

Mục lục
- Physical AI là gì?
- Bên trong một robot có gì?
- Tại sao cần Simulation?
- Neural Network làm gì trong robot?
- Sim-to-Real và các mô hình AI hiện đại
- Thực hành: Chạy demo từ A-Z
- Kết luận
Physical AI là gì?
Physical AI là hệ thống AI có khả năng hiểu và tương tác với thế giới vật lý. Khác với AI truyền thống chỉ xử lý text hay ảnh, Physical AI phải:
- Hiểu vật lý: trọng lực kéo vật xuống, ma sát giữ vật không trượt, lực cần thiết để nâng một chiếc cốc.
- Hành động trong không gian 3D: di chuyển, nắm, đẩy, xoay vật thể.
- Phản ứng real-time: xử lý sensor data và ra quyết định trong mili-giây.
- Chịu được sai số: thế giới thực không hoàn hảo như mô phỏng.
Điểm khác biệt lớn nhất? Khi LLM trả lời sai, bạn chỉ cần hỏi lại. Khi robot hành động sai, nó có thể làm vỡ cốc, đổ cà phê - hoặc tệ hơn, gây nguy hiểm cho người xung quanh.
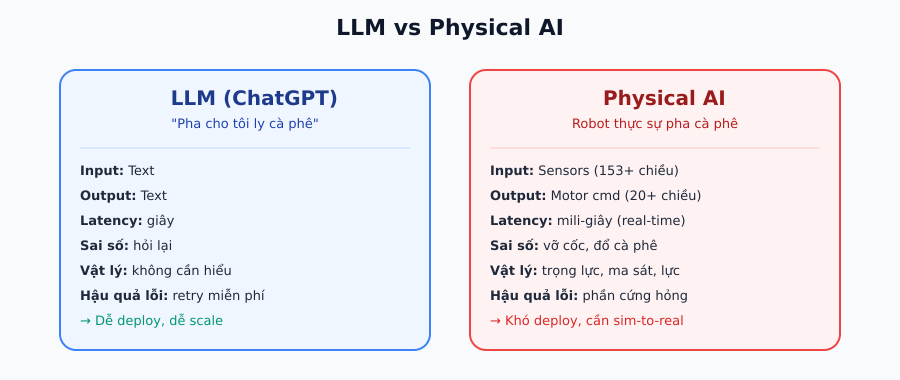
Bên trong một robot có gì?
Một robot về cơ bản gồm 3 thành phần chính:
1. Sensors (Cảm biến) - "giác quan" của robot. Encoder đo góc quay khớp, gyroscope đo vận tốc, cảm biến lực đo áp lực tiếp xúc, camera cung cấp hình ảnh. Ví dụ, bàn tay robot Shadow Dexterous Hand có 92 cảm biến xúc giác phân bố trên lòng bàn tay và các đốt ngón.
2. Brain (Bộ não) - một Neural Network nhận dữ liệu từ sensors và quyết định hành động tiếp theo. Đây chính là phần "AI" của robot.
3. Actuators (Cơ cấu chấp hành) - "cơ bắp" của robot. Motor nhận tín hiệu điều khiển và tạo ra chuyển động.
Một khái niệm quan trọng là Degrees of Freedom (DOF) - số chuyển động độc lập robot có thể thực hiện. Cánh tay người có 7 DOF, bàn tay người có khoảng 21-27 DOF (tuỳ cách đếm). Shadow Dexterous Hand mô phỏng bàn tay người với 24 DOF. DOF càng cao, robot càng linh hoạt nhưng bài toán điều khiển càng khó.
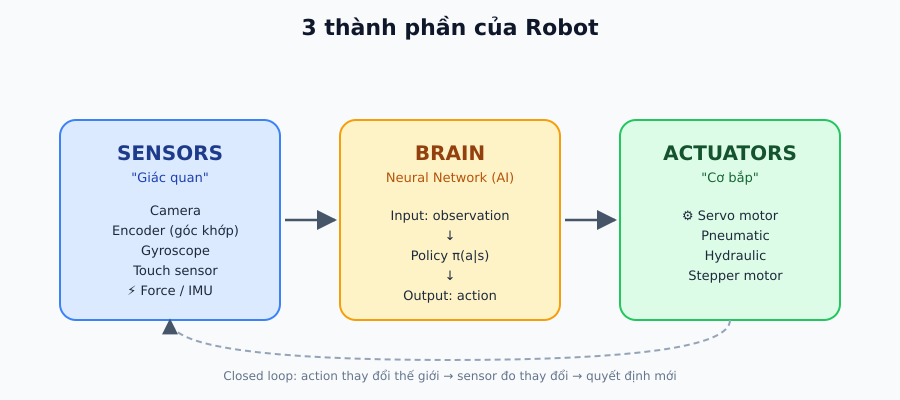
Tại sao cần Simulation?
Bạn không thể dạy robot bằng cách để nó thử-sai trên robot thật. Một robot công nghiệp giá $50k-$500k, mỗi lần thử sai có thể làm hỏng phần cứng hoặc gây nguy hiểm. Và để học được, agent cần hàng triệu lần thử.
Giải pháp: Simulation - mô phỏng toàn bộ robot và môi trường vật lý trên máy tính. MuJoCo (Multi-Joint dynamics with Contact) là physics engine phổ biến nhất; DeepMind mua lại năm 2021 và open-source dưới Apache 2.0 năm 2022.
Lợi ích simulation:
- Rẻ: máy tính chạy 24/7, không hỏng hóc.
- Nhanh: 1 ngày sim = hàng năm trải nghiệm thực.
- An toàn: robot có "chết" cũng chỉ là reset.
- Song song: chạy 1000 instance cùng lúc trên cluster.
Neural Network làm gì trong robot?
Vấn đề cốt lõi: robot nhận 153 con số từ sensors và cần đưa ra 20 con số điều khiển motor. Hàm nào ánh xạ từ observation sang action? Đó chính là Neural Network.
Ví dụ với môi trường Shadow Hand:
import gymnasium as gym
import gymnasium_robotics
gymnasium_robotics.register_robotics_envs()
env = gym.make("HandManipulateBlock_ContinuousTouchSensors-v1")
obs, _ = env.reset()
print(obs["observation"].shape) # (153,) ← 61 robot state + 92 touch
print(env.action_space.shape) # (20,) ← 20 motor commands
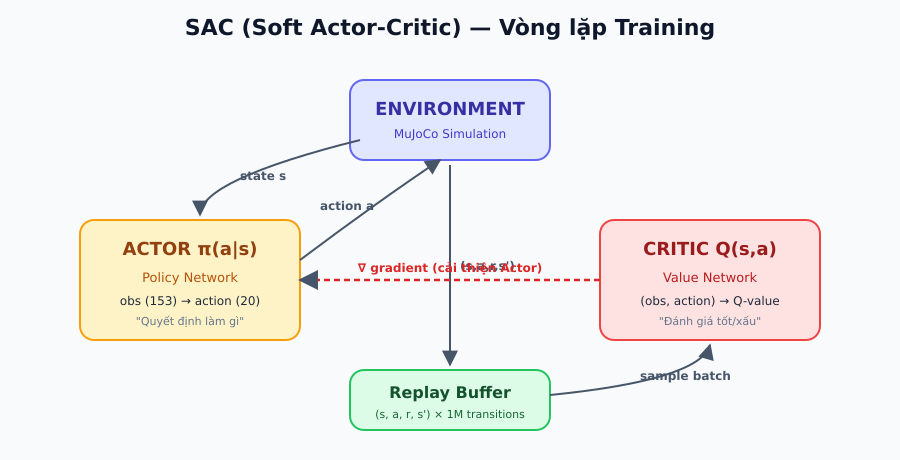
Trong thuật toán SAC (Soft Actor-Critic):
- Actor Network: nhận observation, trả về action - "đầu ra" của robot.
- Critic Network: đánh giá action tốt hay xấu - giúp Actor cải thiện.
Quá trình training lặp hàng nghìn lần: nhìn → chọn action → nhận reward → cập nhật weights. Sau khi train xong, chỉ cần Actor Network để điều khiển robot với inference ~0.5ms.
Sim-to-Real và các mô hình AI hiện đại
Sim-to-Real là gì?
Robot học rất giỏi trong simulation, nhưng đem ra đời thực thì... vấp. Lý do: simulation không bao giờ giống hệt thực tế — ma sát sàn khác chút, khối lượng vật lệch vài gram, motor phản hồi chậm hơn, ánh sáng camera thay đổi. Khoảng cách này gọi là sim-to-real gap. Policy học "vừa khít" với sim sẽ thất bại khi gặp những sai lệch nhỏ đó ngoài thực tế.
Sim-to-Real là bài toán chuyển policy từ simulation sang robot thật mà vẫn chạy tốt.
Giải pháp: Domain Randomization
Ý tưởng: thay vì train trong 1 thế giới sim cố định, ta random hoá tham số vật lý (ma sát, khối lượng, lực, độ trễ, ánh sáng) mỗi episode. Agent buộc phải học policy chạy được trên nhiều biến thể khác nhau — nên khi gặp thực tế (chỉ là một biến thể nữa), nó không bỡ ngỡ.
Ví dụ trực quan: thay vì luyện lái xe trên đúng 1 con đường, bạn luyện trên hàng nghìn con đường khác nhau — ra đường lạ vẫn lái được. OpenAI dùng cách này để giải Rubik's Cube bằng 1 tay robot (2019).
Các mô hình AI hiện đại
Mở rộng khả năng Physical AI:
| Hướng | Ý tưởng | Ví dụ |
|---|---|---|
| VLA (Vision-Language-Action) | Gộp camera + ngôn ngữ + action vào 1 model | π0, RT-2, NVIDIA GR00T |
| Diffusion Policy | Sinh cả chuỗi trajectory thay vì 1 action | Cải thiện trung bình 46.9% so với 2 baseline BC-RNN và LSTM-GMM trên 15 task benchmark |
| World Models | Dự đoán tương lai bằng video, robot "suy nghĩ" trước khi làm | NVIDIA Cosmos |
Tất cả các approach trên vẫn dựa trên 2 nền tảng cũ: RL + Simulation. Chỉ khác ở scale, data, và architecture.
Thực hành: Chạy một số demo cơ bản
Phần này hướng dẫn chạy thử các demo để thấy robot học trong simulation.
Yêu cầu hệ thống
| Mục | Yêu cầu |
|---|---|
| Python | 3.10+ |
| OS | macOS / Linux (Windows dùng WSL2) |
| Disk | ~2GB |
| GPU | Không bắt buộc (MuJoCo CPU-bound) |
Setup nhanh (1 lần)
# 1. Clone repo
git clone https://github.com/gmo-vietnamlab/lmt-physical-ai-001.git
cd lmt-physical-ai-001
# 2. Virtual env
python -m venv rl-env
source rl-env/bin/activate
# 3. Cài đặt
pip install "gymnasium-robotics[mujoco]" "stable-baselines3[extra]"
⚠️ Lưu ý: nếu chạy headless (server không GUI), thay
render_mode="human"thànhrender_mode="rgb_array"trong code demo.
Demo 1 — FetchReach (dễ, ~2 phút)
Robot Fetch di chuyển gripper đến một điểm mục tiêu 3D. Đây là baseline tốt để thấy RL hoạt động ngay.
# Bước 1: train
python demos/fetch_reach.py
# → chọn Option 1: Train FetchReach
# ============================================================
# DEMO 1: FetchReach (easy - solves 100%)
# ============================================================
# Task: move the gripper to the target point (red)
# Action: 4 dims (dx, dy, dz, gripper)
# Observation: 10 dims (gripper position + velocity)
# Training 20k steps...
# Done in 101s
# Result: success=100%, avg_reward=-1.1
# -> The agent learned to move the gripper to the target!
# Model saved: saved_models/fetch_reach_sac.zip
Kết quả mong đợi: success rate 100% sau ~20,000 steps. Bạn sẽ thấy robot từ "giật lung tung" (random) chuyển sang "di chuyển chính xác đến điểm đỏ".
# Bước 2: xem robot hoạt động (sau khi train xong)
python demos/fetch_reach.py
# → chọn Option 2: Render FetchReach (xem 3D)
# Render: FetchReachDense-v4
# Close the MuJoCo window to stop.
# 2026-06-05 15:57:44.632 Python[26682:7615390] +[IMKClient subclass]: chose IMKClient_Modern
# 2026-06-05 15:57:44.632 Python[26682:7615390] +[IMKInputSession subclass]: chose IMKInputSession_Modern
# Episode 1: OK reward=-0.5 (50 steps)
# Episode 2: OK reward=-1.5 (50 steps)
# Episode 3: OK reward=-1.9 (50 steps)
# Episode 4: OK reward=-0.7 (50 steps)
# Episode 5: OK reward=-1.6 (50 steps)
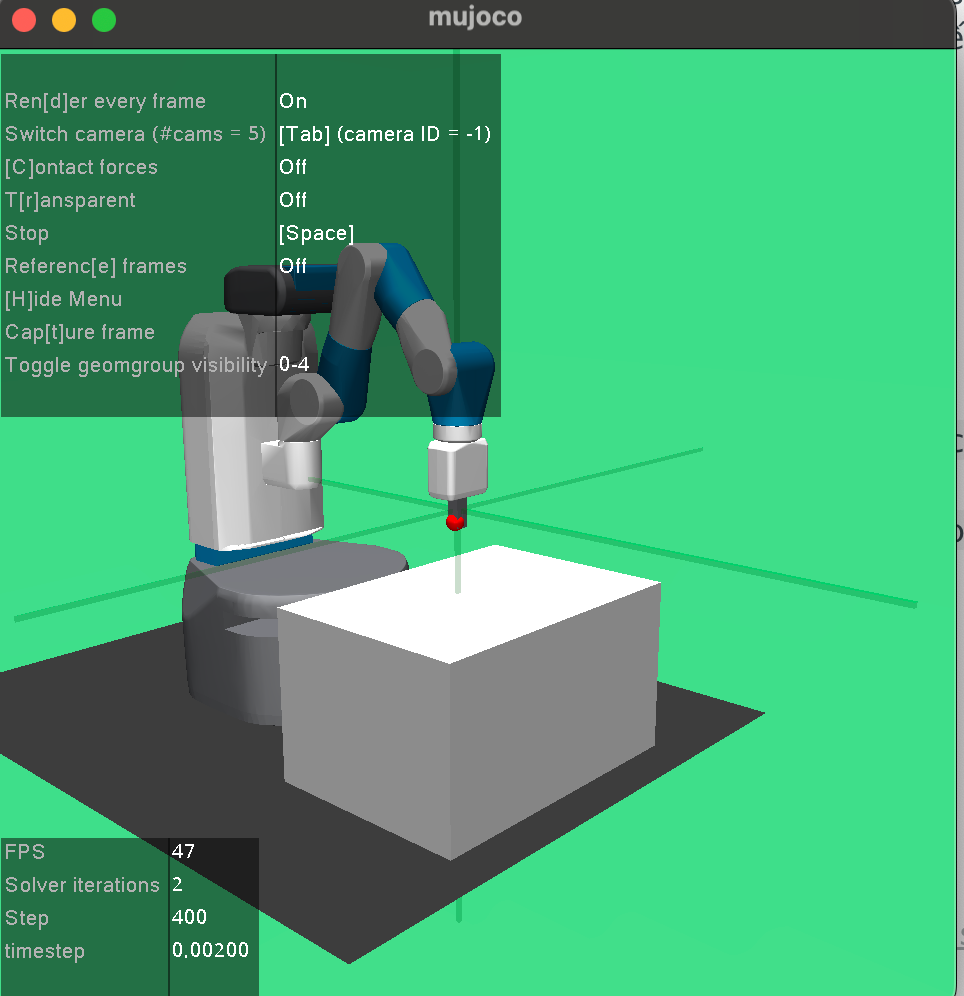
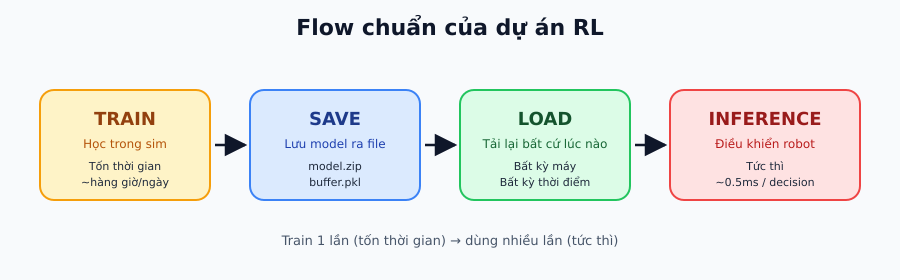
Đây là flow chuẩn của một dự án RL: Train → Save → Load → Inference:
Demo 2 — Shadow Hand với xúc giác (khó)
Môi trường phức tạp nhất - cùng loại robot OpenAI dùng giải Rubik's Cube.
Lưu ý: demo này chỉ render môi trường 3D với random actions để bạn cảm nhận độ phức tạp (24 DOF, 92 cảm biến xúc giác) — không train để đạt mục tiêu. Bàn tay sẽ cử động ngẫu nhiên, không "giải" được nhiệm vụ. Lý do: bài toán này cần hàng triệu steps + GPU, vượt phạm vi một demo nhanh.
python demos/manipulate_block_touch_sensors_example.py
# Option 1: Continuous Touch Sensors
Bạn sẽ thấy:
- Cửa sổ MuJoCo với bàn tay robot 24 DOF (24 khớp, 20 trong số đó actuated).
- 92 cảm biến xúc giác (hiển thị màu khi tiếp xúc).
- Observation 153 chiều = 61 robot state + 92 touch sensors.
- Action 20 chiều = 20 lệnh motor (mỗi motor điều khiển 1 actuated joint).
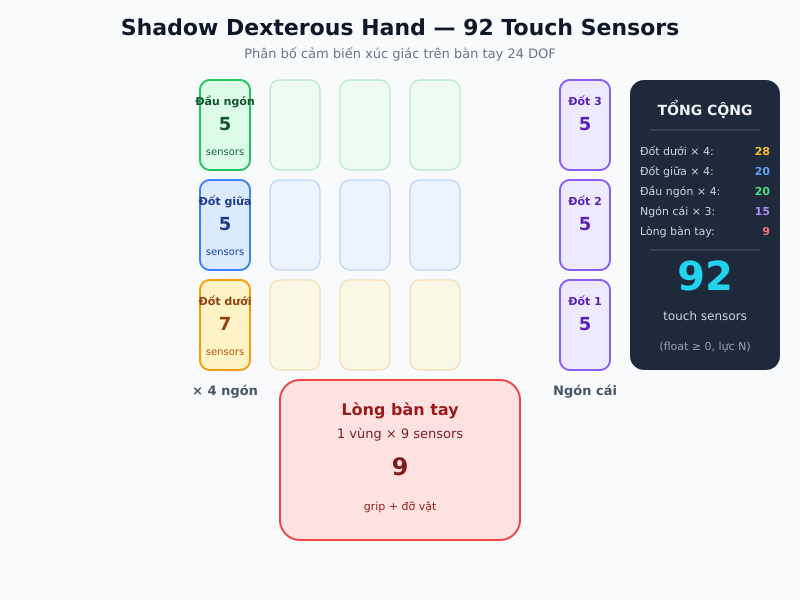
Phân bố 92 cảm biến xúc giác:
| Vùng | Số vùng | Sensors/vùng | Tổng |
|---|---|---|---|
| Đốt dưới (4 ngón) | 4 | 7 | 28 |
| Đốt giữa (4 ngón) | 4 | 5 | 20 |
| Đầu ngón (4 ngón) | 4 | 5 | 20 |
| Ngón cái (3 đốt) | 3 | 5 | 15 |
| Lòng bàn tay | 1 | 9 | 9 |
| Tổng cộng | 92 |
Mỗi sensor trả giá trị lực pháp tuyến (float >= 0). Bài toán này cần hàng triệu steps để solve - thể hiện độ khó thực sự của Physical AI.
Bảng đầy đủ options của fetch_reach.py
| Option | Mô tả | Thời gian |
|---|---|---|
| 1 | Train FetchReach - solve 100% (RL) | ~2 phút |
| 2 | Render trained model (xem 3D) | Tức thì |
| 3 | Reset (xoá saved model) | Tức thì |
Troubleshooting
- Render cần màn hình: chạy server headless → thay
render_mode="rgb_array"hoặc bỏ tham số. - Tốc độ training: ~175 steps/giây trên MacBook M-series. GPU không giúp nhiều cho MuJoCo (CPU-bound).
- FetchSlide không solve ngay: cần tổng ~300k-500k steps (option 2 khoảng 6-10 lần). Đây là bình thường.
- Warning
Overriding environment in registry: bỏ qua, không ảnh hưởng. - MuJoCo không hiện GUI trên Mac: thử
mjpython demos/...thay vìpython.
Kết luận
Physical AI đang ở giai đoạn bùng nổ. Nền tảng vẫn là RL + Simulation - đúng như những gì demo này thể hiện. Các approach hiện đại (VLA, Diffusion Policy, World Models) chỉ khác ở scale, data, và architecture - không phải paradigm mới.
Tương lai không xa, robot sẽ xuất hiện trong nhà bếp, nhà máy, bệnh viện - tất cả được "dạy" theo cách bạn vừa thực hành.






