I. Đặt vấn đề
Trong các tổ chức và doanh nghiệp lớn, việc quản lý và truy xuất các quy định, chính sách và quy trình là một thách thức. Các tài liệu này thường rất dài, khó tìm kiếm và không phải lúc nào nhân viên cũng có thể nắm bắt nhanh chóng những thông tin cần thiết. Vậy làm thế nào để tạo ra một hệ thống hỏi đáp hiệu quả, giúp nhân viên dễ dàng tìm thấy câu trả lời chính xác về quy định mà không cần phải đọc qua hàng trăm trang tài liệu?
2. Giới thiệu
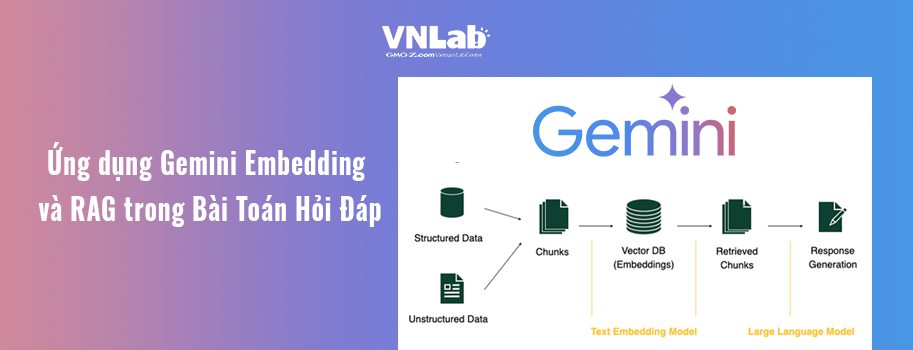
Để giải quyết vấn đề này, công nghệ Embedding và Retrieval-Augmented Generation (RAG) đã nổi lên như một giải pháp hiệu quả. Bằng cách sử dụng Embedding để chuyển văn bản thành các tọa độ số(vector), hệ thống có thể "hiểu" và tìm kiếm thông tin một cách ngữ nghĩa. Đồng thời, RAG kết hợp giữa truy xuất thông tin (retrieval) và sinh văn bản (generation) giúp hệ thống không chỉ trả về kết quả tìm kiếm mà còn có thể giải thích và tạo ra các câu trả lời chi tiết, trực quan.
3. Cách hoạt động của Embedding và RAG
a. Embedding
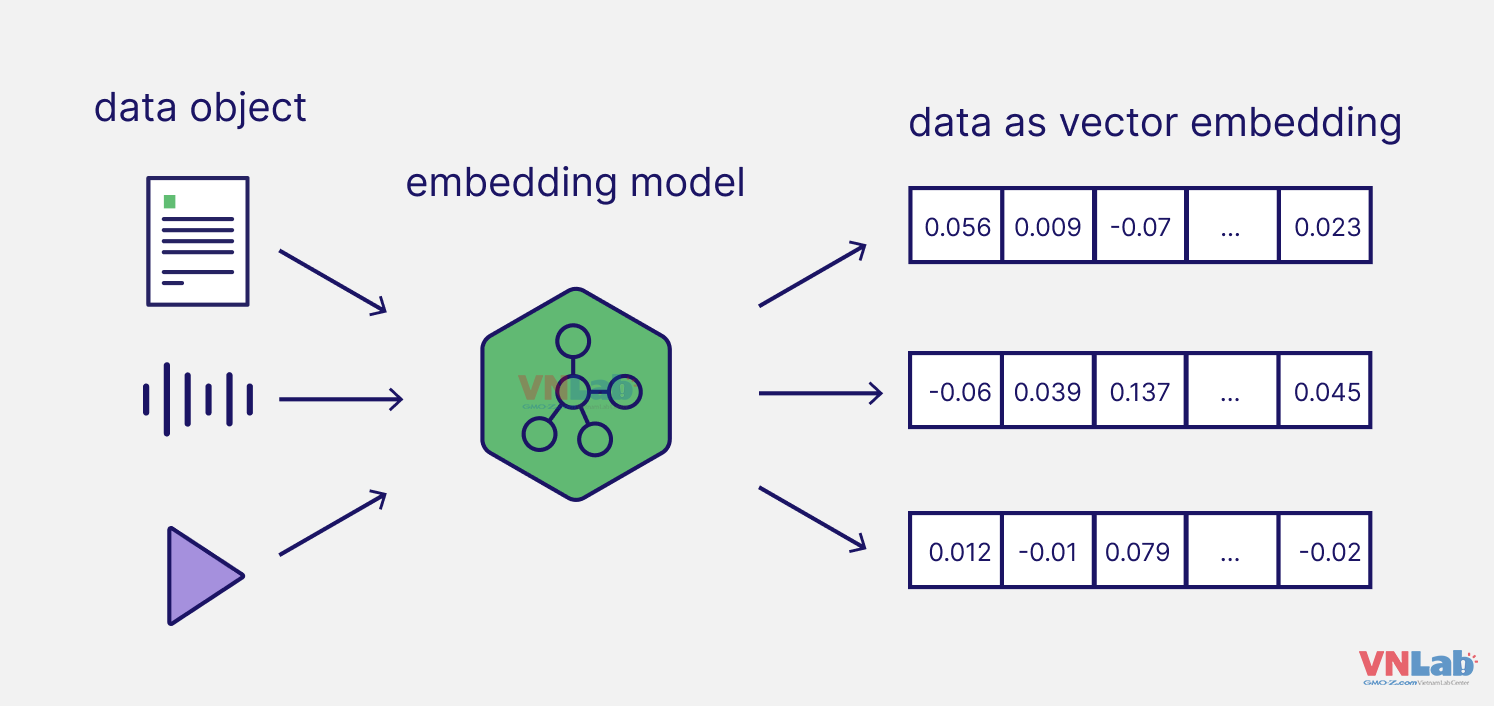
Embedding là một kỹ thuật xử lý ngôn ngữ tự nhiên (NLP) chuyển đổi văn bản thành các vector trong không gian n-chiều. Mỗi từ, cụm từ hoặc câu sẽ được biểu diễn dưới dạng một vector số, cho phép chúng ta so sánh các đoạn văn bản với nhau dựa trên ngữ nghĩa. Ví dụ, câu "Tôi đưa chó đến bác sĩ thú y" và "Tôi đưa mèo đến bác sĩ thú y" sẽ có vector gần nhau trong không gian vector vì ngữ cảnh của chúng tương tự nhau.
b. RAG (Retrieval-Augmented Generation)
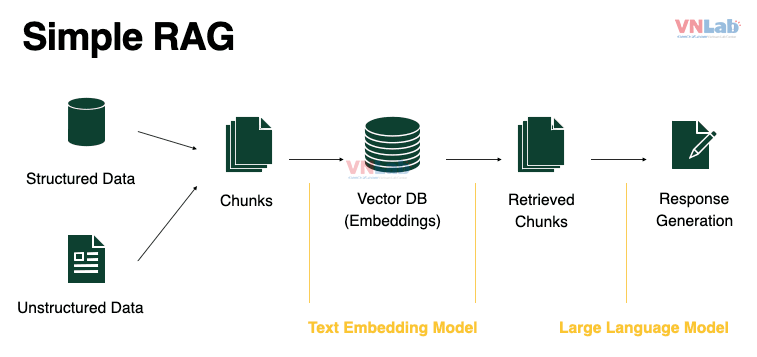
RAG là sự kết hợp giữa truy xuất thông tin và mô hình ngôn ngữ sinh. Hệ thống này trước tiên sẽ truy xuất các tài liệu liên quan từ cơ sở dữ liệu dựa trên câu hỏi của người dùng, sau đó sử dụng mô hình sinh để tạo ra câu trả lời chi tiết dựa trên tài liệu đã truy xuất. Điều này giúp tối ưu hóa cả tính chính xác lẫn khả năng diễn giải của hệ thống hỏi đáp.
4. Các tính năng của Embedding và RAG
a. Tìm kiếm ngữ nghĩa
Thông qua Embedding, hệ thống có thể tìm kiếm dựa trên ý nghĩa của câu hỏi, không chỉ dựa trên từ khóa. Điều này giúp tìm ra các quy định hoặc thông tin liên quan ngay cả khi câu hỏi của nhân viên không trùng khớp hoàn toàn với nội dung văn bản.
b. Phân loại và nhóm nội dung
Embedding còn có thể được dùng để phân loại và nhóm các văn bản liên quan với nhau. Ví dụ, các quy định về phúc lợi, bảo hiểm, và chế độ nghỉ phép có thể được nhóm lại thành một cụm giúp người dùng dễ dàng tìm kiếm theo chủ đề.
c. Truy xuất và sinh câu trả lời
RAG giúp hệ thống không chỉ trả về kết quả tìm kiếm mà còn có khả năng tự động tạo ra câu trả lời hoàn chỉnh. Hệ thống sẽ truy xuất các quy định liên quan, sau đó tổng hợp thông tin và đưa ra câu trả lời chi tiết.
d. Lưu trữ và tối ưu hóa trong cơ sở dữ liệu vector
Các vector được tạo ra từ Embedding có thể được lưu trữ trong cơ sở dữ liệu vector, giúp tăng tốc độ tìm kiếm và tối ưu hóa hiệu suất xử lý cho các hệ thống lớn.
5. Ứng dụng trong Bài Toán Hỏi Đáp
Dưới đây mình sẽ giới thiệu đến mọi người cách dùng Gemini Embeddings và RAG thông qua Python để viết bot hỏi đáp các vấn đề
Bước 1: Tài liệu gốc
Hãy tạo một số chuỗi để đóng vai trò là tài liệu văn bản, sau đó chúng ta sẽ đọc các tệp khác như PDF.
sports_news_text = {'title':'Sports Section',
'text':"The San Francisco 49ers are heading to the super bowl in a football showdown!"}
finance_news_text = {'title':"Finance Section",
'text':"Meta stock has reached all time highs and has become a major part of the S&P500."}
Bước 2: Tải mô hình Embedding
import google.generativeai as genai
genai.configure(api_key=api_key)
Bước 3: Tạo vector Embedding
sports_embedding_vector = genai.embed_content(model='models/text-embedding-004',content=sports_news_text['text'],
task_type='retrieval_document')
finance_embedding_vector = genai.embed_content(model='models/text-embedding-004',content=finance_news_text['text'],
task_type='retrieval_document')
Hãy tạo một hàm cho quá trình này:
def embed_text(text):
return genai.embed_content(model='models/text-embedding-004',content=text,
task_type='retrieval_document')['embedding']
Bước 4: Lưu trữ vector Embedding
Đối với các ứng dụng lớn hơn, bạn nên sử dụng cơ sở dữ liệu vector như ChromaDB, nhưng hiện tại chúng ta sẽ tạo cơ sở dữ liệu vector đơn giản của riêng mình kết nối vector Embedding với mô hình cho RAG.
import pandas as pd
df = pd.DataFrame()
documents = [finance_news_text,sports_news_text]
df = pd.DataFrame(documents)
df.columns = ['Title', 'Text']
df
df['Embeddings'] = df['Text'].apply(embed_text)
Bước 5: Tìm kiếm tương tự
Hệ thống câu hỏi và trả lời (Q&A) nhằm mục đích sàng lọc qua các tài liệu này. Quá trình này bao gồm đặt một truy vấn cụ thể về điều chỉnh siêu tham số. Sau đó, truy vấn này được chuyển đổi thành một vector Embedding, về cơ bản là một vector số được tạo thành từ các giá trị dấu phẩy động. Vector này đại diện cho câu hỏi sau đó được so sánh có phương pháp với mảng vector Embedding tài liệu được lưu trữ trong dataframe.
Sự so sánh dựa trên phép toán toán học được gọi là tích vô hướng. Phép toán này đánh giá định lượng sự liên kết hoặc sự tương tự về hướng giữa hai vector. Đáng chú ý, vector chúng ta nhận được từ API đã được chuẩn hóa trước, đảm bảo nó sẵn sàng để so sánh.
Kết quả của tích vô hướng, đo lường sự tương tự, trải dài trong khoảng từ -1 đến 1. Giá trị tích vô hướng là 1 biểu thị sự liên kết hoàn hảo, cho thấy các vector chia sẻ cùng một hướng. Ngược lại, giá trị -1 cho thấy sự đối lập hoàn toàn về hướng, phản ánh sự khác biệt. Giá trị 0, nằm ở giữa, cho thấy tính trực giao, có nghĩa là các vector vuông góc và không có mối quan hệ nào với nhau về hướng. Hiểu những giá trị này và ý nghĩa của chúng là điều cần thiết để giải thích sự tương tự giữa truy vấn và vector Embedding tài liệu trong hệ thống Q&A của chúng ta.
import numpy as np
def query_similarity_score(query,vector):
'''
INPUTS:
query: str: The user prompt
vector: array: The existing vector embedding from a document
OUTPUT:
score: float - Cosine similarity score
'''
query_embedding = embed_text(query)
return np.dot(query_embedding,vector)
query = "Any interesting news about the stock market today?"
df['Similarity'] = df['Embeddings'].apply(lambda vector: query_similarity_score(query,vector))
df.sort_values('Similarity',ascending=False)[['Title','Text']].iloc[0]
def most_similar_document(query):
df['Similarity'] = df['Embeddings'].apply(lambda vector: query_similarity_score(query,vector))
title = df.sort_values('Similarity',ascending=False)[['Title','Text']].iloc[0]['Title']
text = df.sort_values('Similarity',ascending=False)[['Title','Text']].iloc[0]['Text']
return title,text
Bước 6: Chèn văn bản như ngữ cảnh bằng RAG
Chúng ta chỉ cần lấy văn bản liên quan nhất để giúp Mô hình Tạo Văn bản trả lời truy vấn.
def RAG(query):
title,text = most_similar_document(query)
model = genai.GenerativeModel('gemini-1.5-flash')
prompt = f'Answer this query:\n{query}.\nOnly use this context to answer:\n{text}'
response = model.generate_content(prompt)
return f'{response.text}\n\nSource Document:{title}'
print(RAG("Any interesting news about the stock market today?"))
Kết quả nhận được:
Yes, Meta stock has reached all-time highs, making it a major part of the S&P 500. This is significant because it reflects the company's strong financial performance and its growing influence in the technology sector.
Source Document:Finance Section
TÙY CHỌN: Mở rộng sang nhiều tài liệu thực tế hơn
Có rất nhiều thư viện cho phép bạn trích xuất văn bản từ các tài liệu thực tế, ví dụ: PDF! Bạn có thể tạo một bot giúp trả lời các câu hỏi về tài liệu của chính công ty bạn.
6. Một số lưu ý khi sử dụng Gemini embeddings
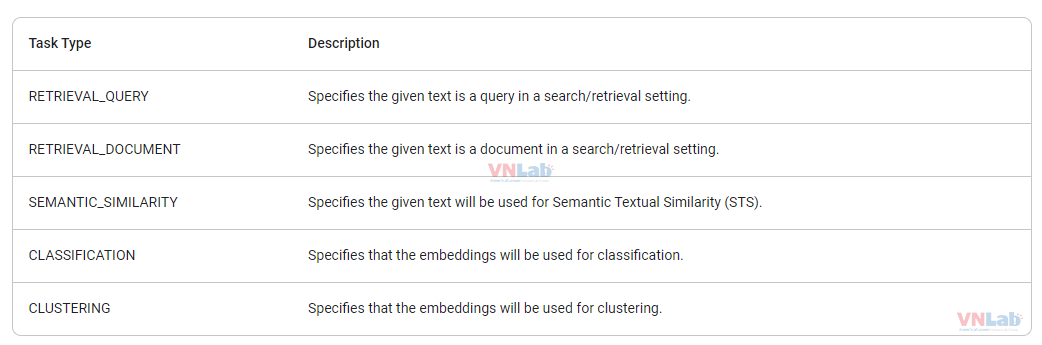
- Gemini sử dụng models embedding `models/text-embedding-004`. Hãy để ý giới hạn của token và request để tránh bị lỗi nhé.
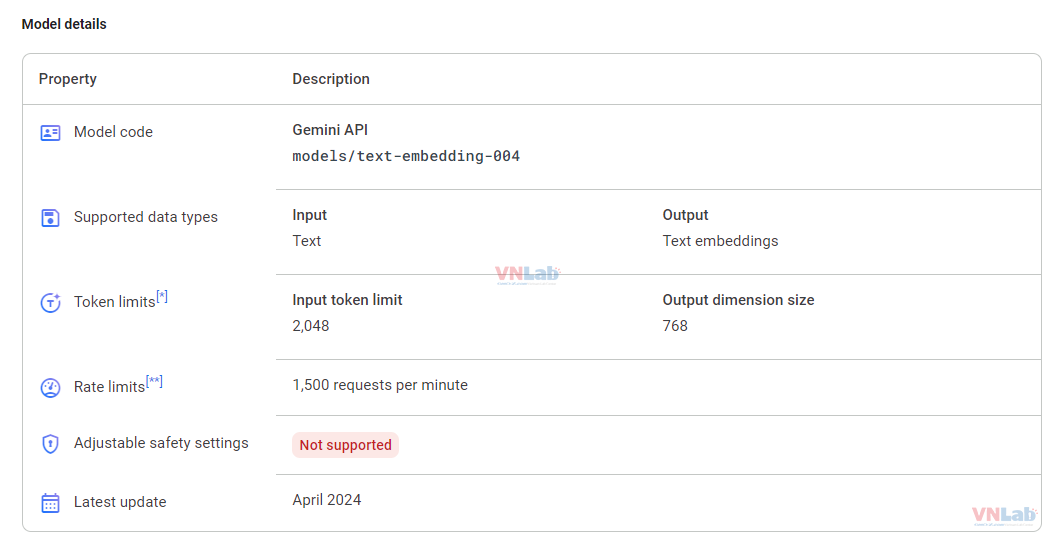
- Các tham số áp dụng cho các mô hình nhúng `models/text-embedding-004` .Có các loại tác vụ sau: