

1. Đặt vấn đề:
Logging là quá trình ghi lại các sự kiện và thông tin quan trọng trong hệ thống hoặc ứng dụng để hỗ trợ quá trình phân tích, giám sát và khắc phục sự cố. Có nhiều cách để lưu và quản lý log, trong số đó có lẽ cách khá phổ biến là lưu trữ vào các file trên server.
Đối với các hệ thống, ứng dụng có quy mô nhỏ thì bạn hoàn toàn có thể lưu và quản lý log bằng file trên từng server, điều này là hoàn toàn khả thi. Tuy nhiên, khi hệ thống hay ứng dụng của bạn có quy mô và lượng người dùng truy cập lớn, với nhiều server được triển khai và các dịch vụ phân tán trên từng server, trong các server lại có các loại log khác nhau(frontend-access, frontend-error, nginx-access, nginx-error, apache, database,..) Thì việc lưu và kiểm tra log trên từng server không còn hiệu quả và khả thi nữa.
Ví dụ: Hệ thống của bạn đang triển khai dịch vụ web, và có 20 server phục vụ cho việc này. Trong trường hợp nào đó, bạn cần kiểm tra lại log, nhưng nếu bạn phải vào kiểm tra cục bộ từng server thì việc này sẽ tốn khá nhiều thời gian, công sức và cũng như không thật sự hiệu quả. Cần có một giải pháp nào đó cho việc này, và đó chính là phương pháp ghi log tập trung hay còn gọi là centralized logging.
2. EFK Stack:
Centralized logging
Centralized logging là phương pháp thu thập và lưu trữ log từ nhiều nguồn khác nhau tại một nơi trung tâm (centralized location) để dễ dàng quản lý và phân tích. Thay vì phải kiểm tra các tập tin log trên nhiều máy chủ khác nhau, các logs được gửi về một trung tâm chung, giúp cho quản trị viên có thể tìm kiếm và xem các logs từ nhiều nguồn trên cùng một giao diện đồng thời. Khi có sự cố xảy ra, quản trị viên có thể truy cập các logs này để phân tích và tìm ra nguyên nhân của vấn đề, giúp cho việc tìm kiếm và khắc phục sự cố trở nên dễ dàng và nhanh chóng hơn.
EFK Stack
EFK stack là một giải pháp quản lý và giám sát logs cho các ứng dụng và hệ thống phân tán. EFK tạo ra một môi trường giám sát log cho các ứng dụng của bạn bằng cách kết hợp các thành phần ElasticSearch, Fluentd và Kibana.
- ElasticSearch: là một nền tảng tìm kiếm và phân tích dữ liệu mã nguồn mở, được sử dụng để lưu trữ logs và dữ liệu tìm kiếm.
- Fluentd: là một công cụ thu thập logs đa nền tảng, có khả năng đồng bộ và gửi logs đến ElasticSearch.
- Kibana: là một ứng dụng web để truy vấn, xử lý và hiển thị dữ liệu logs lưu trữ trong ElasticSearch.
Với EFK stack, bạn có thể lưu trữ và xử lý logs từ nhiều nguồn khác nhau, xem và quản lý logs từ một giao diện đồ họa dễ sử dụng, đồng thời có khả năng tìm kiếm nhanh chóng và phân tích logs để giải quyết các vấn đề của hệ thống nhanh hơn.
Và kiến trúc cơ bản của EFK Stack như sau:
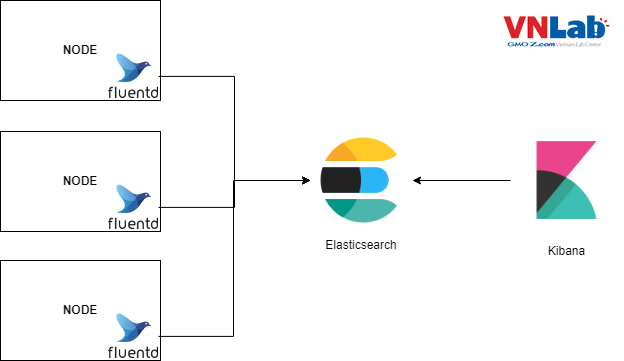
Có thể hiểu một cách đơn giản, fluentd sẽ được cài đặt trên các node để thu thập và gửi log đến Elasticsearch lưu trữ, trong khi đó Kibana sẽ chịu trách nhiệm show dữ liệu log đã được lưu vào Elasticsearch.
Trong nội dung của bài blog lần này tôi sẽ tập trung viết về Fluentd.
3. Fluentd:
Khái niệm
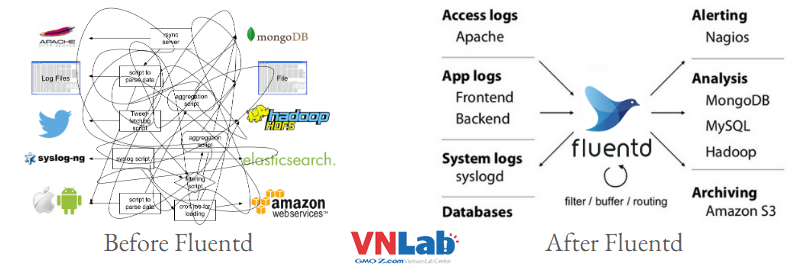
Fluentd là một công cụ thu thập logs mã nguồn mở được phát triển bởi Treasure Data. Nó hoạt động như một đầu vào hoặc phân phối logs, có khả năng thu thập logs từ nhiều nguồn khác nhau và chuyển chúng đến một đích như một hệ thống lưu trữ logs hoặc một ứng dụng phân tích logs như ElasticSearch hoặc Apache Kafka.
Fluentd có khả năng thu thập logs từ nhiều nguồn khác nhau như các tệp log, syslog, HTTP, TCP, UDP, các ứng dụng như Apache, Nginx, MySQL, hoặc các dịch vụ lưu trữ như Amazon S3, MongoDB, và nhiều hơn nữa. Đồng thời, nó cũng có khả năng xử lý và chuyển đổi các dòng logs đến định dạng chuẩn và đồng bộ logs tới các đích khác nhau một cách hiệu quả.
Fluentd được thiết kế để hoạt động với các ứng dụng và hệ thống phân tán, và có khả năng tự động phát hiện và đồng bộ hóa các dòng logs giữa các nút khác nhau trong mạng. Điều này giúp Fluentd trở thành một công cụ thu thập logs linh hoạt và mạnh mẽ cho các hệ thống và ứng dụng phân tán hiện nay.
Configuration
File cấu hình là thành phần cơ bản để kết nối tất cả mọi thứ lại với nhau, vì nó cho phép xác định Inputs hoặc listeners mà Fluentd sẽ có và thiết lập các quy tắc phù hợp chung để định tuyến dữ liệu Event đến một Output cụ thể.
File cấu hình Fluentd bao gồm các directives sau (source và match là các directives bắt buộc):
source: xác định các nguồn đầu vào.match: xác định đích đầu ra.filter: xác định các pipelines xử lý sự kiện. (không bắt buộc)system: thiếu lập cấu hình toàn hệ thống. (không bắt buộc)label: nhóm output và filter cho việc internal routing (không bắt buộc)worker: giới hạn cho các workers cụ thể (không bắt buộc)@include: include các file khác. (không bắt buộc)
Cấu hình Fluentd được sắp xếp theo thứ bậc. Mỗi directives có các plug-in khác nhau và mỗi plug-in có các tham số riêng. Có rất nhiều plug-in và tham số được liên kết với chúng. Trong bài viết lần này, chúng ta sẽ tìm hiểu về một vài chỉ chị trong số những cái thường được sử dụng và tập trung vào việc đưa ra các ví dụ.
Source
Đây là một ví dụ về phần source điển hình trong file cấu hình Fluentd:
<source>
@type tail
path /var/log/msystem.log
pos_file /var/log/msystem.log.pos
tag mytag
<parse>
@type none
</parse>
</source>Hãy xem xét từng thành phần:
@type tail - Đây là một trong những plug-in đầu vào Fluentd phổ biến nhất. Có các input plug-in tích hợp và nhiều loại khác được customized. Plug-in tail cho phép Fluentd đọc các sự kiện từ phần đuôi của tệp văn bản. Hành vi của nó tương tự như lệnh tail -f trong linux. Tệp được đọc được biểu thị bằng path. Fluentd bắt đầu từ dòng log cuối cùng trong tệp khi khởi động lại hoặc từ vị trí cuối cùng được lưu trữ trong pos_file. Bạn cũng có thể đọc tệp từ đầu bằng cách sử dụng tùy chọn read_from_head true trong source. Khi file log được rotate, Fluentd sẽ bắt đầu lại từ đầu. Mỗi plug-in đầu vào đi kèm với các tham số kiểm soát behavior của nó. Đây là tham số tail như đã nói ở trên.
tag cho phép Fluentd định tuyến log từ các nguồn cụ thể đến các đầu ra khác nhau dựa trên các điều kiện. Ví dụ: gửi log chứa giá trị compliance đến kho lưu trữ dài hạn (LTS) và log chứa giá trị stage đến kho lưu trữ ngắn hạn (STS).
Directive parse chịu trách nhiệm phân tích cú pháp, nằm trong directive source, mở ra một section định dạng. Đây là điều bắt buộc. Nó có thể được set là type null (như trong ví dụ của tôi) nếu không cần phân tích cú pháp. Đây là list bao gồm các built-in parsers. Bạn cũng có thể custom và thêm customized parser mong muốn.
Một trong những built-in parsers thường được sử dụng là multiline. Multiline logs là các dòng log được ghi lại trong nhiều dòng, thay vì chỉ trong một dòng duy nhất. Để xử lý đúng các log nhiều dòng, ta cần phải kết hợp các dòng đó lại với nhau thành một dòng hoàn chỉnh. Fluentd hỗ trợ xử lý các log nhiều dòng thông qua plugin multiline. Plugin này cho phép tái cấu trúc và định dạng log nhiều dòng thành một định dạng log mà chúng đại diện. Các quy tắc này được cấu hình trong file cấu hình của Fluentd.
Một ví dụ về cấu hình multiline sử dụng regex:
<source>
@type tail
path /var/log/msystem.log
pos_file /var/log/msystem.log.pos
tag mytag
<parse>
@type multiline
# Each firstline starts with a pattern matching the below REGEX.
format_firstline /^\d{2,4}\-\d{2,4}\-\d{2,4} \d{2,4}\:\d{2,4}\:\d{2,4}\.\d{3,4}/
format1 /(?<message>.*)/
</parse>
</source>Match
Trong Fluentd, match là một directive dùng để chỉ định các action sẽ được thực hiện trên các event data cụ thể. Các event data này sẽ được lọc bằng cách so sánh với các pattern được định nghĩa trong match. Nếu event data phù hợp với một pattern nào đó, Fluentd sẽ thực hiện các action được chỉ định trong match đó.
Ví dụ, nếu ta muốn gửi tất cả các event data có tag là web.server tới một Elasticsearch cluster, ta có thể định nghĩa như sau:
<match web.server>
@type elasticsearch
host localhost
port 9200
logstash_format true
</match>Trong đoạn cấu hình trên, match web.server định nghĩa một pattern cho các event data có tag là web.server. Sau đó, Fluentd sẽ thực hiện action để gửi các event data này tới một Elasticsearch cluster. Trong trường hợp này, action được chỉ định là @type elasticsearch và các thông số cấu hình của Elasticsearch cluster.
Fluentd cung cấp nhiều loại output plug-ins khác nhau cho match, cho phép người dùng xử lý các event data theo nhiều cách khác nhau, ví dụ như gửi tới một database, gửi tới một hệ thống xử lý real-time, lưu trữ trên đĩa, và nhiều hơn nữa.
Filter
filter trong Fluentd được sử dụng để xử lý, thay đổi và lọc các sự kiện trước khi chúng được gửi đến output. Các filter có thể được áp dụng trên một input hoặc trên một output hoặc giữa chúng.
Các filter có thể được áp dụng độc lập hoặc trong kết hợp để thực hiện các hoạt động như:
- Thay đổi cấu trúc dữ liệu: Thay đổi hoặc chuyển đổi định dạng dữ liệu của các sự kiện như JSON, CSV hoặc syslog.
- Tách các trường từ dữ liệu đầu vào: Chia nhỏ các trường dữ liệu thành các thuộc tính khác nhau.
- Thêm metadata vào sự kiện: Thêm thông tin về nguồn gốc và xử lý của sự kiện.
- Lọc các sự kiện không cần thiết: Lọc các sự kiện dựa trên nội dung của chúng.
- Thay đổi cấp độ độ ưu tiên: Thay đổi cấp độ độ ưu tiên của các sự kiện như log để đảm bảo xử lý ưu tiên hơn cho các sự kiện quan trọng.
- Phân tích dữ liệu: Thực hiện các hoạt động phân tích dữ liệu trên các trường dữ liệu như phân tích cú pháp hoặc phân tích thống kê.
Các filter thường được thiết lập trong phần cấu hình của Fluentd và có thể được kết hợp với các plugin khác để tăng tính linh hoạt và khả năng mở rộng của hệ thống logging.
<filter **>
@type record_transformer
@log_level warn
enable_ruby true
auto_typecast true
renew_record true
<record>
applicationName app
subsystemName subsystem
timestamp ${time.strftime('%s%L')} # Optional
text ${record.to_json} # using {record['message']} will display as txt
</record>
</filter>Đầu tiên, filter này được áp dụng cho tất cả các dữ liệu log (**), được xác định bởi directive <filter **>. Sau đó, filter sử dụng plugin record_transformer để chuyển đổi dữ liệu.
Đối với plugin record_transformer, directive @log_level được sử dụng để thiết lập mức độ log được hiển thị, trong đoạn cấu hình này là warn.
Directive enable_ruby được thiết lập là true để cho phép sử dụng cú pháp Ruby trong đoạn cấu hình. Directive auto_typecast được thiết lập là true để tự động chuyển đổi kiểu dữ liệu.
Để định dạng lại dữ liệu, filter sử dụng directive <record> để thiết lập các giá trị mới. Trong ví dụ này, filter sử dụng các giá trị mẫu để tạo ra các giá trị mới như applicationName, subsystemName, timestamp và text. Ví dụ sử dụng hàm strftime của Ruby để định dạng lại thời gian của log.
Cuối cùng, giá trị của dữ liệu log được định dạng lại bằng cách sử dụng to_json để chuyển đổi thành chuỗi JSON.
Tại thời điểm này, chúng ta đã có đủ kiến thức về Fluentd để bắt đầu khám phá một số tệp cấu hình thực tế.
File cấu hình ví dụ:
Dưới đây là file config fluentd để đọc log từ file có đường dẫn /fluentd/log/nginx/frontend_access.log, tái cấu trúc và gửi log này lưu vào server elasticsearch (sẽ có ví dụ cụ thể ở blog sau)
<source>
@type tail
path /fluentd/log/nginx/frontend_access.log
tag es.nginx-frontend.access
pos_file /fluentd/log/fluentd/es-nginx-frontend.access.log.pos
<parse>
time_format %d/%b/%Y:%H:%M:%S %z
expression /^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*) +\S*)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)"? "(?<agent>[^\"]*)")( "(?<http_x_forwarded_for>[^\"]*)")?( (?<request_time>[^ ]*))?$/
@type regexp
types request_time:float
</parse>
</source>
<filter es.nginx-frontend.access>
@type elasticsearch_genid
hash_id_key _hash
</filter>
<match es.nginx-frontend.access>
@type elasticsearch
host 192.168.33.52
port 9200
scheme http
logstash_format true
logstash_prefix nginx-frontend-access
type_name nginx-frontend-access
reload_connections false
reconnect_on_error true
reload_on_failure true
id_key _hash
remove_keys _hash
template_name nginx-frontend-access
template_file /fluentd/etc/es-index-template/nginx-frontend-access.json
include_timestamp
<buffer>
flush_interval 30s
flush_thread_count 4
</buffer>
</match>4. Tổng kết:
Qua phần 1 của EKF Stack, tôi đã giới thiệu về fluentd và giải thích 3 chỉ thị chính thường dùng trong fluentd. Trong các phần tiếp theo tôi sẽ tiếp tục viết về elasticsearch và kibana .
Tài liệu tham khảo:






