
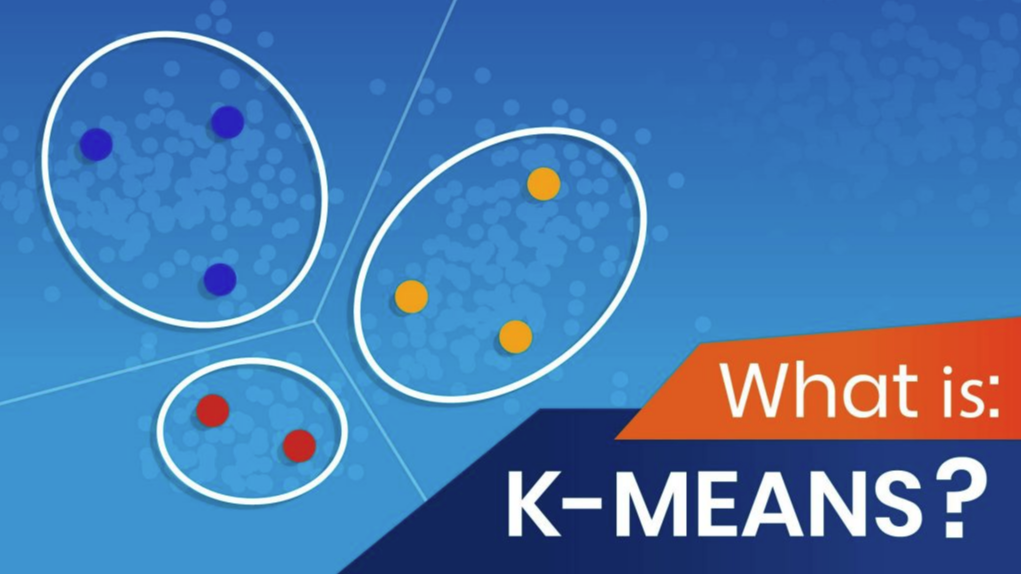
K-mean clustering
K-mean clustering là một phương pháp để tìm các cụm và hạt nhân - trung tâm của cụm trong một tập hợp dữ liệu không được gắn nhãn. Người ta chọn số lượng hạt nhân cụm mong muốn phân chẳng hạn như k cụm. Thuật toán K-mean di chuyển lặp đi lặp lại các hạt nhân để giảm thiểu tổng số trong phương sai cụm. Với một tập hợp các hạt nhân ban đầu, thuật toán Kmeans lặp lại hai bước:
• Đối với mỗi hạt nhân, tính toán khoảng cách giữa các training ponit với nó và nếu gần nó hơn -> sẽ gán là cụm của hạt nhân đấy.
• Sau khi phân được cụm như ở bước trên, thì tiếp theo các training point của các cụm tính toán vector trung bình để được vị trí của hạt nhân mới và lặp lại bước trên đến khi không thể thay đổi được vị trí hạt nhân nữa.
Phân cụm có nhiều hữu ích đặc biệt và cực kỳ phổ biến trong ngành khoa học dữ liệu. Trong đó như :
- Phân tích cụm được sử dụng rộng rãi trong nghiên cứu thị trường, nhận dạng mẫu, phân tích dữ liệu và xử lý ảnh.
- Phân tích cụm cũng có thể giúp các nhà khoa học dữ liệu khám phá ra các nhóm khác hàng của họ. Và họ có thể mô tả đặc điểm nhóm khách hàng của mình dựa trên lịch sử mua hàng.
- Trong lĩnh vực sinh học, nó có thể được sử dụng để xác định phân loại thực vật và động vật, phân loại các gen có chức năng tương tự và hiểu sâu hơn về các cấu trúc vốn có của quần thể.
Vậy để giải các bài toán về phân cụm cần có công cụ/phương pháp, K-means là một trong những thuật toán được sử dụng phổ biến nhất. Trong hướng dẫn này mình sẽ bắt đầu với cơ sở lý thuyết của thuật toán K-means, sau đó sẽ ứng dụng vào 1 ví dụ đơn giản với Python và thư viện Sklearn.
K-means
K-means hoạt động thế nào?
Giả sử chúng ta muốn chia các điểm sau thành các cụm.

Đầu tiên, chúng ta phải chọn bao nhiêu cụm mà chúng ta muốn phân? K trong ‘K-means’ là viết tắt của số cụm mà chúng ta đang muốn xác định. Mình sẽ bắt đầu với việc chọn 2 cụm, đối với 3, 4 cụm thuật toán cũng sẽ làm tương tự.
Bước thứ 2 là chỉ định 1 điểm, mình sẽ gọi nó là hạt trung tâm để bắt đầu (nó được chọn ngẫu nhiên hoặc cũng được chỉ định bởi các nhà khoa học dữ liệu dựa trên kiến thức trước đó về dữ liệu).
Phân thành 2 cụm sẽ có 2 hạt trung tâm, ở đây là hạt màu xanh lá cây và màu cam như hình dưới.

Bước tiếp là tính khoảng cách của hạt trung tâm với các hạt khác. Nếu điểm nào gần trung tâm hơn nó sẽ được gán là màu của hạt trung tâm đó. Ví dụ điểm này gần với hạt màu xanh lá cây hơn là điểm màu cam hơn nên nó sẽ thuộc cụm xanh lá.

Mặt khác, điểm gần với hạt màu cam hơn nên nó sẽ là 1 phần của cụm cam.

Bằng cách này chúng ta có thể gán tất cả các điểm trên biểu đồ trong mỗi cụm, dựa trên tính khoảng cách giữa 2 điểm biết tọa độ, dưới đây là công thức nhắc lại? Các bạn có thấy quen quen không =))

Đây là không gian 2 chiều. Thế đối với không gian 3 chiều hay nhiều chiều thì sao? Dưới đây là công thức tổng quát:

Tiếp tục với biểu đồ phân lớp bên trên sau khi đã gán hết cụm của các điểm, chúng ta sẽ tính lại tọa độ hạt trung tâm thêm lần nữa rồi lặp lại các bước tính khoảng cách trên để gán lại các điểm.

Tính tọa điểm của hạt trung tâm mới sẽ bằng tổng tọa độ các điểm rồi chia cho số điểm tương ứng - toán học lớp 12. Chúng ta lặp lại sau khoảng 2 lần 3 lần hoặc có thể 1000 lần đến khi chúng ta đạt được giải pháp phân cụm và không thể điều chỉnh hạt trung tâm được nữa.

Example
Về lý thuyết đơn giản thì chỉ có vậy, mình sẽ thực hiện 1 ví dụ phân cụm với python để thực hành nhé.
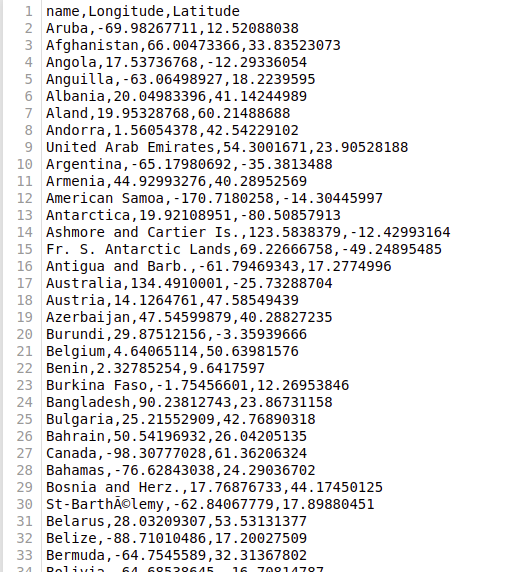
Ví dụ mình đưa ra ở đây là cho máy có thể nhận biết phân cụm các quốc gia dựa vào tọa độ của các quốc gia đó. Tập dữ liệu sẽ có dạng như hình dưới gồm 241 nước trên thế giới. Các bạn cũng có thể tải tập dữ liệu này để thực hành thử bằng cách tìm kiếm trên google nhé !!
Mình sẽ sử dụng Jupyter notebook để code nhằm trực quan hóa dữ liệu.
Đầu tiên mình sẽ import các thư viện của Python có sẵn để sử dụng trong bài này:

Dùng thư viện pandas để đọc dữ liệu. Tập dữ liệu và tọa độ và tên các quốc gia ở đây mình đặt tên là Countries_exercise.csv

Sau đó mình sẽ vẽ sự phân bố các quốc gia trên biểu đồ - mỗi 1 dấu chấm là 1 quốc gia.

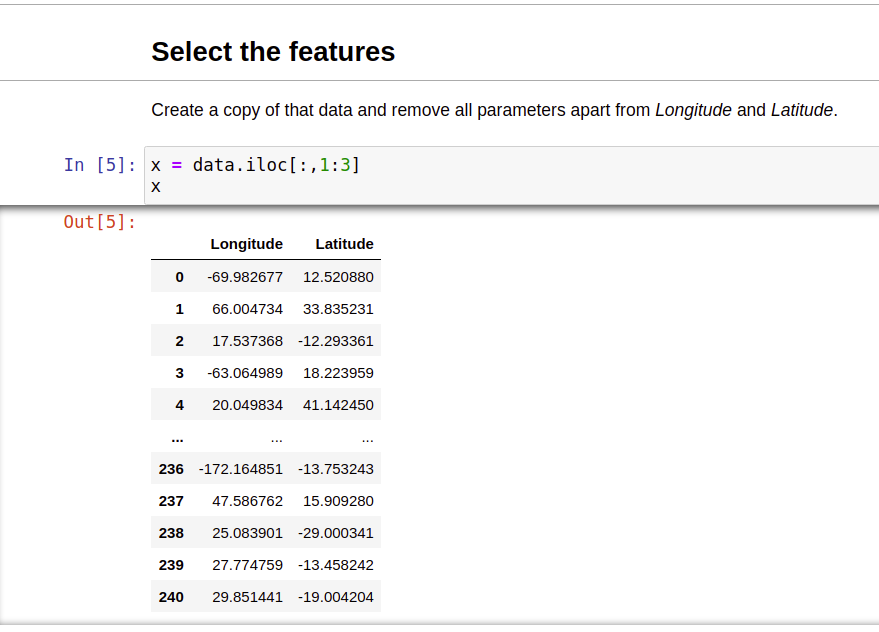
Mình sẽ gán giá trị của x là các kinh độ và vĩ độ của các quốc gia để chuẩn bị cho việc tính toán phân lớp.
Phần quan trọng là ở đây nha !! Theo như thuật toán K-means mình vừa trình bày ở trên thì trong thư viện của sklearn có sẵn do các nhà khoa học họ đã xây dựng để phục vụ cho việc phân tích và xử lý dữ liệu được thuận tiện hơn.
Tất cả thuật toán trên được xử lý bằng cú pháp: “KMeans(5)” trong đó 5 là số phân cụm mình muốn phân. Các bạn cũng có thể thay thành 2 3 7 10 … cụm rồi chạy lại xem sao nhé.

Các dự đoán về các quốc gia xử lý xong sẽ được cho vào mảng và in ra như thế kia theo thứ tự của tập dữ liệu. Nhưng … có vẻ nhìn như thế không ổn lắm :( mình sẽ lại vẽ nó trên biểu đồ kết hợp matplotlib + seaborn. Thư viện seaborn có tác dụng thay đổi màu đồ thị, tùy biến cho chúng ta dễ nhìn hơn. Mình sẽ sử dụng màu rainbow để phân cụm nhìn cho rõ =))

Còn đây là biểu đồ thế giới thực:

Hmm… liệu 2 hình trên có phải là 1?? Thực tế do các quốc gia có diện tích to nhỏ khác nhau nhưng khi biểu diễn trên matplotlib thì các quốc gia tương đương nhau và biểu diễn bằng 1 dấu chấm. Còn để trực quan hóa dữ liệu như phía dưới hãy dùng công cụ Tableau để thử xem và chia sẻ cho mình kết quả nhé ;)
Với ví dụ đơn giản này chưa phải là tất cả nhưng cũng là 1 bước nhỏ để mình làm được những việc lớn hơn trong phân tích dữ liệu.
Nếu có thể trong bài sau mình sẽ viết thêm chi tiết về ưu, nhược điểm của phân cụm, trong phân tích dữ liệu chọn bao nhiêu cụm để phân là tối ưu nhất - cái này không phải chọn bừa là được nha,...
Hẹn gặp lại những người ham học hỏi trong blog tới nhé !!
L.B.T






