

BERT là mô hình ngôn ngữ (language model) đầu tiên được huấn luyện không giám sát (unsupervised) và được học sâu 2 chiều (deeply bidirectional) và thể hiện được kết quả vượt trội hơn hẳn các mô hình trước đó trong các bài toán xử lý ngôn ngữ tự nhiên (NLP). Tuy nhiên, BERT cũng có những điểm bất lợi của riêng mình: chi phí huấn luyện (training) mô hình và khả năng mở rộng (scaling).
Trong bài viết này, ta sẽ cùng tìm hiểu một mô hình mới được phát triển bởi Google AI có tên ALBERT và được nhắc tới trong bài báo "ALBERT: A Lite BERT for Self-supervised Learning of Language Representations". ALBERT có số lượng tham số nhỏ hơn đáng kể trong khi vẫn giữ được hiệu năng tương đương với BERT. Sau đó ta sẽ áp dụng ALBERT vào bài toán xây dựng máy hỏi đáp (Question Answering)
ALBERT
Khác với BERT, ALBERT sử dụng 2 kỹ thuật để cắt giảm lượng tham số:
- Factorized Embedding Parametrization
- Cross-layer Parameber Sharing
Ngoài ra ALBERT còn được huấn luyện để dự đoán thứ tự câu (Sentence Order Predition - SOP). Điều này chỉ ra được sự không hiệu quả của việc đoán câu tiếp theo (Next Sentence Prediction - NSP) trong BERT.
Factorized Embedding Parametrization
Mục tiêu của mô hình là để huấn luyện biểu diễn phụ thuộc ngữ cảnh "ẩn" (context independent) của các từ (token) và tạo ra các vector - word embedding. Word Embeddings sẽ cố gắng "học" sự tương quan giữa các từ mà không phụ thuộc vào ngữ cảnh, và lớp ẩn (hidden layer) sẽ cố gắng "học" các "mẫu" - pattern của từ theo phân phối xác suất của bộ dữ liệu huấn luyện.
Mô hình có thể học thông tin ngữ cảnh tốt hơn nếu kích thước vector ở tầng ẩn (hidden layer) lớn hơn. Tuy nhiên điều này dẫn tới chi phí tính toán rất lớn cho ma trận embedding. Do vậy tác giả của ALBERT đã đề xuất một ý tưởng tách các lớp word embedding và hidden-layer embedding. Ý tưởng này như sau: chiếu các vector one-hot có độ dài vocab_size sang vector nhỏ hơn đáng kể có độ dài embedding_dim (e.g 128), sau đó chiếu vector này sang vector có chiều dài hidden_sim (e.g 768). Nhờ đó số lượng tham số cho quá trình được giảm xuống đáng kể từ O(V x H) xuống O(V x E + E x H) nếu xét về việc H rất lớn so với E.
Cross-Layer Parameter Sharing
Trong ALBERT, các tham số giữa các lớp (layer) được chia sẻ với nhau, việc này không những giúp giảm được số lượng tham số trong mô hình mà còn làm cho các tham số đạt trạng thái ổn định hơn
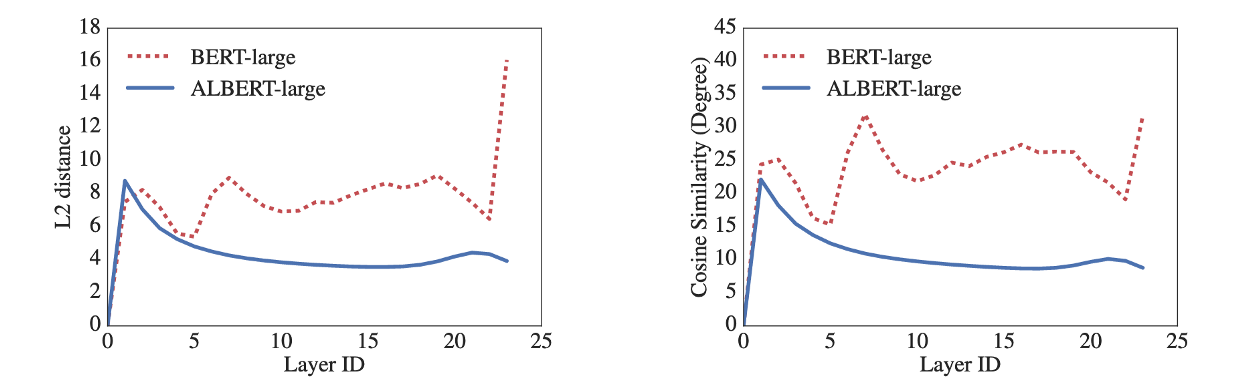
Hình ở bên trái so sánh khoảng cách L2 giữa lớp input và embedidng giữa các layer, và hình bên phải so sánh độ tương tự cosin. Trong cả 2 hình, ta thấy đường biểu diễn của ALBERT mịn hơn nhiều so với BERT, điều đó chứng tỏ sự ổn định tham số của ALBERT là tốt hơn.
Sentence Order Prediction (SOP)
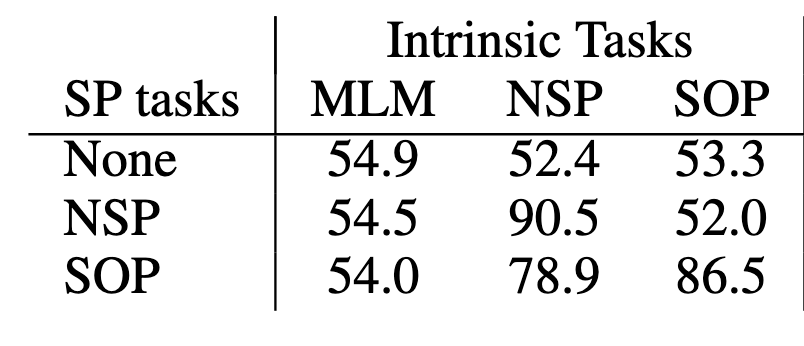
Trong BERT, 2 mục tiêu huấn luyện là Next Sentence Prediction (NSP) và Masked Language Modeling (MLM). Tuy nhiên các nghiên cứu gần đây đã chỉ ra tính không hiệu quả của NSP. NSP kết hợp mục tiêu dự đoán chủ đề (topic) và tính liên kết (coherence) làm một, điều này làm cho mục tiêu dự đoán chủ đề được ưu tiên hơn. Để khắc phục nhược điểm này, ALBERT được huấn luyện để phục vụ thêm 1 mục tiêu mới là "Dự đoán thứ tự của câu" (Sentence Order Prediction - SOP). Trong SOP, các dữ liệu đầu vào là các cặp câu, với nhãn positive khi 2 câu theo đúng thứ tự, và nhãn negative khi 2 câu theo thứ tự ngược lại. Kết quả thực nghiệm cho thấy NSP không thể giải quyết được SOP, ngược lại SOP cho ra kết quả tốt cho NSP.
Kết quả
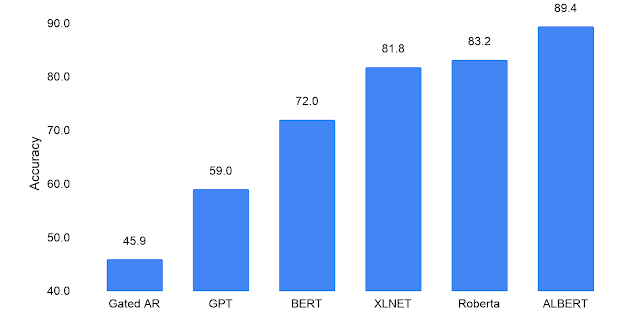
Trong bài đánh giá, tập dữ liệu RACE được sử dụng, mục tiêu là kiểm tra khả năng hiểu tổng thể của mô hình. BERT có điểm số là 72.0. Các mô hình cải tiến của BERT là XLNET, Roberta đạt kết quả tốt hơn là 81.8 và 83.2. Mô hình ALBERT-xxlarge đạt được số điểm là 82.3 khi được huấn luyện bằng tập dữ liệu của BERT (Wikipedia, sách). Tuy nhiên, khi huấn luyện với tập dữ liệu giống với XLNet và Roberta thì ALBERT đạt được điểm SOTA bằng 89.4.
Áp dụng ALBERT vào xây dựng hệ thống hỏi đáp
Trong phần này, ta sẽ sử dụng ALBERT để xây dựng hệ thống hỏi đáp (Question Answering). Hệ thống hỏi đáp là hệ thống có khả năng trả lời câu hỏi được đưa ra dưới dạng ngôn ngữ tự nhiên. Các hệ thống hỏi đáp thường xây dựng câu trả lời bằng cách truy vấn vào các hệ cơ sở dữ liệu tri thức. Ở trong bài viết này, ta sẽ xây dựng một chương trình đọc đoạn văn ngữ cảnh (context) và sẽ trả lời câu hỏi liên quan tới đoạn văn đó. Ngôn ngữ được sử dụng là Python, các thư viện cần thiết gồm có torch, transformers, tensorboardX.
-
Chuẩn bị môi trường
-
Tải thư viện transformers từ github
Code:!git clone https://github.com/huggingface/transformers \ && cd transformers \ && git checkout a3085020ed0d81d4903c50967687192e3101e770 -
Cài đặt các thư viện cần thiết
Code:!pip install ./transformers tensorboardX
-
-
Huấn luyện mô hình
Phần này thực hiện fine-tune mô hình ALBERT cho hệ thống hỏi đáp. Tập dữ liệu dùng để huấn luyện là SQuAD.
Nếu không muốn chờ do thời gian huấn luyện quá lâu (~1.5 giờ), bạn đọc có thể bỏ qua phần này và chuyển sang phần kế tiếp- Chuẩn bị dữ liệu
!mkdir dataset \ && cd dataset \ && wget https://rajpurkar.github.io/SQuAD-explorer/dataset/train-v2.0.json \ && wget https://rajpurkar.github.io/SQuAD-explorer/dataset/dev-v2.0.json - Huấn luyện mô hình
Các tham số của mô hình:- per_gpu_train_batch_size: số lượng ví dụ trong 1 vòng lặp trên GPU, hãy chú ý tới giới hạn bộ nhớ của GPU.
- save_steps: số bước (step) cho 1 lần lưu checkpoint.
- num_train_epochs: số epoch để huấn luyện.
- version_2_with_negative: cần có cho bộ dữ liệu SQuAD V2.0, có thể bỏ cờ này nếu dùng V1.1
Code:
!export SQUAD_DIR=/content/dataset \ && python transformers/examples/run_squad.py \ --model_type albert \ --model_name_or_path albert-base-v2 \ --do_train \ --do_eval \ --do_lower_case \ --train_file $SQUAD_DIR/train-v2.0.json \ --predict_file $SQUAD_DIR/dev-v2.0.json \ --per_gpu_train_batch_size 12 \ --learning_rate 3e-5 \ --num_train_epochs 1.0 \ --max_seq_length 384 \ --doc_stride 128 \ --output_dir /content/model_output \ --save_steps 1000 \ --threads 4 \ --version_2_with_negativeOutput:
2020-12-06 15:29:40.580377: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1 12/06/2020 15:29:43 - WARNING - __main__ - Process rank: -1, device: cpu, n_gpu: 0, distributed training: False, 16-bits training: False 12/06/2020 15:29:43 - INFO - filelock - Lock 140634587949992 acquired on /root/.cache/torch/transformers/0bbb1531ce82f042a813219ffeed7a1fa1f44cd8f78a652c47fc5311e0d40231.978ff53dd976bbf4bc66f09bf4205da0542be753d025263787842df74d15bbca.lock 12/06/2020 15:29:43 - INFO - transformers.file_utils - https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v2-config.json not found in cache or force_download set to True, downloading to /root/.cache/torch/transformers/tmpd6q7xopa Downloading: 100% 684/684 [00:00<00:00, 416kB/s] 12/06/2020 15:29:43 - INFO - transformers.file_utils - storing https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v2-config.json in cache at /root/.cache/torch/transformers/0bbb1531ce82f042a813219ffeed7a1fa1f44cd8f78a652c47fc5311e0d40231.978ff53dd976bbf4bc66f09bf4205da0542be753d025263787842df74d15bbca 12/06/2020 15:29:43 - INFO - transformers.file_utils - creating metadata file for /root/.cache/torch/transformers/0bbb1531ce82f042a813219ffeed7a1fa1f44cd8f78a652c47fc5311e0d40231.978ff53dd976bbf4bc66f09bf4205da0542be753d025263787842df74d15bbca 12/06/2020 15:29:43 - INFO - filelock - Lock 140634587949992 released on /root/.cache/torch/transformers/0bbb1531ce82f042a813219ffeed7a1fa1f44cd8f78a652c47fc5311e0d40231.978ff53dd976bbf4bc66f09bf4205da0542be753d025263787842df74d15bbca.lock 12/06/2020 15:29:43 - INFO - transformers.configuration_utils - loading configuration file https://s3.amazonaws.com/models.huggingface.co/bert/albert-base-v2-config.json from cache at /root/.cache/torch/transformers/0bbb1531ce82f042a813219ffeed7a1fa1f44cd8f78a652c47fc5311e0d40231.978ff53dd976bbf4bc66f09bf4205da0542be753d025263787842df74d15bbca 12/06/2020 15:29:43 - INFO - transformers.configuration_utils - Model config { "architectures": [ "AlbertForMaskedLM" ], "attention_probs_dropout_prob": 0, "bos_token_id": 2, "classifier_dropout_prob": 0.1, "do_sample": false, .... - Chuẩn bị dữ liệu
-
Viết code dự đoán
Ta sẽ sử dụng thư viện Hugging Face để dự đoán dựa trên mô hình vừa huấn luyện.
Có thể thiết lập use_own_model sang True để sử dụng mô hình vừa huấn luyện.import os import torch import time from torch.utils.data import DataLoader, RandomSampler, SequentialSampler from transformers import ( AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer, squad_convert_examples_to_features ) from transformers.data.processors.squad import SquadResult, SquadV2Processor, SquadExample from transformers.data.metrics.squad_metrics import compute_predictions_logits # READER NOTE: Set this flag to use own model, or use pretrained model in the Hugging Face repository use_own_model = False if use_own_model: model_name_or_path = "/content/model_output" else: model_name_or_path = "ktrapeznikov/albert-xlarge-v2-squad-v2" output_dir = "" # Config n_best_size = 1 max_answer_length = 30 do_lower_case = True null_score_diff_threshold = 0.0 def to_list(tensor): return tensor.detach().cpu().tolist() # Setup model config_class, model_class, tokenizer_class = ( AlbertConfig, AlbertForQuestionAnswering, AlbertTokenizer) config = config_class.from_pretrained(model_name_or_path) tokenizer = tokenizer_class.from_pretrained( model_name_or_path, do_lower_case=True) model = model_class.from_pretrained(model_name_or_path, config=config) device = torch.device("cuda" if torch.cuda.is_available() else "cpu") model.to(device) processor = SquadV2Processor() def run_prediction(question_texts, context_text): """Setup function to compute predictions""" examples = [] for i, question_text in enumerate(question_texts): example = SquadExample( qas_id=str(i), question_text=question_text, context_text=context_text, answer_text=None, start_position_character=None, title="Predict", is_impossible=False, answers=None, ) examples.append(example) features, dataset = squad_convert_examples_to_features( examples=examples, tokenizer=tokenizer, max_seq_length=384, doc_stride=128, max_query_length=64, is_training=False, return_dataset="pt", threads=1, ) eval_sampler = SequentialSampler(dataset) eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=10) all_results = [] for batch in eval_dataloader: model.eval() batch = tuple(t.to(device) for t in batch) with torch.no_grad(): inputs = { "input_ids": batch[0], "attention_mask": batch[1], "token_type_ids": batch[2], } example_indices = batch[3] outputs = model(**inputs) for i, example_index in enumerate(example_indices): eval_feature = features[example_index.item()] unique_id = int(eval_feature.unique_id) output = [to_list(output[i]) for output in outputs] start_logits, end_logits = output result = SquadResult(unique_id, start_logits, end_logits) all_results.append(result) output_prediction_file = "predictions.json" output_nbest_file = "nbest_predictions.json" output_null_log_odds_file = "null_predictions.json" predictions = compute_predictions_logits( examples, features, all_results, n_best_size, max_answer_length, do_lower_case, output_prediction_file, output_nbest_file, output_null_log_odds_file, False, # verbose_logging True, # version_2_with_negative null_score_diff_threshold, tokenizer, ) return predictions -
Dự đoán
Code:context = "New Zealand (Māori: Aotearoa) is a sovereign island country in the southwestern Pacific Ocean. It has a total land area of 268,000 square kilometres (103,500 sq mi), and a population of 4.9 million. New Zealand's capital city is Wellington, and its most populous city is Auckland." questions = ["How many people live in New Zealand?", "What's the largest city?"] # Run method predictions = run_prediction(questions, context) # Print results for key in predictions.keys(): print(predictions[key])Output:
convert squad examples to features: 100%|██████████| 2/2 [00:00<00:00, 339.84it/s] add example index and unique id: 100%|██████████| 2/2 [00:00<00:00, 3979.42it/s] 4.9 million. Auckland
Kết luận
Kể từ khi BERT ra đời, đã có nhiều mô hình ngôn ngữ (language model) mới ra đời với nhiều cải tiến (XLNet, Roberta,...). Trong đó ALBERT, đã khắc phục được những điểm yếu của BERT và chứng minh được hiệu quả của mình trong các bài toán xử lý ngôn ngữ tự nhiên. Nếu các bạn có góp ý về bài viết hay vấn đề cần thảo luận, xin vui lòng comment phía dưới, tôi sẽ cố gắng trả lời trong thời gian sớm nhất. Xin cảm ơn!






