

Mở đầu
Chào mọi người, mình là TKB. Chào mừng mọi người quay trở lại blog của Vietnam Lab Center.
Trong thời đại công nghệ thông tin phát triển vượt bậc, trí tuệ nhân tạo (AI) đang ngày càng trở thành công cụ quan trọng trong nhiều lĩnh vực, đặc biệt là xử lý ngôn ngữ tự nhiên (NLP). Một trong những bước đột phá đáng chú ý gần đây là mô hình RAG (Retrieval-Augmented Generation), kết hợp giữa việc truy xuất thông tin và sinh ngôn ngữ tự nhiên. RAG không chỉ giúp cải thiện độ chính xác của các hệ thống hỏi đáp mà còn tạo ra những nội dung phong phú hơn dựa trên thông tin có sẵn. Vậy RAG hoạt động như thế nào và tại sao nó lại mang đến những ứng dụng tiềm năng vượt trội trong lĩnh vực AI? Hãy cùng khám phá qua bài viết này!
Kết luận
Theo tinh thần Vietnam Lab Center mình xin đưa ra một số điểm đáng chú ý như sau:
- RAG là một phương pháp mạnh mẽ để nâng cao khả năng của mô hình ngôn ngữ bằng cách kết hợp với tri thức bên ngoài.
- Mang lại nhiều lợi ích như phản hồi chính xác hơn, khả năng giải thích tốt hơn và giảm thiểu “ảo giác” do tập dữ liệu không đầy đủ khi traning model LLM.
- Khi nghiên cứu, xây dựng các ứng dụng RAG thì LangChain là một công cụ rất hữu ích để nghiên cứu, kiểm thử. Trong bài viết có sample code rất đơn giản và nhanh chóng để hiểu và thử nghiệm
Giới thiệu
Mô hình ngôn ngữ lớn (LLM) như GPT-4, Gemini… có khả năng tạo văn bản ấn tượng. Tuy nhiên, LLM bị giới hạn bởi kiến thức được huấn luyện. Khi cần hỏi thông tin nội bộ, hoặc từ bộ tư liệu mong muốn thì sẽ khó đáp ứng được.
Retrieval Augmented Generation (RAG) kết hợp LLM với nguồn tri thức bên ngoài để tạo ra phản hồi chính xác và cập nhật hơn.
Retrieval Augmented Generation: tạm dịch có thể hiểu là tạo văn bản tăng cường truy xuất, là một kiến trúc trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) kết hợp sức mạnh của hai công nghệ chính:
- Mô hình ngôn ngữ lớn (LLM): Như GPT-4, llama, với khả năng tạo văn bản mạch lạc, trôi chảy và giống con người.
- Truy xuất thông tin (Information Retrieval): Kỹ thuật tìm kiếm và lọc thông tin liên quan từ kho dữ liệu lớn, dựa trên truy vấn của người dùng.
Kiến trúc của RAG
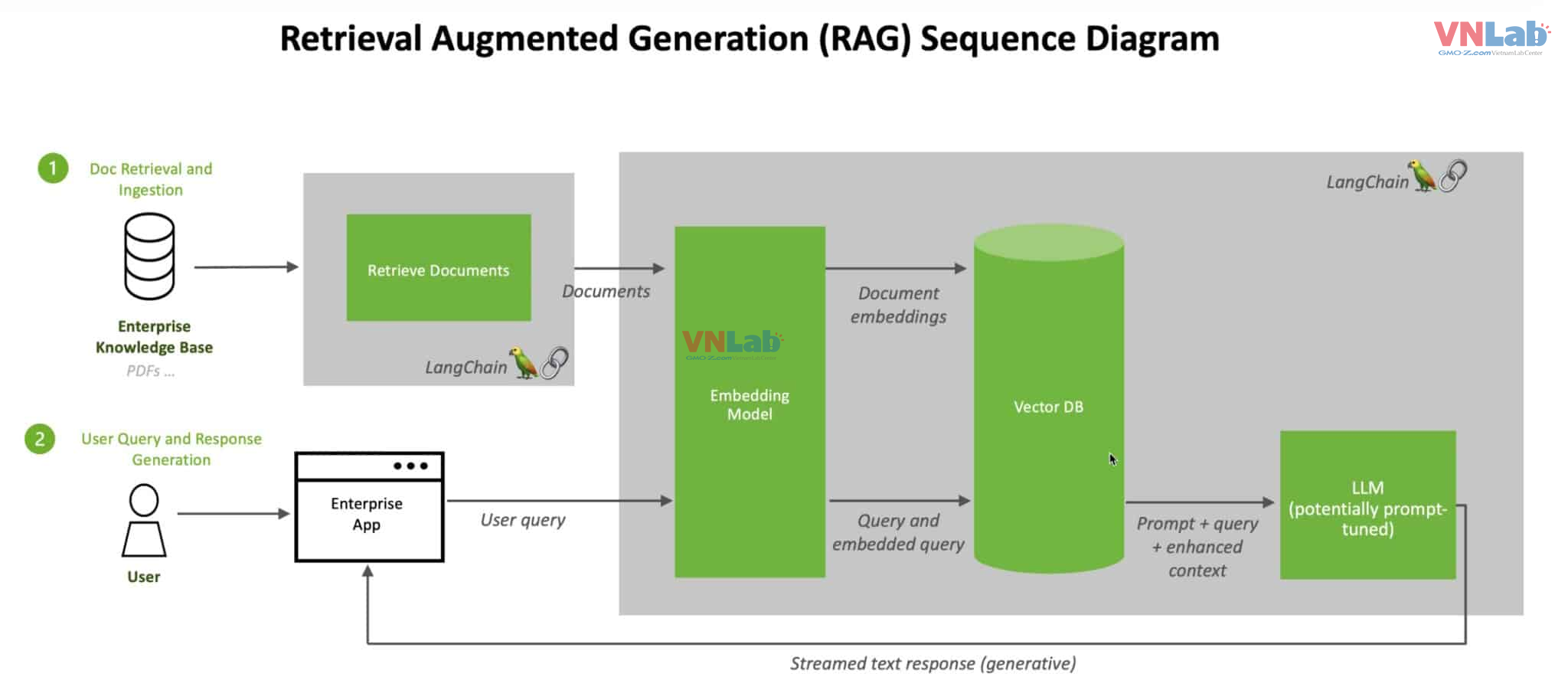
Dữ liệu của phần truy xuất thông tin sẽ được lưu dưới dạng cơ sở dữ liệu vector (vector DB)
Khi một người dùng (user) gửi tới app một câu hỏi(User query) thì câu hỏi đó cũng được vector hóa. Dựa trên nội dung câu hỏi đó, hệ thống RAG truy xuất các mảnh dữ liệu có liên quan trong vector DB. Từ đó gửi đính kém dữ liệu đó và câu hỏi tới cho LLM (trong thử nghiệm này là ChatGPT 4.o). Sau đó LLM sẽ phản hôi về cho người dùng câu trả lời.
Giai đoạn truy xuất (Retrieval)
Nhận đầu vào của người dùng và truy vấn nguồn tri thức bên ngoài (ví dụ: Wikipedia, cơ sở dữ liệu, vector store) để tìm kiếm thông tin liên quan.
Giai đoạn tạo (Generation)
Sử dụng thông tin được truy xuất cùng + đầu vào của người dùng gửi tới LLM => tạo ra phản hồi cuối cùng.
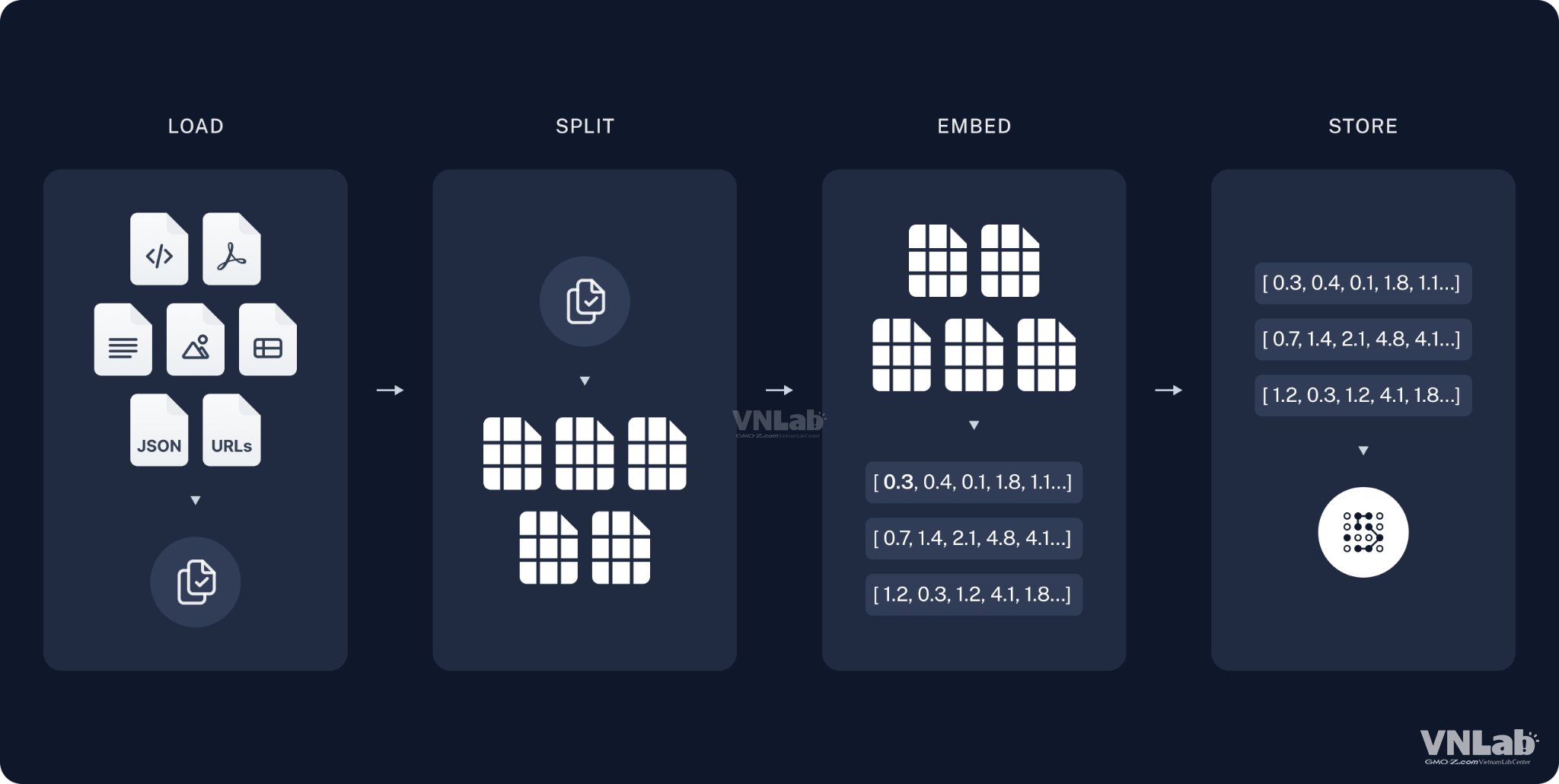
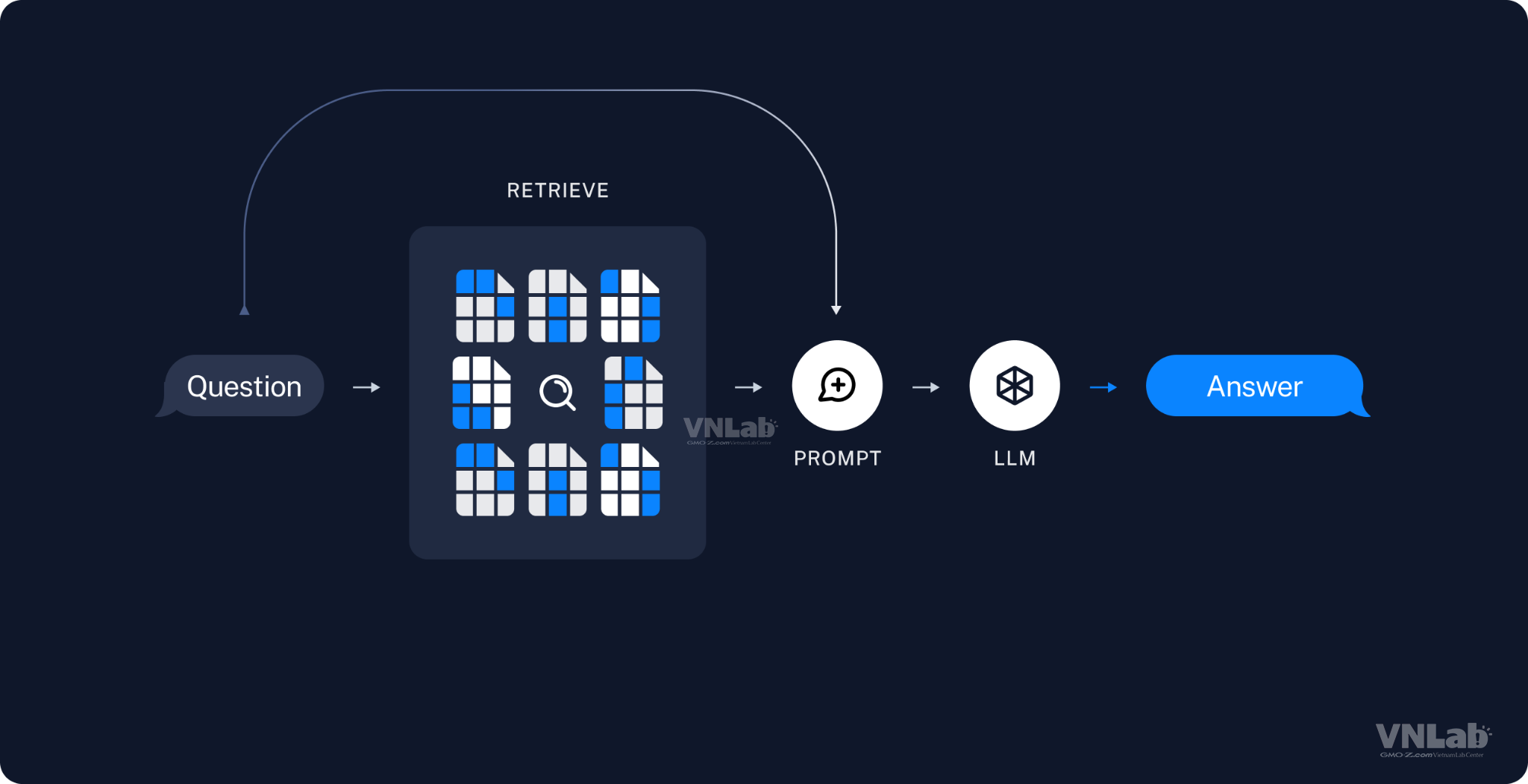
RAG sử dụng các kỹ thuật tìm kiếm thông tin như TF-IDF, BM25, hoặc embeddings để tìm kiếm thông tin liên quan.
Mô hình ngôn ngữ được sử dụng trong giai đoạn tạo có thể là mô hình seq2seq hoặc encoder-decoder.
Ưu điểm của RAG
Phản hồi chính xác và cập nhật hơn: Truy cập vào nguồn tri thức bên ngoài cung cấp thông tin mới nhất(hoặc private) cho mô hình.
Khả năng giải thích tốt hơn: RAG có thể cung cấp nguồn gốc thông tin cho phản hồi của nó.
Giảm thiểu “ảo giác”: Giảm khả năng tạo ra thông tin sai lệch bằng cách dựa vào nguồn tri thức đáng tin cậy.
Khả năng thích ứng cao: Dễ dàng cập nhật và mở rộng với các nguồn tri thức mới.
Nhược điểm của RAG
Phức tạp hơn trong triển khai: Yêu cầu tích hợp với hệ thống truy xuất thông tin.
Tốn kém hơn về tài nguyên: Cần lưu trữ và truy vấn nguồn tri thức lớn. Ví dụ: cần tạo dữ liệu, nơi lưu trữ dữ liệu, gửi lượng lớn token lên LLM.
Vẫn có thể gặp lỗi: Chất lượng phản hồi phụ thuộc vào chất lượng nguồn tri thức, chất lượng model.
Một ví dụ đơn giản về cách thức hoạt động của RAG: Hỏi đáp dựa trên Wikipedia
Câu hỏi: “Ai là người phát minh ra bóng đèn?”
=> Người dùng: Ai là người phát minh ra bóng đèn?
=> RAG: (Truy vấn Wikipedia về "bóng đèn")
=> Wikipedia: Thomas Edison được coi là người phát minh ra bóng đèn incandescent thực tế đầu tiên...
=> RAG: Thomas Edison được coi là người phát minh ra bóng đèn incandescent thực tế đầu tiên.
RAG trong thực tế
- Hỗ trợ khách hàng: Cung cấp câu trả lời chính xác và phù hợp dựa trên cơ sở kiến thức nội bộ.
- Tìm kiếm: Cải thiện kết quả tìm kiếm bằng cách hiểu ngữ cảnh và truy xuất thông tin liên quan.
- Giáo dục: Tạo ra các câu hỏi và bài tập được cá nhân hóa dựa trên tiến độ học tập của học sinh.
- Y tế: Hỗ trợ bác sĩ chẩn đoán và đưa ra phác đồ điều trị dựa trên hồ sơ bệnh án và tài liệu y khoa.
- Luật: Tự động hóa các nhiệm vụ pháp lý như nghiên cứu án lệ và soạn thảo tài liệu.
- Dịch thuật: Cải thiện chất lượng dịch bằng cách truy xuất thông tin ngữ cảnh từ kho ngữ liệu song ngữ.
- Truyền thông: Tạo ra nội dung được cá nhân hóa và phù hợp với sở thích của người dùng.
- Thương mại điện tử: Cung cấp trải nghiệm mua sắm được cá nhân hóa và hỗ trợ khách hàng tốt hơn.
LangChain: Thư viện Python cho RAG
- LangChain là một thư viện mã nguồn mở giúp dễ dàng xây dựng các ứng dụng RAG.
- Cung cấp các thành phần cần thiết để truy xuất, xử lý và tạo văn bản.
- Hỗ trợ nhiều nguồn tri thức khác nhau như Wikipedia, Google Search, Elasticsearch.
Ví dụ về LangChain: RetrievalQA Chain
RetrievalQA là một chain trong LangChain được thiết kế cho các tác vụ hỏi đáp dựa trên nguồn tri thức bên ngoài.
Nhận đầu vào là câu hỏi và trả lời câu hỏi bằng cách tìm kiếm thông tin liên quan từ nguồn tri thức đã cho.
Cài đặt LangChain
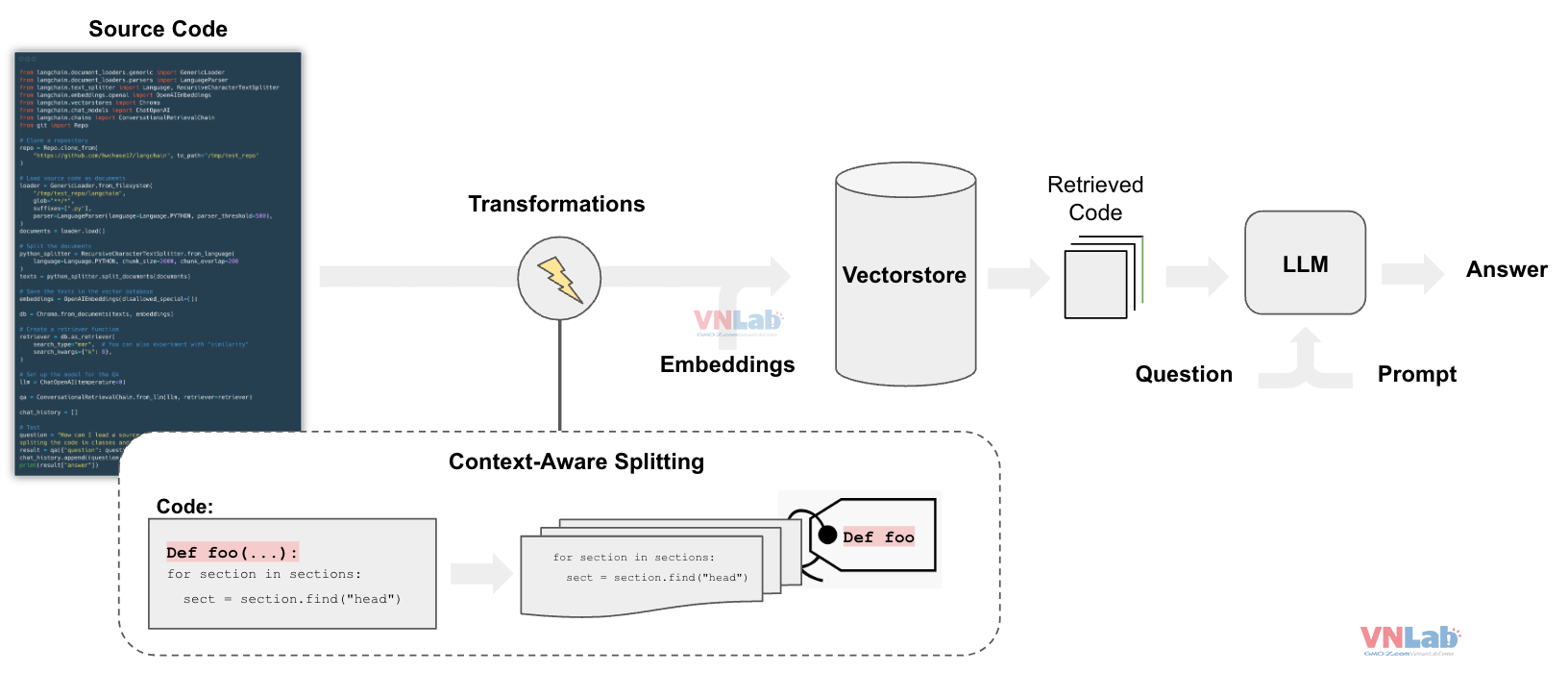
Code sample cho jupyter playbook
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.document_loaders import TextLoader
from langchain.indexes import VectorstoreIndexCreator
# Tải dữ liệu
loader = TextLoader('state_of_the_union.txt') // hoặc loader = CSVLoader(file_path='gmo.csv')
documents = loader.load()
# Tạo index
index = VectorstoreIndexCreator().from_loaders([loader])
# Khởi tạo RetrievalQA chain
qa = RetrievalQA.from_chain_type(
llm=OpenAI(), chain_type="stuff", retriever=index.retriever
)
# Đặt câu hỏi
query = "What did the president say about Ketanji Brown Jackson?"
result = qa({"query": query})
print(result['result'])
Đoạn mã này tải nội dung từ file state_of_the_union.txt hoặc gmo.csv
Tạo index cho nó và sau đó sử dụng chain RetrievalQA để trả lời câu hỏi dựa trên thông tin trong file.
Hoàn toàn có thể thay đổi file state_of_the_union.txt, gmo.csv bằng nguồn dữ liệu khác, định dạng khác và đặt câu hỏi khác nhau để thử nghiệm.
Hướng phát triển tương lai
Do công nghệ còn mới nên cũng có rất nhiều điểm cần cải thiện và nâng cao khả năng mở rộng của RAG.
- Tối ưu hóa kiến trúc RAG: nhẹ hơn, tốn ít tài nguyên hơn, thông minh hơn
- Học cách truy xuất linh hoạt: mô hình có thể tự động lựa chọn nguồn tri thức phù hợp nhất cho mỗi truy vấn và kết hợp thông tin từ nhiều nguồn.
- Kiểm soát thông tin: giới hạn truy cập dự theo tài khoản người dùng
- Cá nhân hóa trải nghiệm: học tập, giáo dục, giải trí, y tế
- Giải thích lý do: phát triển các phương pháp cho phép RAG giải thích lý do đằng sau mỗi phản hồi và cung cấp bằng chứng từ nguồn tri thức được sử dụng.
- Nghiên cứu các ứng dụng mới của RAG trong các lĩnh vực khác nhau.
- Tăng cường tính bảo mật thông tin bằng cách tự build và run LLM trên môi trường nội bộ
Tổng kết
- RAG là một lĩnh vực đầy hứa hẹn trong lĩnh vực xử lý ngôn ngữ tự nhiên và trí tuệ nhân tạo.
- Sự kết hợp giữa khả năng sáng tạo của mô hình ngôn ngữ (LLM) và dữ liệu người dùng cung cấp mở ra nhiều tiềm năng to lớn. Như: hỏi đáp về thuế, luật, nội quy công ty…
Tài liệu tham khảo
- LangChain Documentation
- https://cloud.google.com/use-cases/retrieval-augmented-generation?hl=vi
- https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
- https://tenbin.ai/
- https://recruit.gmo.jp/engineer/jisedai/blog/qa_tools_with_retrievalqa_and_chatgpt/
- https://python.langchain.com/v0.2/docs/how_to/parent_document_retriever






