

I. Giới thiệu
1. Vector Embedding là gì?
Vector embedding là một phương thức chuyển đổi các dạng dữ liệu thành số nhằm bóc tách ngữ nghĩa và quan hệ của chúng. Chúng biểu diễn các dữ liệu thành các điểm trong không gian đa chiều, các điểm gần nhau hơn sẽ giống nhau về ngữ nghĩa hơn.
2. Tại sao gọi là vector?
Dữ liệu sao khi chuyển thành dạng vector sẽ trở thành một mảng nhiều phần tử, mỗi phần tử đại diện giá trị cho 1 chiều, tương tự như một vector.
II. Lợi ích của định dạng vector
1. Ưu điểm so với các CSDL truyền thống
Các CSDL truyền thống (SQL, NoSQL) chỉ có thể tìm kiếm chính xác hoặc wildcard.
Hãy xét 1 ví dụ sau:
- Dữ liệu trong DB có câu sau: "This scientist is truly a genius guy"
- User nhập vào ô tìm kiếm "smart"
Với cách tìm kiếm của CSDL truyền thống sẽ không tìm được câu trên. Vector database (sử dụng vector embedding) sẽ tìm được.
Sở dĩ vector embedding làm được như vậy là vì vector embedding sử dụng thuật toán "tìm kiếm gần nhất" (approximate nearest neighbor - ANN).
2. Cách vector embedding tìm kiếm kết quả tương đồng
Chúng ta sẽ cùng nhau nhìn qua ví dụ sau để hiểu các thức vector embedding tìm kiếm các dữ liệu gần giống nhau.
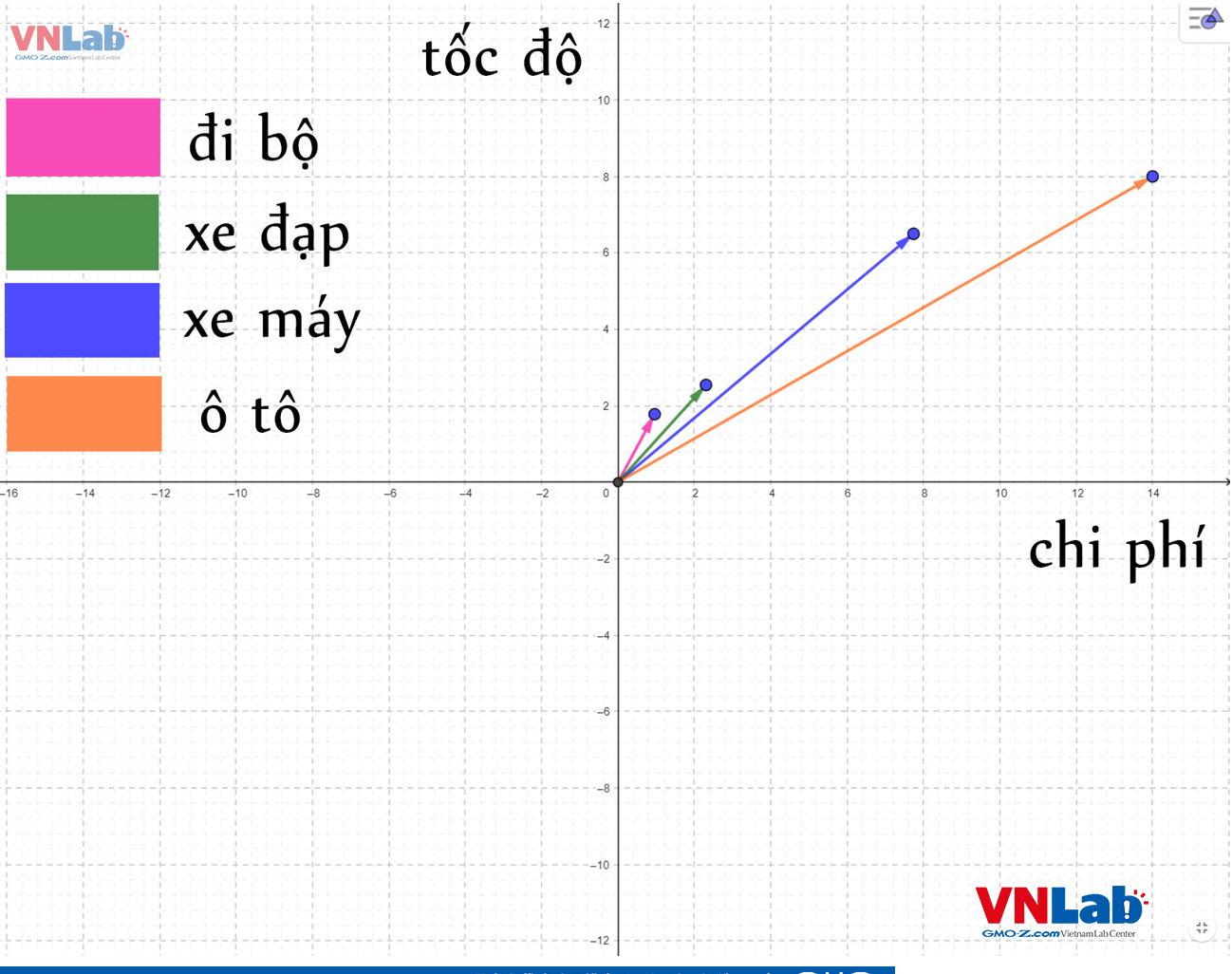
Hệ tọa độ ở hình trên có trục hoành đại diện cho chi phí, trục tung đại diện cho tốc độ.
Các phương thức di chuyển khác nhau sẽ có chi phí và tốc độ đi lại khác nhau.
Chúng ta dễ dầng nhận ra 2 vector "đi bộ" và "xe đạp" gần nhau vì cùng tốc độ chậm và chi phí thấp.
Để xác định khoảng cách giữa 2 vector, chúng ta có vài cách sau:
- Khoảng cách Euclidean
- Dot product
- Khoảng cách cosine (phương thức sẽ dùng trong bài viết này)
Khoảng cách cosine được tính bằng tích vô hướng của 2 vector. Kết quả trả về từ tích vô hướng cho biết độ tương đồng giữa 2 vector.
Kết quả này sẽ tỉ lệ thuận với độ tương đồng của 2 vector.
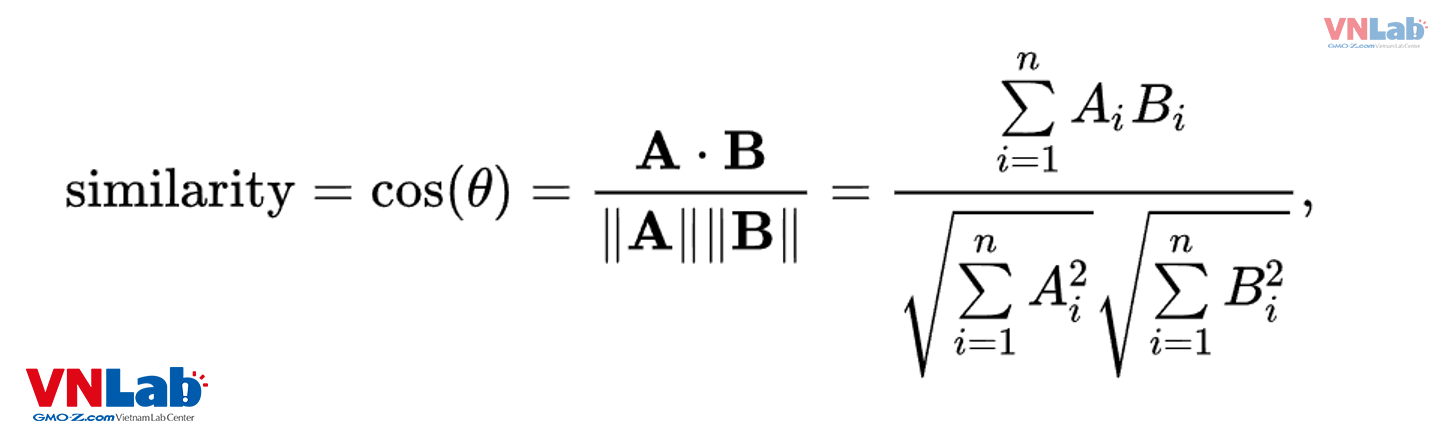
Trở lại với ví dụ phương tiện đi lại, sử dụng công thức tính tích vô hướng, chúng ta sẽ tính độ tương đồng giữa vector "đi bộ" với các vector còn lại:
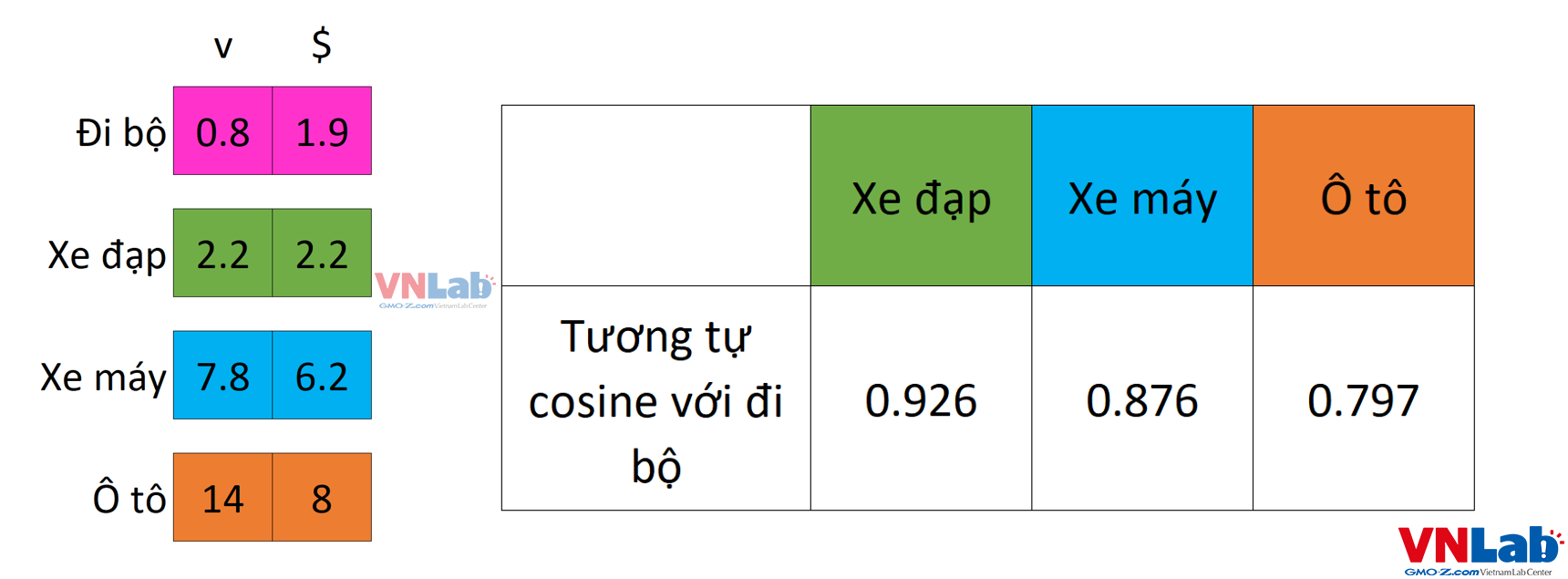
Như chúng ta có thể thấy, tích vô hướng giữa đi bộ và xe đạp có giá trị lớn nhất, hay nói cách khác "đi bộ" và "xe đạp" nằm gần nhau hơn trong không gian vector so với "xe máy" và "ô tô".
Đây chính là cơ sở để vector embedding lấy ra các kết quả tương đồng nhau.
3. Vector embedding trong thực tế
Trong thực tế, các vector sẽ có nhiều chiều hơn, trải dài từ vài trăm cho tới vài nghìn.
Số lượng chiều và ý nghĩa của chúng tùy thuộc vào mô hình LLD mà chúng ta chọn.
III. Thuật toán Hierarchical Navigable Small Worlds (HNSW)
1. Giới thiệu
HNSW là một thuật toán phổ biến dùng trong việc tìm kiếm gần nhất.
Các thuật toán tìm kiếm gần nhất được chia làm 3 phân loại:
- Cây - tree
- Băm - hash
- Đồ thị - graph
HNSW nằm trong phân loại đồ thị.
HNSW là sự kết hợp giửa 2 thuật toán con là skip list cùng với Navigable Small Worlds (NSW). Chúng ta sẽ lần lượt điểm qua 2 thuật toán này.
2. Skip list
Skip list được mô tả lần đầu vào năm 1989 bởi William Pugh. Thuật toán này cho phép tìm kiếm nhanh như tìm kiếm nhị phân trên mảng sắp xếp, nhưng áp dụng được cho danh sách liên kết.
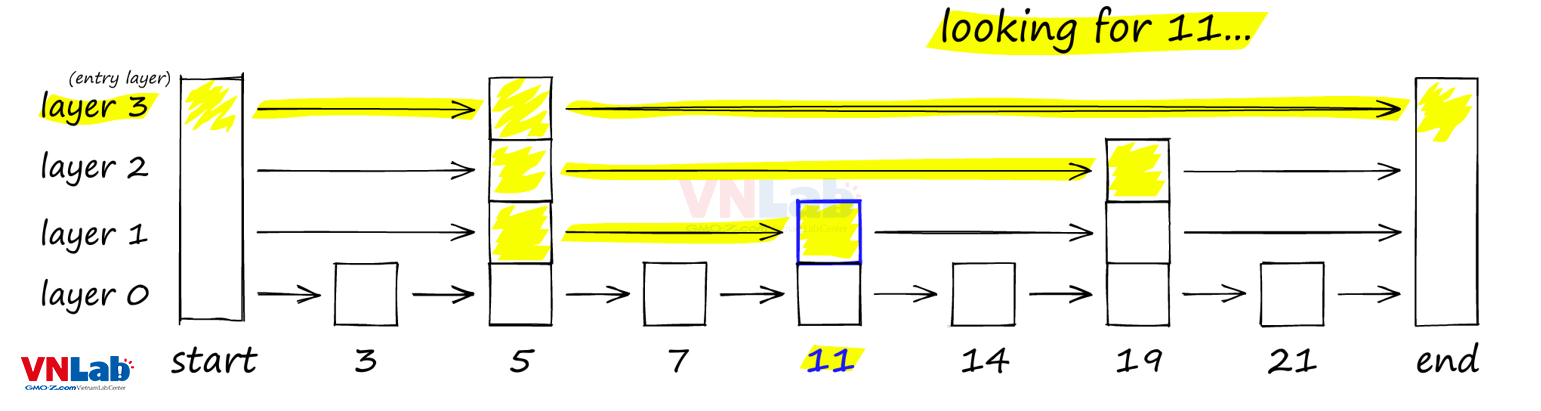
Theo hình trên, chúng ta có thể thấy được cấu trúc của một skip list bao gồm nhiều danh sách liên kết.
Danh sách liêt kết chứa tất cả các phần tử là level 0. Các danh sách ở level cao hơn sẽ chứa ít phần tử hơn.
Mỗi khi một phần tử được thêm vào danh sách (level 0), một thuật toán ngẫu nhiên sẽ được sử dụng để quyết định phần tử đấy có được thêm vào level cao hơn không.
Néu được thêm (trả về true), thuật toán ngẫu nhiên sẽ tiếp tục được sử dụng cho tới khi chúng trả về false thì thôi.
Càng lên level cao, số lượng phần tử càng ít.
Để tìm một phần tử k chúng ta sẽ thực hiện như sau:
- Xuất phát từ level cao nhất ở bên trái, so sánh với các phần tử trong cùng level từ trái sáng phải
- Xét phần tử n, nếu n < k -> tiếp tục di chuyển sang phải
- Nếu k < n hoặc không có phần tử kế tiếp nào thì sẽ di chuyển xuống level thấp hơn
- Lặp lại 2 bước trên cho tới tìm được phần tử bằng k ở level 0
- Nếu tìm được phần tử bằng k ở level 0, chúng ta coi như đã tìm ra k trong danh sách liên kết
Nếu cảm thấy vẫn còn khó hiểu, chúng ta có thể sử dụng công cụ demo trong trang web sau để có thể hiểu được skip list từng bước một: https://cmps-people.ok.ubc.ca/ylucet/DS/SkipList.html
3. Navigable Small Worlds (NSW)
NSW là thuật toán dùng để tìm kiếm dữ liệu gần nhất trên tập dữ liệu nhiều chiều.
Trong thuật toán này, mỗi một dữ liệu được xem như một điểm trên đồ thị.
Từ đây sẽ xây dựng lên liên kết giữa các điểm dữ liệu.
Mỗi điểm chỉ có thể liên kết tối đa M điểm.
Các liên kết bao gồm liên kết ngắn và liên kết dài, tạo thành 1 thế giới nhọ (small world).
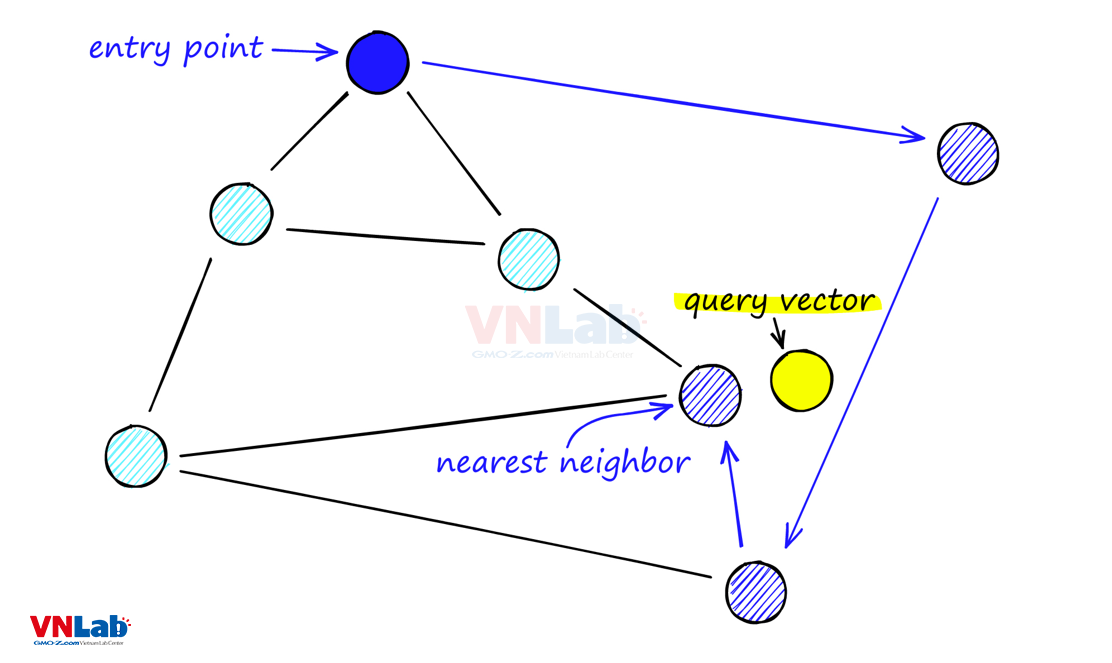
Xét với ví dụ trong hình trên, điểm màu vàng là dữ liệu/từ khóa nhập vào, điểm màu xanh đậm là xuất phát điểm cho quá trình tìm kiếm.
NSW là một thuật toán tham lam
- Tại điểm đang xét, nó sẽ duyệt qua tất cả các điểm liên kết, tính toán khoảng cách tới điểm màu vàng.
- Nếu điểm có khoảng cách gần nhất là điểm đang xét thì đấy chính là kết quả cần tìm
- Nếu điểm có khoảng cách gần nhất là 1 trong các điểm liên kết thì thuật toán sẽ nhảy tới điểm đấy và biến nó thành điểm đang xét.
- Lặp lại các bước trên cho tới khi tìm được kêts quả
Tuy vậy thuật toán này có một nhược điểm:
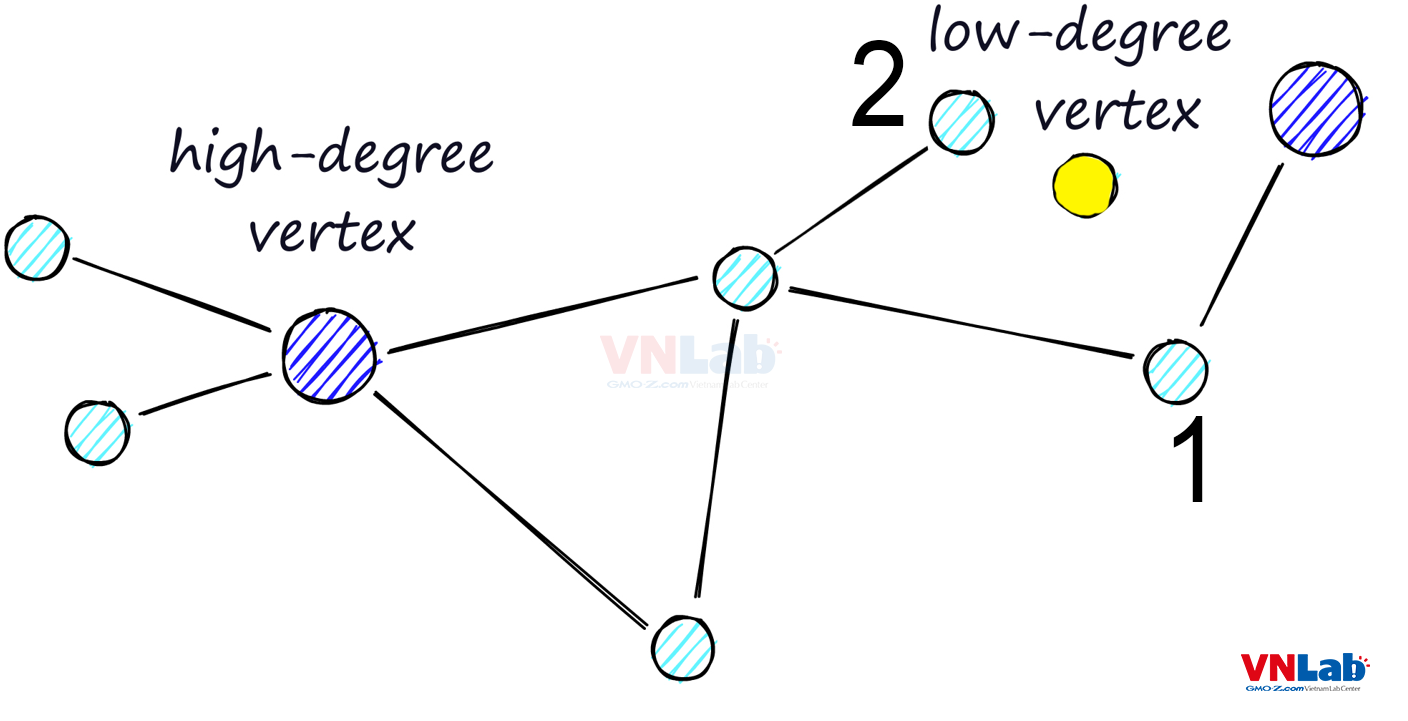
Trong thuật toán này, các điểm dữ liệu được chia làm 2 loại: điểm ít liên kết, điểm nhiều liên kết.
Nếu xuất phát điểm của việc tìm kiếm là điểm ít liên kết, thuật toán sẽ có nguy cơ dừng sớm và trả về kết quả chưa tối ưu.
Lí do là các điểm ít liên kết sẽ ít với tới được các điểm khác, từ đó tăng khả năng bỏ sót các điểm có khoảng cách gần hơn.
Trong hình trên, nếu xuất phát điểm là từ điểm xanh ở góc phải trên cùng, sử dụng NSW chúng ta sẽ đưa ra kết quả điểm 1 gần với câu truy vấn nhất, nhưng thực tế điểm 2 mới là điểm gần nhất.
HNSW
HNSW là một bước tiến hóa của NSW bằng cách kết hợp với Skip list.
Từ đồ thị điểm dữ liệu ban đầu, thuật toán sẽ tạo ra các level cao hơn. Các lớp level càng cao chứa càng ít điểm.
Các điểm được chọn thường có nhiều liên kết và tránh trùng lập các điểm chung với các lớp khác.
Quá trình tìm kiếm sẽ xuất phát từ lớp level cao nhất.
Việc tìm kiếm sẽ thực hiện tương tự như NSW, tuy nhiên khi đã tìm ra được điểm gần với dữ liệu truy vấn nhất, nó sẽ không dừng mà di chuyển xuống lớp thập hơn và tiếp tục thực hiện tìm kiếm cho tới khi tìm ra được điểm gần nhất ở level 0.
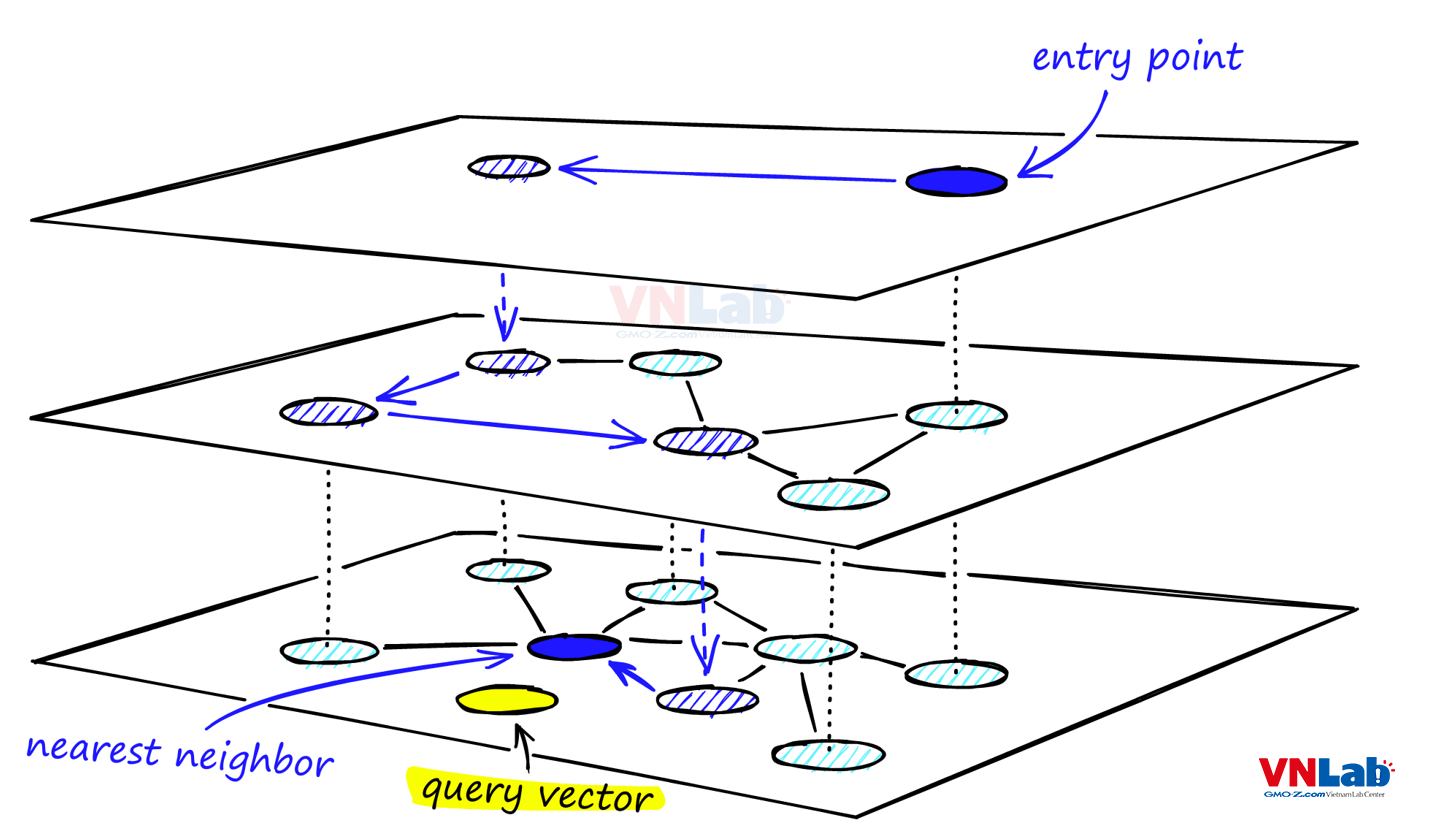
Việc tạo ra nhiều lớp như vậy sẽ giúp quá trình tìm kiếm bỏ qua các điểm có ít liên kết, từ đó giảm thiểu khả năng dừng sớm và trả về kết quả chưa đúng.
IV. Cách tạo Vector embedding
Chúng ta có thể sử dụng các mô hình LLM để sinh vector embedding.
Một số mô hình có thể kể tới như:
- UAE-Large-V1
- Cohere-embed-english-v3.0
- bge-small-en-v1.5
- text-embedding-ada-002 (chatGPT)
Có thể tham khảo ở trang sau để tìm được mô hình phù hợp: https://huggingface.co/spaces/mteb/leaderboard
V. Một số ứng dụng của vector embedding
Vector embedding sử dụng trong nhiều lĩnh vực khác nhau. Có thể kể tới:
- Hệ thống đề xuất (phim ảnh, sản phẩm, sách...)
- Tìm kiếm tương đồng (text, hình ảnh)
- Xử lý nhận dạng khuôn mặt/giọng nói
- Phát hiện giả mạo trong giấy tờ
VI. Demo
Sau đây sẽ là một ứng dụng nhỏ để thể hiện tính năng tìm kiếm tương tự của vector embedding.
Để tránh dài dòng, mục demo chỉ đề cập nhưng phần code chính, vì vậy sẽ không hiển thị hết file.
Các thư viện sử dụng
- nextjs 14 (tạo API)
- googleapis (dùng để lấy comment từ youtube)
- mysql2 và weaviate-ts-client: cơ sở dữ liệu vector
- Docker image build từ trang weaviate (phần demo sử dụng 2 model text2vec-transformers, img2vec-neural để tạo vector embedding)
Ứng dụng trong phần demo này: Tìm comment tương tự trên youtube
Tạo schema
src/app/api/schemas/route.ts
const client: WeaviateClient = weaviate.client({
scheme: 'http',
host: 'localhost:8080',
});
const commentSchemaConfig = {
class: 'Comment',
vectorizer: 'text2vec-transformers',
properties: [
{
name: 'content',
dataType: ['string'],
},
{
name: 'vector',
dataType: ['blob'],
moduleConfig: {
'text2vec-transformers': {
skip: false,
vectorizePropertyName: false,
},
},
},
],
};
const imageSchemaConfig = {
class: 'Image',
vectorizer: 'img2vec-neural',
vectorIndexType: 'hnsw',
moduleConfig: {
'img2vec-neural': {
imageFields: ['image'],
},
},
properties: [
{
name: 'description',
dataType: ['string'],
},
{
name: 'image',
dataType: ['blob'],
},
],
};
export async function POST(request: Request) {
const body = await request.json();
if (!body.schema) return new Response(JSON.stringify(false));
const schemaConfig =
body.schema === 'Comment' ? commentSchemaConfig : imageSchemaConfig;
await client.schema.classCreator().withClass(schemaConfig).do();
return new Response(JSON.stringify(true));
}
export async function GET(request: Request) {
const res = await client.schema.getter().do();
return new Response(JSON.stringify(res));
}
Chạy hàm POST để tạo 2 bảng Comment và Image.
Tiếp theo, chạy hàm GET của schema, chúng ta sẽ có được thông tin của database:
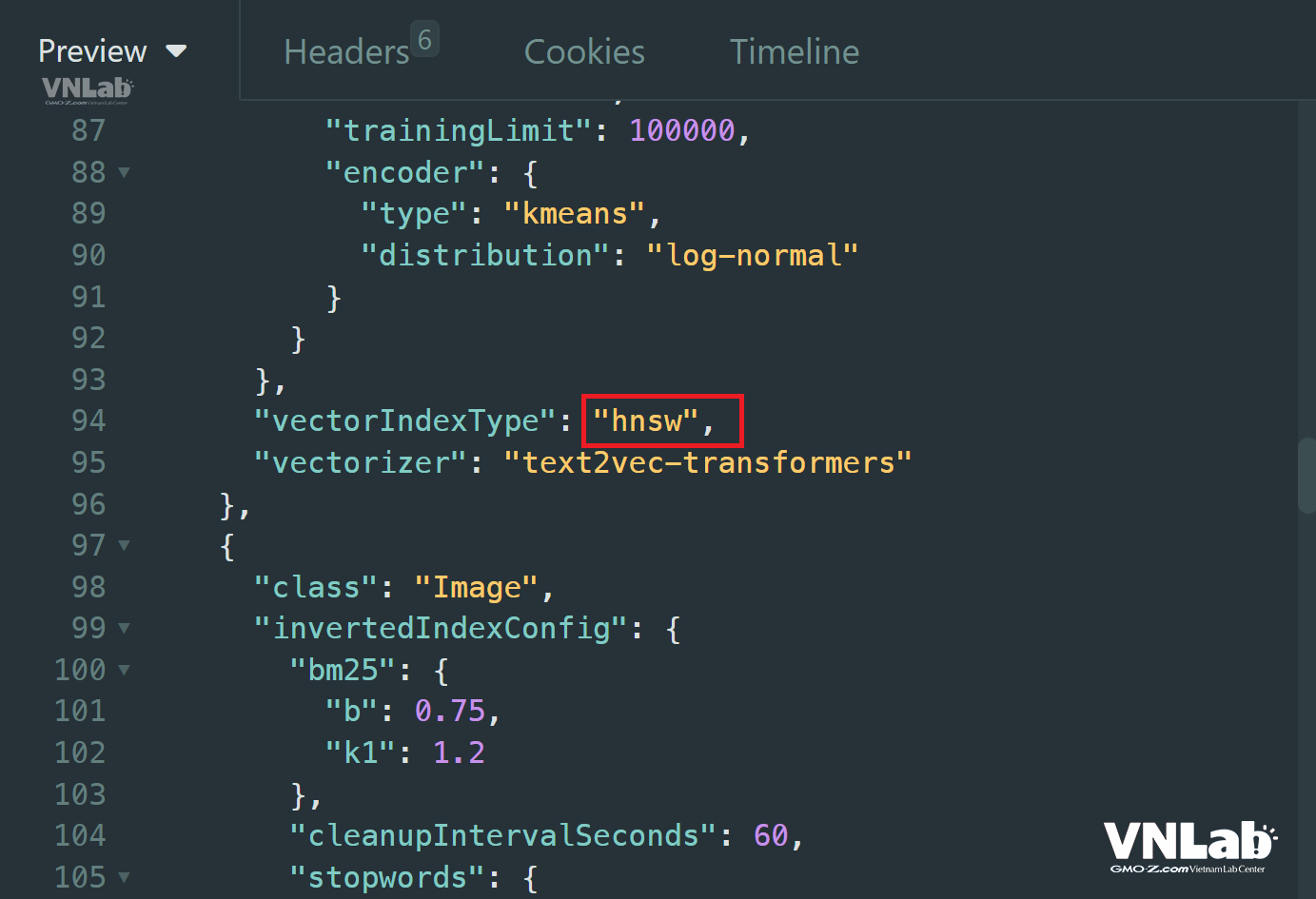
Từ kết quả trả về chúngt ta có thể thấy thuật toán sử dụng ở đây là HNSW.
export async function GET(request: Request) {
const { searchParams } = new URL(request.url);
const keyword = searchParams.get('keyword');
let result: any = null;
if (!keyword) {
return new Response(JSON.stringify(result));
}
const res = await client.graphql
.get()
.withClassName('Comment')
.withFields('content')
.withNearText({
concepts: [keyword],
distance: 0.9,
})
.withLimit(5)
.do();
return new Response(JSON.stringify(res.data.Get.Comment));
}
export async function POST(request: Request) {
const { searchParams } = new URL(request.url);
const id = searchParams.get('id');
const comments: string[] = [];
if (!id || id === '') return new Response(JSON.stringify(comments));
const res = await youtube.commentThreads.list({
part: ['snippet'],
videoId: id,
maxResults: 100,
});
if (!res || !res.data) return new Response(JSON.stringify(comments));
if (res.data.items) {
const promises = res.data.items.map(async (item) => {
const content = item.snippet?.topLevelComment?.snippet?.textOriginal;
if (!content) return;
comments.push(content);
await client.data
.creator()
.withClassName('Comment')
.withProperties({
content,
vector: Buffer.from(JSON.stringify(content)).toString('base64'),
})
.do();
});
await Promise.all(promises);
}
return new Response(JSON.stringify(comments));
}
Hàm POST sử dụng googleapi để lấy comment từ youtube từ video ID và lưu vào bảng Comment.
Các comment trải rộng trên nhiều lĩnh vực khác nhau như tôn giáo, ẩm thực, ngoại ngữ, lập trình, toán học...
Hàm GET lấy các comment tương tự với từ khóa truyền vào. Trong phần GET chúng ta chú ý đoạn này:
.withNearText({
concepts: [keyword],
distance: 0.9,
})
concepts chính là từ khóa truyền vào, distance là độ tương tự giữa từ khóa và kết quả trả về, giá trị càng cao kết quả càng giống nhưng ít hơn và ngược lại.
1. Với từ khóa "smart", kết quả trả về như sau:
[
{
"content": "Ruri...do you think that Japan 🇯🇵 are one of the smartest 🧠 nations in the world 🗺️?"
},
{
"content": "The amount of content in entertainment that is available to everyone is so vast and broad and different. Music, games, plays, movies, shows. Trying to find one and call it the \"best\" is wildly subjective and leads to endless debate. Entertainment exist and everyone is going to have a different level of attachment to the art because people value things differently will see things other people don't see. We should recognize what is good but calling something the \"best\" or a 10/10 perfect doesn't seem realistic to me."
},
{
"content": "Genius guy"
},
{
"content": "how can i make the search more accurate? Its not even using alot of processing power, is there a way to just set everything to high so it can use all my processing power to make sure the result is accurate?"
},
{
"content": "The bit labeled \"Machine Learning\" really should be \"Artificial Intelligence\" but otherwise well done!"
}
]
Chúng ta có thể thấy kết quả trả về có comment chứa từ khóa "smart", ngược lại có comment không chứa từ khóa nhưng vẫn hiện ra bởi độ tương tự gần giống (Genius guy).
2. Tìm kiếm với từ khóa "cuisine" (ẩm thực)
[
{
"content": "Now peasant food is McDonald’s lol"
},
{
"content": "Beautiful food. I'm impressed with the quality of the food they had at their stocks.. I don't eat that well in 2023. I'm jealous. I'd love to have a plate of the food you just showed. I'm hungry now"
},
{
"content": "This still echoes what I like to call the 'pottage myth' of the medieval peasant diet; at least they have salmon though. Consensus used to be that peasants hardly ever ate meat and that their diets consisted largely of thin gruel and pottage (I was taught this at school). A 2018 study of earthenware pots revealed that nothing could be further from the truth. They ate beef, mutton, fish when they could get it, game (rabbits, fowl; not venison though) and basically everything we eat with the notable exceptions of pig and potatoes."
},
{
"content": "This meal looks very delicious! Peasants may have had less access to many foods and had more simple diets compared to the upper classes, but simplicity does not automatically equate to blandness. I’m a university student working towards a history major, and I want to be a medievalist (someone who specializes in medieval history). This video is very informative and gives me a lot of insight into the lives of the commoners during the medieval times, including their diets."
},
{
"content": "Food?"
}
]






