
1. Focal loss là gì?
Loss là loss function trong machine learning.
Focal có nghĩa là trọng tâm.
Focal Loss là một loại loss trong machine learning. Focal loss dùng để giảm độ quan trọng cho những dữ liệu thuật toán đã học tốt rồi, và tập trung học những dữ liệu khó học hơn.
Paper ban đầu sử dụng focal loss cho object classification. Tuy nhiên, focal loss có thể áp dụng vào những bài toán có class imbalance cao.
Ví dụ, xác xuất người bị ung thư trên thế giới là 198/100,000 người. Nếu chúng ta muốn tạo một machine learning model để đoán người nào bị ung thư, ta sẽ vướng phải vấn đề class imbalance. Vì dữ liệu người chuẩn đoán có bệnh ung thư (0.198%) sẽ ít hơn nhiều với người không bị bệnh ung thư (99.82%). Vì dữ liệu người không bị bệnh ung thư nhiều hơn, nên bình thường model sẽ có khuynh hướng đoán người bị ung thư là không bị bệnh.
Đối với bài toán này, việc đoán người bị bệnh ung thư là quan trọng. Nói cách khác, thà đoán người không bị bệnh ung thư là bị ung thư, hơn là đoán người bị ung thư là không bị bệnh gì.
Nếu sử dụng focal loss, ta có thể một phần khắc phụ được vấn đề class imbalance và tập trung model vào việc học để tăng độ chính xác cho những trường hợp khó dự đoán.
2. Công thức
Tính error của dự đoán():
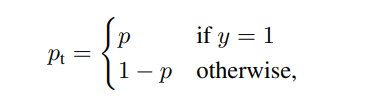
Công thức loss cho Cross Entropy
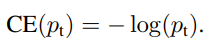
Công thức cho Focal Loss. Lưu ý là Focal Loss sẽ có thêm parameter là gamma.
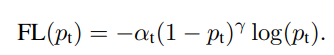
Khi sử dụng focal loss ta sẽ có thêm 2 parameter cần điều chỉnh:
Trong bài toán classification sẽ dữ liệu sẽ có 2 class: 0 (người không bị ung thư) và 1 (người bị ung thư).
- Alpha (hiểu đơn giản class weight): hiểu đơn giản là trọng số cho class 0 và 1. Trọng số này có cả ở trong binary cross entropy. Bình thường alpha > 0.5 thì model sẽ tập trung học những dự liệu có class là 1.
Ví dụ nếu alpha = 0.8.
Giả sử, 1 dòng dữ liệu có class là 1 nhưng model đoán 0 (false negative) sẽ có loss là: 11.05. 1 dòng dữ liệu có class là 0 nhưng bị đoán là 1 (false positive) sẽ có loss là: 2.76.
Nếu alpha = 0.5 thì loss cả 2 dòng dữ liệu bị đoán sai sẽ có loss giống nhau.
Dưới là hình cho thấy loss của một dòng dữ liệu khi bị đoán sai khi với giá trị alpha từ 0 đến 1.
- Loss cho class là 1 nhưng model đoán 0 (false negative) là màu xanh nước biển.
- Loss cho class là 0 nhưng model đoán 1 (false positive) là màu cam.
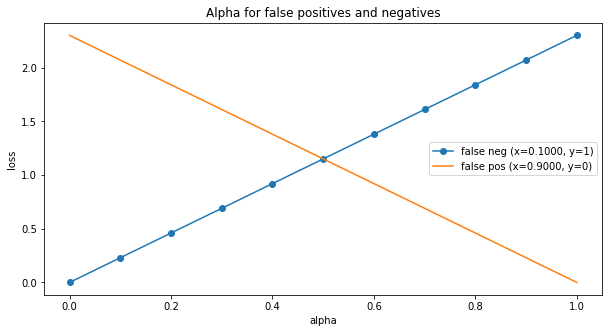
Có thể thấy là nếu alpha tăng từ 0 đến 1, thì loss cho false negative tăng, và false positive sẽ giảm. Ở 0.5 (giao nhau giữa hai đường), hai loss sẽ bằng nhau
- Gamma: điều chỉnh loss.
Gamma cao: loss sẽ nhỏ hơn cho dữ liệu dễ học, cao hơn cho dữ liệu khó học. Qua đó model sẽ tập trung học cho những dữ liệu khó đoán hơn.
Nếu Gamma bằng 0 thì Focal Loss sẽ có loss giống như Binary Crossentropy
Hình dưới cho thấy loss cho 1 dòng dữ liệu học dễ và học khó thay đổi như thế nào khi gamma tăng.
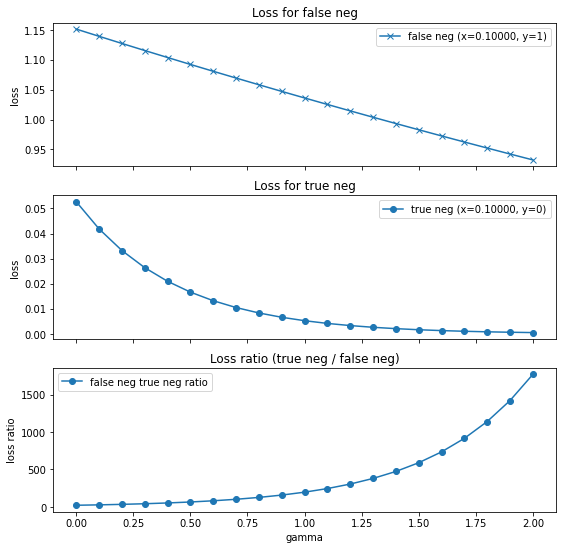
- Hình 1: Dữ liệu học khó (false negative): class là 1, nhưng lại model đoán là 0.1 (gần 0)
- Hình 2: Dữ liệu học dễ (true negative): class là 0, và model đoán là 0.1 (đúng là gần 0)
- Hình 3: Tỷ lệ loss của dữ liệu học khó so với dữ liệu học dễ. Có thể thấy khi gamma tăng thì loss của dữ liệu học khó tăng gấp nhiều lần so với dữ liệu học dễ. Model sẽ tập trung giảm loss cho dữ liệu học khó.
Lưu ý: Khác với alpha, gamma không liên quan đến class là 0 hay là 1, chỉ đơn giản là dữ liệu học dễ hay khó. Tuy nhiên, bình thường nếu có class imbalance, class=0 sẽ có dữ liệu nhiều hơn, nên model học dễ hơn.
3. Áp dụng vào bài toán
Chúng ta sẽ áp dụng Focal Loss vào bài toán về dự đoán giao dịch tín dụng không hợp lệ. Mục đích là để chủ thẻ tín dụng không phải trả tiền khi thông tin tín dụng của họ bị lộ và bị sử dụng bất hợp pháp. Dữ liệu ở link dưới
https://www.kaggle.com/mlg-ulb/creditcardfraud?select=creditcard.csv
Để ý là dữ liệu này chỉ có 492 dòng dữ liệu là có giao dịch không hợp lệ (class=1). 284,315 dòng còn lại là giao dịch hợp lệ (class=1). Nên đây là bài toán có class imbalance.
Vì lý do bảo mật, nên phần lớn feature được "mã hóa" bằng PCA. Để làm demo đơn giản, chúng ta không cần phải phân tích dữ liệu hay xử lý dữ liệu nhiều. Chỉ cần áp dụng normalization bằng standard scaler là đủ.
Notebook xử lý dữ liệu:
https://gitlab.com/longlm/focal_loss/-/blob/master/notebooks/1_prepare_data.ipynb
Chúng ta sẽ tạo Neural Network cho focal loss với cấu trúc như sau:
def get_focal_relu_nn_simple_architect(input_shape, pi=0.01):
relu_layer = partial(
tf.keras.layers.Dense,
activation="relu",
kernel_initializer="he_normal")
// Một điểm cần lưu ý là như paper ban đầu, ta sẽ nên khởi tạo bias để output của model lúc chưa học sẽ cho cho dự đoán gần bằng 0.1 (bình thường sẽ là 0.5)
output_bias = -math.log((1 - pi)/pi)
print("Output bias: %.3f" % output_bias)
output_bias_init = tf.keras.initializers.Constant(output_bias)
relu_nn_layers = [
tf.keras.layers.InputLayer(input_shape),
relu_layer(200),
relu_layer(100),
relu_layer(20),
tf.keras.layers.Dense(1, activation="sigmoid",
bias_initializer=output_bias_init)
]
nn_model = tf.keras.models.Sequential(relu_nn_layers)
return nn_model
Chúng ta sẽ thử Neural Network với Focal Loss và Binary Cross Entropy và so sánh kết quả.
Notebook cho Focal loss:
https://gitlab.com/longlm/focal_loss/-/blob/master/notebooks/2_focal_loss.ipynb
Notebook cho Binary Cross Entropy:
https://gitlab.com/longlm/focal_loss/-/blob/master/notebooks/2_binary_crossentropy.ipynb
4. Kết quả:
| model | recall | precision | auroc | auprc |
|---|---|---|---|---|
| binary ce loss | 0.7027 | 0.8889 | 0.9247 | 0.8053 |
| focal loss | 0.7973 | 0.7468 | 0.9632 | 0.6903 |
Confusion matrix cho Binary Cross Entropy
pred_0 pred_1
true_0 [85282, 13
true_1 44, 104]
Confusion matrix cho Focal Loss
pred_0 pred_1
true_0 [85255, 40
true_1 30, 118]
Nhìn kết quả có thể thấy Focal Loss sẽ có AUROC cao hơn so với binary cross entropy, nhưng ngược lại auprc lại giảm. Bài toán này cần có recall cao nên focal loss có khả năng dự đoán những transaction. Nhìn confusion matrix cũng có thể thấy true positive của focal loss cao hơn một chút so với binary crossentropy






