
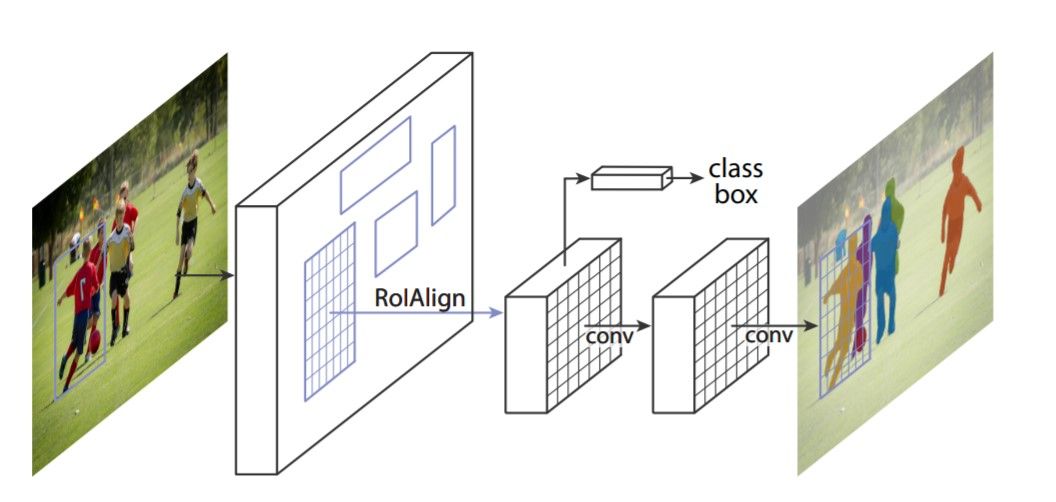
Computer Vision là một trong những đề tài nghiên cứu rất phát triển trong những năm gần đây. Cùng với sự ra đời của Convolution Neural Networks (CNN), các mô hình State-Of-The-Art (SOTA) trong các bài toán classification, object detection, image segmentation,... liên tục ra đời. Trong bài viết này, ta sẽ cùng tìm hiểu về 1 bài toán trong Computer Vision là Image Segmentation.
Image Segmentation là gì
Image Segmentation (phân đoạn ảnh) là lớp bài toán thuộc về Computer Vision trong đó hình ảnh được chia thành nhiều vùng khác nhau, trong đó từng pixel trên ảnh được phân loại thành các nhãn khác nhau. Ví dụ, trong bức ảnh dưới đây, thì các pixel nằm trên giường được đánh nhãn "giường", các pixel nằm trên tường được đánh nhãn "tường"...

Image Segmentation có 2 loại chính là:
- Semantic Segmentation
- Instance Segmentation
Trong Semantic Segmentation, các pixel thuộc cùng 1 class sẽ được gán nhãn giống nhau, còn với Instance Segmentation thì các pixel thuộc cùng 1 vật thể được gán nhãn giống nhau.

Thực hiện Image Segmentation trên Python
Môi trường & dữ liệu
Code python trong bài này sử dụng Tensorflow 2 cùng bộ dữ liệu ảnh 2D ADE20K.
Chuẩn bị môi trường
from glob import glob
import shutil
import argparse
import zipfile
import hashlib
import requests
from tqdm import tqdm
import IPython.display as display
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import datetime, os
from tensorflow.keras.layers import *
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras.optimizers import Adam
from IPython.display import clear_output
import tensorflow_addons as tfa
# For more information about autotune:
# https://www.tensorflow.org/guide/data_performance#prefetching
AUTOTUNE = tf.data.experimental.AUTOTUNE
print(f"Tensorflow ver. {tf.__version__}")
# important for reproducibility
# this allows to generate the same random numbers
SEED = 42
Tensorflow ver. 2.2.0-rc3
Tải bộ dữ liệu
from google.colab import drive
drive.mount('data')
# some helper functions to download the dataset
# this code comes mainly from gluoncv.utils
def check_sha1(filename, sha1_hash):
"""Check whether the sha1 hash of the file content matches the expected hash.
Parameters
----------
filename : str
Path to the file.
sha1_hash : str
Expected sha1 hash in hexadecimal digits.
Returns
-------
bool
Whether the file content matches the expected hash.
"""
sha1 = hashlib.sha1()
with open(filename, 'rb') as f:
while True:
data = f.read(1048576)
if not data:
break
sha1.update(data)
sha1_file = sha1.hexdigest()
l = min(len(sha1_file), len(sha1_hash))
return sha1.hexdigest()[0:l] == sha1_hash[0:l]
def download(url, path=None, overwrite=False, sha1_hash=None):
"""Download an given URL
Parameters
----------
url : str
URL to download
path : str, optional
Destination path to store downloaded file. By default stores to the
current directory with same name as in url.
overwrite : bool, optional
Whether to overwrite destination file if already exists.
sha1_hash : str, optional
Expected sha1 hash in hexadecimal digits. Will ignore existing file when hash is specified
but doesn't match.
Returns
-------
str
The file path of the downloaded file.
"""
if path is None:
fname = url.split('/')[-1]
else:
path = os.path.expanduser(path)
if os.path.isdir(path):
fname = os.path.join(path, url.split('/')[-1])
else:
fname = path
if overwrite or not os.path.exists(fname) or (sha1_hash and not check_sha1(fname, sha1_hash)):
dirname = os.path.dirname(os.path.abspath(os.path.expanduser(fname)))
if not os.path.exists(dirname):
os.makedirs(dirname)
print('Downloading %s from %s...'%(fname, url))
r = requests.get(url, stream=True)
if r.status_code != 200:
raise RuntimeError("Failed downloading url %s"%url)
total_length = r.headers.get('content-length')
with open(fname, 'wb') as f:
if total_length is None: # no content length header
for chunk in r.iter_content(chunk_size=1024):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
else:
total_length = int(total_length)
for chunk in tqdm(r.iter_content(chunk_size=1024),
total=int(total_length / 1024. + 0.5),
unit='KB', unit_scale=False, dynamic_ncols=True):
f.write(chunk)
if sha1_hash and not check_sha1(fname, sha1_hash):
raise UserWarning('File {} is downloaded but the content hash does not match. ' \
'The repo may be outdated or download may be incomplete. ' \
'If the "repo_url" is overridden, consider switching to ' \
'the default repo.'.format(fname))
return fname
def download_ade(path, overwrite=False):
"""Download ADE20K
Parameters
----------
path : str
Location of the downloaded files.
overwrite : bool, optional
Whether to overwrite destination file if already exists.
"""
if not os.path.exists(path):
os.mkdir(path)
_AUG_DOWNLOAD_URLS = [
('http://data.csail.mit.edu/places/ADEchallenge/ADEChallengeData2016.zip', '219e1696abb36c8ba3a3afe7fb2f4b4606a897c7'),
('http://data.csail.mit.edu/places/ADEchallenge/release_test.zip', 'e05747892219d10e9243933371a497e905a4860c'),]
download_dir = os.path.join(path, 'downloads')
if not os.path.exists(download_dir):
os.mkdir(download_dir)
for url, checksum in _AUG_DOWNLOAD_URLS:
filename = download(url, path=download_dir, overwrite=overwrite, sha1_hash=checksum)
# extract
with zipfile.ZipFile(filename,"r") as zip_ref:
zip_ref.extractall(path=path)
root = "/content/"
dataset_path = root + "ADEChallengeData2016/images/"
training_data = "training/"
val_data = "validation/"
download_ade(root, overwrite=False)
Tạo dataloader
# Image size that we are going to use
IMG_SIZE = 128
# Our images are RGB (3 channels)
N_CHANNELS = 3
# Scene Parsing has 150 classes + `not labeled`
N_CLASSES = 151
TRAINSET_SIZE = len(glob(dataset_path + training_data + "*.jpg"))
print(f"The Training Dataset contains {TRAINSET_SIZE} images.")
VALSET_SIZE = len(glob(dataset_path + val_data + "*.jpg"))
print(f"The Validation Dataset contains {VALSET_SIZE} images.")
The Training Dataset contains 20210 images.
The Validation Dataset contains 2000 images.
def parse_image(img_path: str) -> dict:
"""Load an image and its annotation (mask) and returning
a dictionary.
Parameters
----------
img_path : str
Image (not the mask) location.
Returns
-------
dict
Dictionary mapping an image and its annotation.
"""
image = tf.io.read_file(img_path)
image = tf.image.decode_jpeg(image, channels=3)
image = tf.image.convert_image_dtype(image, tf.uint8)
# For one Image path:
# .../trainset/images/training/ADE_train_00000001.jpg
# Its corresponding annotation path is:
# .../trainset/annotations/training/ADE_train_00000001.png
mask_path = tf.strings.regex_replace(img_path, "images", "annotations")
mask_path = tf.strings.regex_replace(mask_path, "jpg", "png")
mask = tf.io.read_file(mask_path)
# The masks contain a class index for each pixels
mask = tf.image.decode_png(mask, channels=1)
# In scene parsing, "not labeled" = 255
# But it will mess up with our N_CLASS = 150
# Since 255 means the 255th class
# Which doesn't exist
mask = tf.where(mask == 255, np.dtype('uint8').type(0), mask)
# Note that we have to convert the new value (0)
# With the same dtype than the tensor itself
return {'image': image, 'segmentation_mask': mask}
train_dataset = tf.data.Dataset.list_files(dataset_path + training_data + "*.jpg", seed=SEED)
train_dataset = train_dataset.map(parse_image)
val_dataset = tf.data.Dataset.list_files(dataset_path + val_data + "*.jpg", seed=SEED)
val_dataset =val_dataset.map(parse_image)
Biến đổi dữ liệu
# Here we are using the decorator @tf.function
# if you want to know more about it:
# https://www.tensorflow.org/api_docs/python/tf/function
@tf.function
def normalize(input_image: tf.Tensor, input_mask: tf.Tensor) -> tuple:
"""Rescale the pixel values of the images between 0.0 and 1.0
compared to [0,255] originally.
Parameters
----------
input_image : tf.Tensor
Tensorflow tensor containing an image of size [SIZE,SIZE,3].
input_mask : tf.Tensor
Tensorflow tensor containing an annotation of size [SIZE,SIZE,1].
Returns
-------
tuple
Normalized image and its annotation.
"""
input_image = tf.cast(input_image, tf.float32) / 255.0
return input_image, input_mask
@tf.function
def load_image_train(datapoint: dict) -> tuple:
"""Apply some transformations to an input dictionary
containing a train image and its annotation.
Notes
-----
An annotation is a regular channel image.
If a transformation such as rotation is applied to the image,
the same transformation has to be applied on the annotation also.
Parameters
----------
datapoint : dict
A dict containing an image and its annotation.
Returns
-------
tuple
A modified image and its annotation.
"""
input_image = tf.image.resize(datapoint['image'], (IMG_SIZE, IMG_SIZE))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (IMG_SIZE, IMG_SIZE))
if tf.random.uniform(()) > 0.5:
input_image = tf.image.flip_left_right(input_image)
input_mask = tf.image.flip_left_right(input_mask)
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
@tf.function
def load_image_test(datapoint: dict) -> tuple:
"""Normalize and resize a test image and its annotation.
Notes
-----
Since this is for the test set, we don't need to apply
any data augmentation technique.
Parameters
----------
datapoint : dict
A dict containing an image and its annotation.
Returns
-------
tuple
A modified image and its annotation.
"""
input_image = tf.image.resize(datapoint['image'], (IMG_SIZE, IMG_SIZE))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (IMG_SIZE, IMG_SIZE))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
BATCH_SIZE = 5
# for reference about the BUFFER_SIZE in shuffle:
# https://stackoverflow.com/questions/46444018/meaning-of-buffer-size-in-dataset-map-dataset-prefetch-and-dataset-shuffle
BUFFER_SIZE = 1000
dataset = {"train": train_dataset, "val": val_dataset}
# -- Train Dataset --#
dataset['train'] = dataset['train'].map(load_image_train, num_parallel_calls=tf.data.experimental.AUTOTUNE)
dataset['train'] = dataset['train'].shuffle(buffer_size=BUFFER_SIZE, seed=SEED)
dataset['train'] = dataset['train'].repeat()
dataset['train'] = dataset['train'].batch(BATCH_SIZE)
dataset['train'] = dataset['train'].prefetch(buffer_size=AUTOTUNE)
#-- Validation Dataset --#
dataset['val'] = dataset['val'].map(load_image_test)
dataset['val'] = dataset['val'].repeat()
dataset['val'] = dataset['val'].batch(BATCH_SIZE)
dataset['val'] = dataset['val'].prefetch(buffer_size=AUTOTUNE)
print(dataset['train'])
print(dataset['val'])
Visualize dữ liệu
def display_sample(display_list):
"""Show side-by-side an input image,
the ground truth and the prediction.
"""
plt.figure(figsize=(18, 18))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.preprocessing.image.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for image, mask in dataset['train'].take(1):
sample_image, sample_mask = image, mask
display_sample([sample_image[0], sample_mask[0]])
Viết model Unet bằng Keras API
# -- Keras Functional API -- #
# -- UNet Implementation -- #
# Everything here is from tensorflow.keras.layers
# I imported tensorflow.keras.layers * to make it easier to read
dropout_rate = 0.5
input_size = (IMG_SIZE, IMG_SIZE, N_CHANNELS)
# If you want to know more about why we are using `he_normal`:
# https://stats.stackexchange.com/questions/319323/whats-the-difference-between-variance-scaling-initializer-and-xavier-initialize/319849#319849
# Or the excelent fastai course:
# https://github.com/fastai/course-v3/blob/master/nbs/dl2/02b_initializing.ipynb
initializer = 'he_normal'
# -- Encoder -- #
# Block encoder 1
inputs = Input(shape=input_size)
conv_enc_1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer=initializer)(inputs)
conv_enc_1 = Conv2D(64, 3, activation = 'relu', padding='same', kernel_initializer=initializer)(conv_enc_1)
# Block encoder 2
max_pool_enc_2 = MaxPooling2D(pool_size=(2, 2))(conv_enc_1)
conv_enc_2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(max_pool_enc_2)
conv_enc_2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_enc_2)
# Block encoder 3
max_pool_enc_3 = MaxPooling2D(pool_size=(2, 2))(conv_enc_2)
conv_enc_3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(max_pool_enc_3)
conv_enc_3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_enc_3)
# Block encoder 4
max_pool_enc_4 = MaxPooling2D(pool_size=(2, 2))(conv_enc_3)
conv_enc_4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(max_pool_enc_4)
conv_enc_4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_enc_4)
# -- Encoder -- #
# ----------- #
maxpool = MaxPooling2D(pool_size=(2, 2))(conv_enc_4)
conv = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(maxpool)
conv = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv)
# ----------- #
# -- Dencoder -- #
# Block decoder 1
up_dec_1 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = initializer)(UpSampling2D(size = (2,2))(conv))
merge_dec_1 = concatenate([conv_enc_4, up_dec_1], axis = 3)
conv_dec_1 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(merge_dec_1)
conv_dec_1 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_dec_1)
# Block decoder 2
up_dec_2 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = initializer)(UpSampling2D(size = (2,2))(conv_dec_1))
merge_dec_2 = concatenate([conv_enc_3, up_dec_2], axis = 3)
conv_dec_2 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(merge_dec_2)
conv_dec_2 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_dec_2)
# Block decoder 3
up_dec_3 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = initializer)(UpSampling2D(size = (2,2))(conv_dec_2))
merge_dec_3 = concatenate([conv_enc_2, up_dec_3], axis = 3)
conv_dec_3 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(merge_dec_3)
conv_dec_3 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_dec_3)
# Block decoder 4
up_dec_4 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = initializer)(UpSampling2D(size = (2,2))(conv_dec_3))
merge_dec_4 = concatenate([conv_enc_1, up_dec_4], axis = 3)
conv_dec_4 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(merge_dec_4)
conv_dec_4 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_dec_4)
conv_dec_4 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = initializer)(conv_dec_4)
# -- Dencoder -- #
output = Conv2D(N_CLASSES, 1, activation = 'softmax')(conv_dec_4)
# Load and compile the model
model = tf.keras.Model(inputs = inputs, outputs = output)
model.compile(optimizer=Adam(learning_rate=0.0001), loss = tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
Kiểm tra tính đúng đắn
def create_mask(pred_mask: tf.Tensor) -> tf.Tensor:
"""Return a filter mask with the top 1 predicitons
only.
Parameters
----------
pred_mask : tf.Tensor
A [IMG_SIZE, IMG_SIZE, N_CLASS] tensor. For each pixel we have
N_CLASS values (vector) which represents the probability of the pixel
being these classes. Example: A pixel with the vector [0.0, 0.0, 1.0]
has been predicted class 2 with a probability of 100%.
Returns
-------
tf.Tensor
A [IMG_SIZE, IMG_SIZE, 1] mask with top 1 predictions
for each pixels.
"""
# pred_mask -> [IMG_SIZE, SIZE, N_CLASS]
# 1 prediction for each class but we want the highest score only
# so we use argmax
pred_mask = tf.argmax(pred_mask, axis=-1)
# pred_mask becomes [IMG_SIZE, IMG_SIZE]
# but matplotlib needs [IMG_SIZE, IMG_SIZE, 1]
pred_mask = tf.expand_dims(pred_mask, axis=-1)
return pred_mask
def show_predictions(dataset=None, num=1):
"""Show a sample prediction.
Parameters
----------
dataset : [type], optional
[Input dataset, by default None
num : int, optional
Number of sample to show, by default 1
"""
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display_sample([image[0], true_mask, create_mask(pred_mask)])
else:
# The model is expecting a tensor of the size
# [BATCH_SIZE, IMG_SIZE, IMG_SIZE, 3]
# but sample_image[0] is [IMG_SIZE, IMG_SIZE, 3]
# and we want only 1 inference to be faster
# so we add an additional dimension [1, IMG_SIZE, IMG_SIZE, 3]
one_img_batch = sample_image[0][tf.newaxis, ...]
# one_img_batch -> [1, IMG_SIZE, IMG_SIZE, 3]
inference = model.predict(one_img_batch)
# inference -> [1, IMG_SIZE, IMG_SIZE, N_CLASS]
pred_mask = create_mask(inference)
# pred_mask -> [1, IMG_SIZE, IMG_SIZE, 1]
display_sample([sample_image[0], sample_mask[0],
pred_mask[0]])
# show predictions
for image, mask in dataset['train'].take(1):
sample_image, sample_mask = image, mask
show_predictions()
Huấn luyện mô hình
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
STEPS_PER_EPOCH = TRAINSET_SIZE // BATCH_SIZE
VALIDATION_STEPS = VALSET_SIZE // BATCH_SIZE
logdir = os.path.join("logs", datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logdir, histogram_freq=1)
callbacks = [
# to show samples after each epoch
DisplayCallback(),
# to collect some useful metrics and visualize them in tensorboard
tensorboard_callback,
# if no accuracy improvements we can stop the training directly
tf.keras.callbacks.EarlyStopping(patience=10, verbose=1),
# to save checkpoints
tf.keras.callbacks.ModelCheckpoint('best_model_unet.h5', verbose=1, save_best_only=True, save_weights_only=True)
]
model = tf.keras.Model(inputs = inputs, outputs = output)
# # here I'm using a new optimizer: https://arxiv.org/abs/1908.03265
optimizer=tfa.optimizers.RectifiedAdam(lr=1e-3)
loss = tf.keras.losses.SparseCategoricalCrossentropy()
model.compile(optimizer=optimizer, loss = loss,
metrics=['accuracy'])
model_history = model.fit(dataset['train'], epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=dataset['val'],
callbacks=callbacks)
Tổng kết
Image Segmentation là một trong những bài toán có nhiều ứng dụng trong thực tế, đồng thời đòi hỏi mức độ chi tiết và chính xác cao hơn nhiều so với các thuật toán khác như Image Classification, Object Detection. Hi vọng qua bài viết này, các bạn có thể hiểu được Image Segmentation về khái niệm, cũng như cách huấn luyện một mô hình Image Segmentation trên Python.






