
Định Nghĩa
Simple exponential smoothing (SES) là một phương pháp dự đoán dữ liệu theo thời gian. Nó sử dụng tổng có trọng lượng của dữ liệu trước trong dãy dữ liệu theo thời gian để đoán các dữ liệu trong tương lai.
Có thể hiểu đơn giản SES là phương pháp, sử dụng khái niệm:"Dữ liệu mới quan trọng hơn dữ liệu cũ".
Ví dụ đơn giản:
- Giả sử từ đầu tháng 4, nhiệt độ tuần 1 là 20 độ
- Nhiệt độ tuần 2 là 23 độ
- Nhiệt độ tuần 3 là 25 độ
- Từ nhiệt độ tuần 3, ta có thể ước lượng được nhiệt độ tuần 4 sẽ tầm 26-28 độ.
- Tuy nhiên nếu từ nhiệt độ từ tuần 1 (20 độ), ta khó có thể đoán được nhiệt độ tuần 4 là bao nhiêu.
Từ ví dụ trên, có thể thấy vì sao dữ liệu mới quan trọng hơn dữ liệu cũ khi dự đoán số liệu tương lai. Hiểu được việc này, ta sẽ đặt trọng số cao cho dữ liệu mới, và trọng số thấp hơn cho dữ liệu cũ, thể hiện bằng thông số alpha.
Alpha
Alpha là thông số quan trọng trong SES, kiểm tra độ quan trọng của dữ liệu mới và dữ liệu cũ. Alpha khoảng từ 0.0 đến 1.0. Độ quan trọng sẽ thể hiện trực tiếp qua trọng số
- Alpha cao: Tăng trọng số cho dữ liệu mới => Tăng độ quan trọng cho dữ liệu mới.
- Alpha thấp: Tăng trọng số cho dữ liệu cũ => Tăng độ quan trọng cho dữ liệu cũ.
Điểm cần lưu ý là dữ liệu cũ sẽ không có trọng số cao hơn dữ liệu mới.
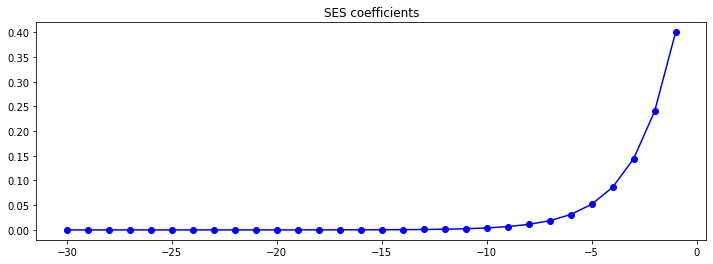
Ví dụ, với alpha là 0.4, các trọng số sẽ trông như sau:
(-30) có nghĩa là dữ liệu từ 30 đơn vị thời gian (ngày/tháng/năm) trước, 0 có nghĩa là dữ liệu từ hiện tại. Có thể thấy, thời gian tăng từ (-30) về 0,
hay từ dữ liệu cũ sang dữ liệu mới, thì các trọng số cũng sẽ tăng theo hàm mũ. Vì vậy phương pháp này được đặt tên là "exponential smoothing".
Loại dữ liệu
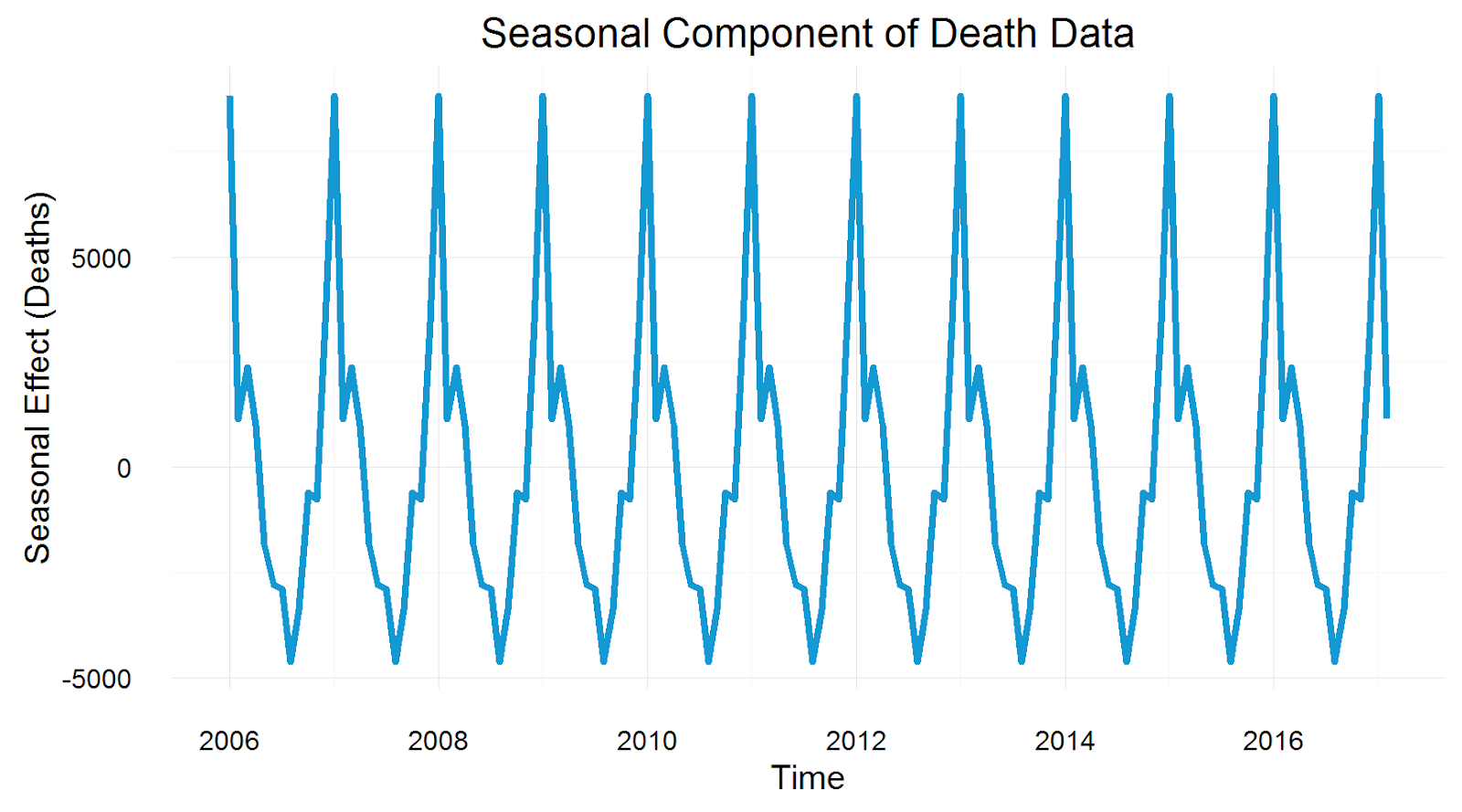
Điểm cần lưu ý là SES chỉ dử dụng được cho dữ liệu theo thời gian có 1 feature, không có trend và seasonality.
Dữ liệu thời gian mà có khuynh hướng đi lên hoặc đi xuống sẽ có trend.
Dữ liệu thời gian có trend sẽ có hình như sau:
các dữ liệu tăng lên hay giảm xuống giống nhau theo mùa là dữ liệu có seasonality. Ví dụ như dữ liệu về mua bán kem(tăng mùa hè giảm mùa đông), nhiệt độ, lượng mưa...
Dữ liệu có seasonality có hình như sau:
Dữ liệu không có trend và không có seasonality sẽ trông như sau. Chỉ cần dữ liệu trông tương tự như thế này, ta có thể áp dụng SES.
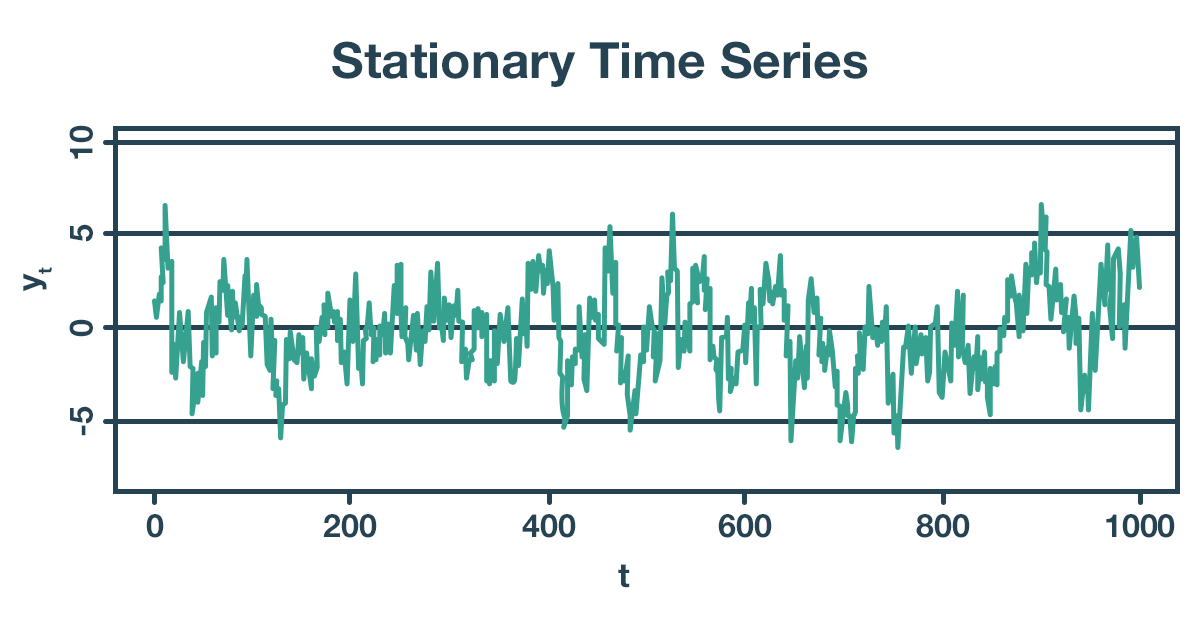
Bài toán
Sau đây, ta sẽ thử áp dụng SES vào một tập dữ liệu. Đây là dữ liệu về số bé gái được sinh ra ở bang California, Mỹ vào năm 1959. Lưu ý dữ liệu này không có trend và seasonality như nói ở trên
Dữ liệu sử dụng:
https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv
Code:
from statsmodels.tsa.holtwinters import SimpleExpSmoothing
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
data = pd.read_csv('daily-total-female-births.csv', header=0, index_col=0)
data.plot(figsize=(15,10))
plt.show()
Dữ liệu sẽ trông như hình sau:
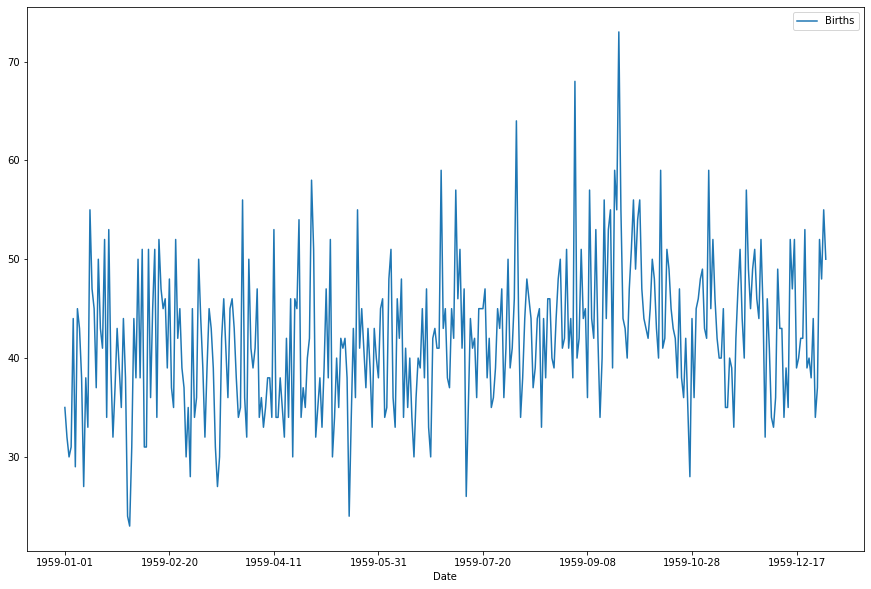
Ta muốn chia ra làm hai tập train và test. Tập test sẽ có dữ liệu của 30 ngày cuối năm 1959. Tập train sẽ có dữ liệu còn lại, gồm 335 ngày trước:
test_days = 30
data = data.reset_index()
train, test = data[:-test_days], data[-test_days:]
Code sau sẽ train SES với dữ liệu train từ đầu năm đến ngày thứ 335, sau đó đoán số em bé gái sinh của ngày 336. Lần chạy tiếp theo, train với dữ liệu đến ngày thứ 336, và đoán số em bé gái sinh của ngày 337. Và cứ tiếp tục như vậy. Có thể hiểu đơn giản là model đang đoán dữ liệu của ngày hôm sau, dựa vào việc học tất cả dữ liệu trước đó (kể cả trong test).
history = train["Births"].tolist()
predictions = []
for new_obs in test["Births"].values:
model = SimpleExpSmoothing(history)
model_fit = model.fit(smoothing_level=0.8)
prediction = model_fit.forecast(steps=1)
predictions.append(prediction[0])
history.append(new_obs)
Alpha được thể hiện ở parameter là smoothing_level. Ta đặt tạm là 0.8 và cho model học và dự đoán thử.
Chúng ta có thể so sánh kết quả ở hình dưới. Đường màu xanh nước biển là đường dự đoán số em bé sinh ra trong tương lai (pred), đường màu da cam là dữ liệu số em bé thật sự được sinh ra (truth_value).
import numpy as np
result_data = np.array([predictions, test["Births"].tolist()]).T
result_df = pd.DataFrame(data=result_data, columns=["pred", "truth_values"])
fig, ax = plt.subplots(1, 1, figsize=(12, 8))
result_df.plot(ax=ax, marker="o")
plt.title("Exponential smoothing 1-step 30 predictions")
plt.grid()
plt.show()
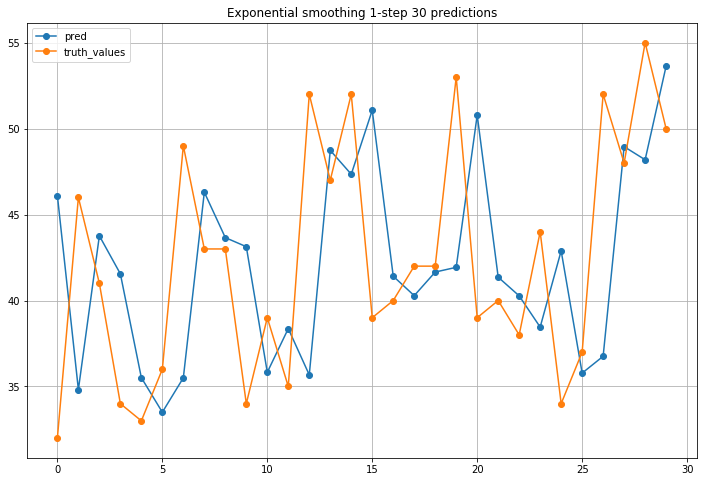
Có thể thấy là với alpha là 0.8 dự đoán khá khớp, nhưng đang lệch 1 ngày. Có vẻ dự đoán trông không đúng lắm.
Có thể thử ở code sau để kiểm tra SES có học tốt với dữ liệu train không:
fig, ax = plt.subplots(1, 1, figsize=(12, 8))
model = SimpleExpSmoothing(train["Births"])
model_fit = model.fit(smoothing_level=0.8)
predictions = model_fit.predict(1, len(train))
check_result_data = np.array([predictions, data[:len(train)]["Births"].tolist()]).T
check_result_df = pd.DataFrame(data=check_result_data, columns=["pred", "truth_values"]).tail(50)
check_result_df.plot(ax=ax, marker="o")
plt.title("Exponential smoothing train tail 50 predictions")
plt.grid()
plt.show()
Kết quả sẽ trông như sau:
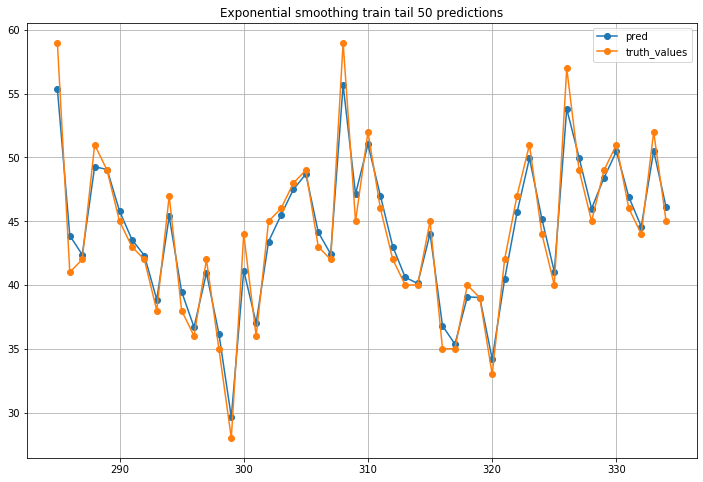
Có thể thấy sau khi train model với dữ liệu vào đoán lại dữ liệu đã được train rồi, dự đoán chính xác, không bị lệch 1 ngày như dữ liệu test.
Thực ra, model SES ở trên đang hoạt động đúng với thiết kế của model, và đúng với công thức. Việc model đưa ra dự đoán trong như bị lệch 1 đơn vị thời gian là vấn đề thường gặp phải ở nhiều model cho dữ liệu theo thời gian, không chỉ riêng SES. Để cho dự đoán đỡ lệch hơn, các bạn có thể thử nghiệm với các giá trị alpha nhỏ hơn.
Kết luận
Điểm cần lưu ý là hầu hết dữ liệu theo thời gian sẽ có trend và seasonality, để xử lý dữ liệu này sẽ cần Double và Triple Exponential Smoothing. Các phương pháp này sẽ được đề cập trong các bài viết sau.






