—nếu ngay từ đầu ngồi lại hỏi đúng câu, thay vì cứ chọn instance "to" rồi debug sau.
Quy trình chọn đúng gồm 3 bước: hiểu bài toán → suy ra loại resource cần → chọn service/instance khớp.
2.1. Làm rõ bài toán thật sự cần gì
Trước khi mở bảng giá AWS, trả lời mấy câu này:
- Bài toán chủ yếu làm gì? Tính toán nặng, hay chỉ di chuyển/lưu trữ dữ liệu?
- Khối lượng dữ liệu bao nhiêu? Có cần ôm nhiều data trong RAM cùng lúc không?
- Đọc nhiều hay ghi nhiều? Burst từng đợt hay đều đặn?
- Bao nhiêu client/request đồng thời? App có scale ra nhiều instance không?
2.2. Suy ra loại resource cần
Từ đặc tính bài toán → map ra resource quyết định:
| Bài toán | Resource cần ưu tiên |
|---|---|
| Tính toán nặng (encode, ML inference) | CPU → compute-optimized (C-series) |
| Ôm data lớn trong RAM (buffer, cache, migrate khối lượng lớn) | Memory → memory-optimized (R-series) |
| Ghi/đọc đĩa dồn dập (bulk insert, batch) | Storage IOPS/throughput → io2, gp3 provisioned |
| Nhiều connection/request đồng thời | Quota/connection → tăng quota, connection pool |
2.3. Chọn service & instance khớp — và kiểm tra giới hạn
Có loại resource rồi, chọn đúng dòng instance/service. Nhưng đừng quên: nhiều giới hạn tính được trước.
Ví dụ rõ nhất là số connection của RDS — nó bị giới hạn theo RAM của instance, công thức xấp xỉ:
max_connections ≈ DBInstanceClassMemory / 12.5MB
Nghĩa là db.r5.large (16GB RAM) chịu được khoảng ~1,300 connection.
3. Mở rộng thêm: Cách detect bottleneck hiệu quả
3.1. Tìm resource "đầy" trong khi resource khác "rảnh"
Pattern nhận biết bottleneck:
CPU: 20% ← rảnh
Memory: 95% ← BOTTLENECK
Disk I/O: 40%
Network: 30%
Nếu một resource gần 100% trong khi các resource khác thấp → đó chính là bottleneck. Scale up instance không giúp gì nếu scale sai chiều.
3.2. Quan sát đúng metrics — không chỉ CPU
| Layer | Metrics cần theo dõi |
|---|---|
| Compute | CPUUtilization, CPUCreditBalance |
| Memory | FreeableMemory, SwapUsage |
| Storage | ReadIOPS, WriteIOPS, ReadLatency, WriteLatency, DiskQueueDepth |
| Network | NetworkIn, NetworkOut, NetworkBandwidthIn/Out |
SwapUsage tăng = dấu hiệu rõ ràng nhất của memory bottleneck. Đây là metric hay bị bỏ qua.3.3. Khi mọi resource đều rảnh mà vẫn chậm
Đây là trường hợp khó nhất.
Đôi khi CPU, memory, I/O, network đều thấp nhưng hệ thống vẫn chậm — vấn đề là đang chờ, chứ không phải đang thiếu sức. Hai khả năng phổ biến nhất:
- Đang chờ nhau (lock): một request giữ khóa dữ liệu, các request khác phải xếp hàng chờ. Resource rảnh nhưng mọi thứ đứng yên.
Ví dụ: 2 transaction (txn) cùng update một dòng trong bảng. txn A khóa dòng đó, txn B phải đợi A xong mới tới lượt — dù CPU/RAM còn dư đầy. Dùng RDS Performance Insights để xem database đang chờ ở đâu. - Đụng giới hạn ẩn (quota): không phải thiếu resource, mà là chạm trần do AWS đặt sẵn.
Ví dụ: API Gateway mặc định chặn ở 10,000 request/giây. Có đợt sale, traffic vọt lên 12,000 request/giây → 2,000 cái bị trả về lỗi429 Too Many Requests, dù backend phía sau (EC2, database) vẫn còn dư sức xử lý.
3.4. Sử dụng AWS tools
- RDS Performance Insights — vũ khí số 1 khi resource trông rảnh. Xem database đang wait ở đâu (CPU ? I/O? Lock:*? IO:XactSync?), query nào gây ra
- CloudWatch Dashboards — tổng hợp tất cả metrics trên cùng timeline để thấy tương quan
- AWS X-Ray — trace request path, tìm service nào chậm nhất
4. Kết luận
Quay lại câu hỏi đầu bài: tại sao tăng instance gấp đôi mà performance gần như không đổi?
Vì "to hơn" không đồng nghĩa với "đúng hơn". Một bài toán memory-bound thì thêm CPU vô ích. Một bài toán nghẽn ở quota thì thêm RAM cũng vô ích. Scale up chỉ giúp khi bạn scale đúng cái đang thiếu — mà muốn biết cái gì đang thiếu thì phải nhìn đúng metric và hiểu đúng workload.
Ba điều rút ra từ cả bài:
- Đừng chỉ nhìn CPU. Mỗi loại bottleneck có metric "nói thật" riêng —
SwapUsage,WriteLatency,DatabaseConnections,Throttles. CPU thấp không có nghĩa là không có vấn đề. - Hiểu bài toán trước khi chọn service. Hỏi "workload này cần loại resource nào?" trước khi mở bảng giá — đừng mặc định "instance to là nhanh".
- Bottleneck luôn dịch chuyển. Sửa được điểm nghẽn này, điểm nghẽn tiếp theo sẽ lộ ra. Đó là chuyện bình thường — quan trọng là mỗi lần đều chẩn đoán đúng chỗ.
Và như case study đã cho thấy: chọn đúng không chỉ nhanh hơn — nó còn rẻ hơn.






