
Mở đầu
Bài viết này tiếp nối từ bài viết trước về Exponential Smoothing.
Trong bài viết trước chúng ta dự đoán dữ liệu theo chuỗi thời gian không có xu hướng trend, và không có chu kỳ lặp đi lặp lại seasonality
Trong bài viết này chúng ta có 2 mục tiêu:
- Dự đoán dữ liệu theo chuỗi thời gian có trend không có seasonality, bằng Double Exponential Smoothing
- Tìm Parameter của Double Exponential Smoothing bằng Bayes Search.
Giới thiệu
Bài viết này chúng ta sẽ sử dụng dữ liệu bán dầu gội đầu trong vòng 3 năm.
https://www.kaggle.com/datasets/redwankarimsony/shampoo-saled-dataset
Sau khi download file xong, có thể dùng code dưới để xem dữ liệu trông như thế nào.
# Import các library cần thiết, nếu thiếu library, có thể dùng lệnh install ở bên cạnh
import pandas as pd #pip install pandas
import matplotlib.pyplot as plt #pip install matplotlib
import numpy as np #pip install numpy
import mango #pip install arm-mango
from statsmodels.tsa.holtwinters import ExponentialSmoothing #pip install statsmodels
shampoo_df = pd.read_csv("shampoo.csv")
shampoo_df.sort_values(by="Month", ascending=True)
shampoo_df.plot(x="Month", y="Sales", marker="o", figsize=(12, 5))
plt.title("Shampoo Data")
plt.grid()
plt.show()
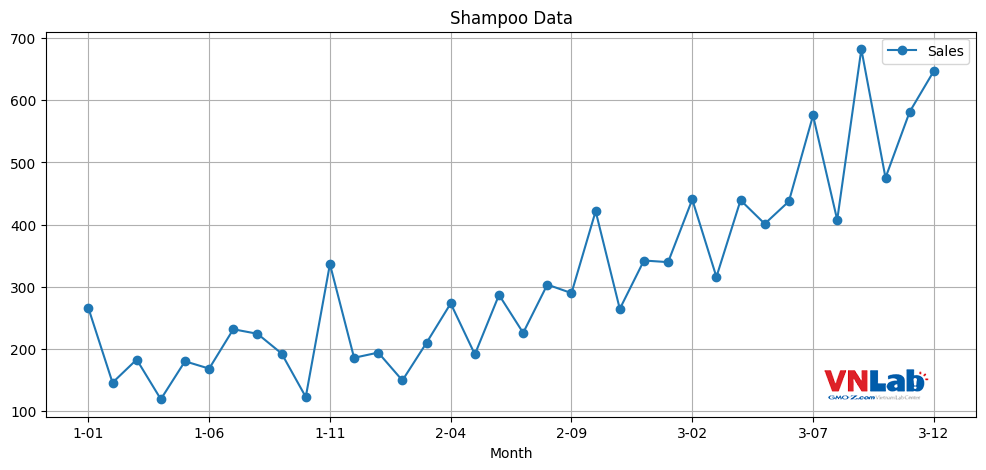
Hình 1: Dữ liệu số dầu gội đầu bán được theo thời gian. Trục X là thời gian theo Năm-Tháng. Trục Y là số dầu gội bán được
Có thể thấy số dầu gội đầu bán được có xu hướng tăng theo thời gian. Đặc biệt từ 2-04 (năm thứ 2 tháng 4) đến 3-12 (năm thứ 3 tháng 12), số dầu gội đầu tăng mạnh. Chúng ta gọi xu hướng của dữ liệu theo chuỗi thời gian này là trend.
Double Exponential Smoothing
Với dữ liệu thời gian có trend không có seasonality này, chúng ta không sử dụng được model Exponential Smoothing đơn giản như bài viết trước. Chúng ta sẽ sử dụng model Double Exponential Smoothing.
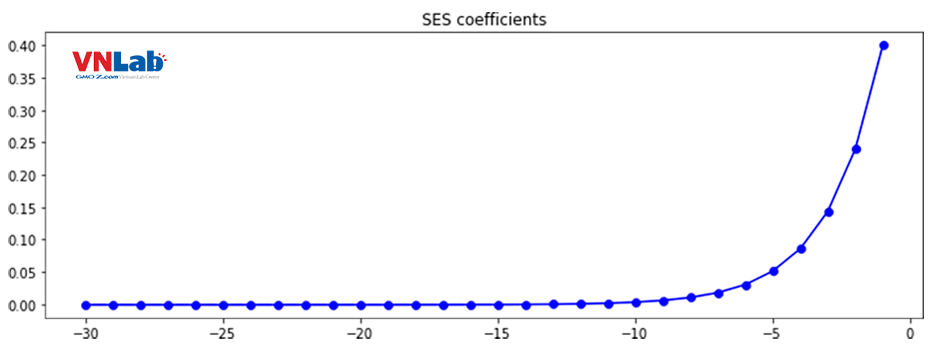
Đầu tiên hiểu sự khác nhau giữa công thức Single Exponential Smoothing và Double Exponential Smoothing:
Code
Chia dữ liệu test
Đầu tiên chúng ta chia dữ liệu train và test. Sử dụng 18 tháng đầu để model học (train), 18 tháng sau để kiểm tra xem kết quả dự đoán có đúng không (validation)
# Chọn 18 tháng cuối để kiểm tra dự đoán
test_months = 18
data = shampoo_df.reset_index()
train, validation = shampoo_df[:-test_months], shampoo_df[-test_months:]
len(train) # 18
len(validation) #18
Double Exponential Smoothing
Code dưới đây vừa học vừa đoán số dầu gội bán được theo từng tháng mới.
def multistep_run(param_dict):
history = train["Sales"].tolist()
predictions = []
for new_obs in validation["Sales"].values:
model = ExponentialSmoothing(history, **param_dict)
fitted_model = model.fit()
prediction = fitted_model.forecast(steps=1)
predictions.append(prediction[0])
history.append(new_obs)
return predictions
Chúng ta thử setting đơn giản. Dự đoán đường trend là đường thẳng (additive)
test_param = {
"trend":"add"
}
predictions = multistep_run(test_param)
Tính dự đoán sai với độ giá trị thức tế bao nhiêu bằng RMSE
from sklearn.metrics import mean_squared_error
rmse = mean_squared_error(predictions, validation["Sales"].values.tolist(), squared=False)
rmse # 85.3601899037886
Giá trị RMSE bằng 85 có nghĩa là trung bình mỗi dự đoán về số dầu gội đầu ở tháng tiếp theo đang sai trung bình là 85 sản phẩm.
Kiểm tra dự đoán và giá trị thật qua hình vẽ bằng code dưới
def check_prediction_line(predictions, truth_values, title):
result_data = np.array([predictions, truth_values]).T
result_df = pd.DataFrame(data=result_data, columns=["pred", "truth_values"])
fig, ax = plt.subplots(1, 1, figsize=(12, 5))
result_df.plot(ax=ax, marker="o")
plt.title(title)
plt.grid()
plt.show()
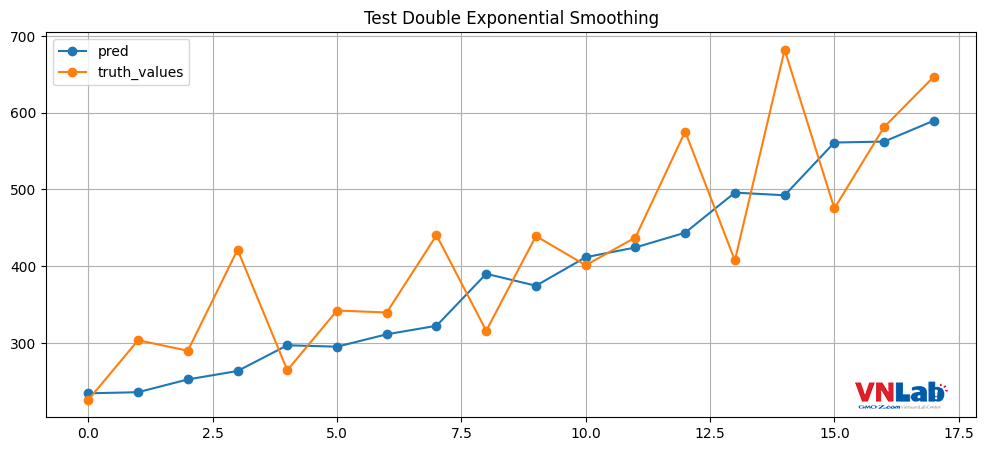
check_prediction_line(predictions, validation["Sales"].values.tolist(), "Test Double Exponential Smoothing")
Hình 2: Dự đoán của Double Exponential Smoothing với parameter tự đặt. Da cam là giá trị thật, xanh nước biển là giá trị dự đoán.
Có thể thấy với parameter tự đặt, dự đoán của chúng ta khá khớp với giá trị thật.
Bayes Search
Tiếp theo chúng ta sẽ sử dụng phương pháp tìm kiếm parameter cho model Double Exponential Smoothing gọi là Bayes Search. Nó sẽ cố gắng chọn parameter theo từng bước, để tìm hiểu các parameter ảnh hưởng đến RMSE như thế nào. Sau đó, Bayes Search sẽ tập trung vào chọn các tập hợp parameter để RMSE nhỏ nhất. Hiểu đơn giản, thay bằng đoán mò, Bayes search sẽ cố gắng thử nghiệm parameter một cách thông minh để giảm độ sai trong dự đoán.
Đầu tiên chúng ta định nghĩa objective function cho Bayes search, chúng ta tính RMSE cho từng parameter
def objective(list_parameters):
results = []
for param_dict in list_parameters:
try:
predictions = multistep_run(param_dict)
rmse = mean_squared_error(predictions, validation["Sales"].values.tolist(), squared=False)
results.append(rmse)
except:
print(f"Can't make model with parameter: {param_dict}")
results.append(float(9999999)) # Số nào đó rất to
return results
Chúng ta dùng thư viện mango để tune parameter. Các bạn có thể xem theo code và comment dưới
# liệt kê tất cả parameter model có thể sử dụng được.
param_space = {
"trend": ["add", "mul", None],
"damped_trend": [True, False],
#"seasonal": [None], # Không có seasonal
"use_boxcox": [True, False],
}
tuner = mango.Tuner(param_space, objective, {"num_iteration":8, "initial_random":1})
# Minimize để tối thiểu hóa RMSE dựa theo objective function
optimization_results = tuner.minimize()
Kết quả của Bayes search sẽ cho parameter đã được tối ưu hóa và RMSE của parameter đó
# Parameter tốt nhất
optimization_results["best_params"] # {'damped_trend': True, 'trend': 'mul', 'use_boxcox': False}
# RMSE của parameter
optimization_results["best_objective"] # 79.64718622067983
Giải thích qua về parameter tìm được:
'trend':"mul": sử dụng hàm số lũy thừa để tính trend cho model'use_boxcox':False: biến dữ liệu thành phân bố chuẩn sau đó tiến hành học hoặc dự đoán. Để độ lệch chuẩn của dữ liệu ổn định'damped_trend': True: Nếu tính trend thì các time step sau giá trị sẽ lớn quá. Sử dụng damped_trend sẽ khiến tốc độ tăng chậm lại.
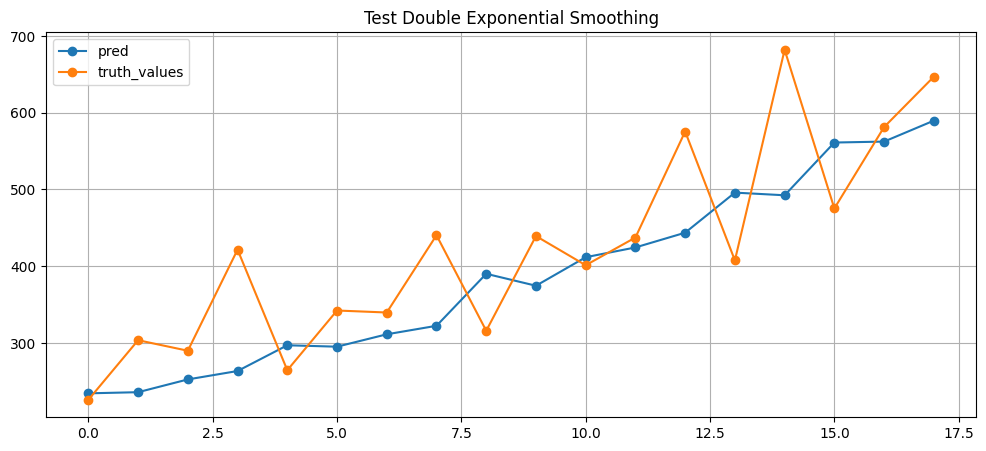
Bayes Search giảm từ độ sai trung bình 85 sản phẩm mỗi dự đoán của tháng xuống gần 80 sản phẩm. Nếu nhìn dự đoán mới sẽ không thấy khác nhiều. Về mặt lý thuyết, nếu đường trend sử dụng "mul" thay bằng "add" thì sẽ có đường dự đoán cong hơn
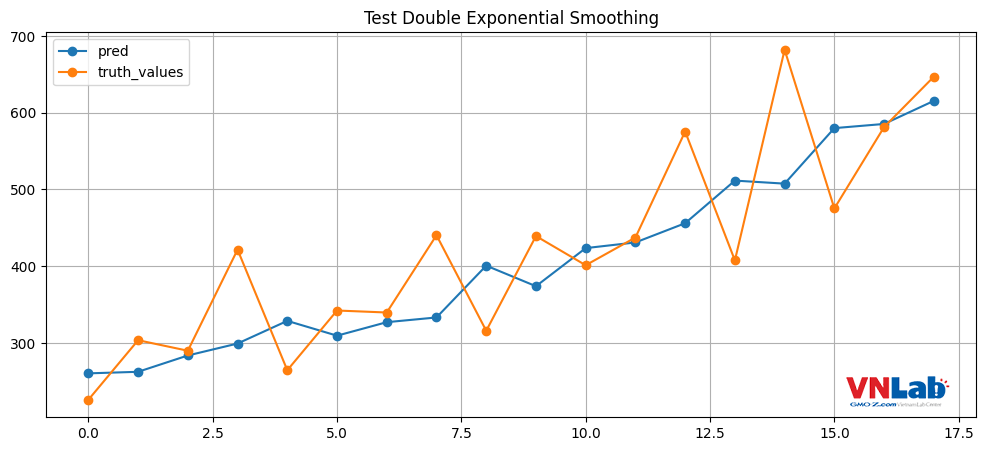
Hình 3: Dự đoán của Double Exponential Smoothing trên parameter đã được tối ưu hóa. Da cam là giá trị thật, xanh nước biển là giá trị dự đoán.
Kết luận
Với số lượng ít parameter như thế này, ta cũng có thể sử dụng Grid Search để kiểm tra tất cả parameter. Tuy nhiên, với dữ liệu nhiều và với model phức tạp với nhiều parameter hơn (như Triple Exponential Smoothing), thì Grid Search sẽ tốn nhiều CPU.
Như thấy ở trên chúng ta có thể tối ưu hóa model Exponential Smoothing bằng Bayes Search để tiết kiệm thời gian và CPU. Tuy nhiên, cũng nên biết là parameter tìm được sẽ đưa kết quả tương đối, không phải là parameter tốt nhất.
Reference
- https://machinelearningmastery.com/exponential-smoothing-for-time-series-forecasting-in-python/
- https://machinelearningmastery.com/how-to-grid-search-triple-exponential-smoothing-for-time-series-forecasting-in-python/
- https://towardsdatascience.com/mango-a-new-way-to-make-bayesian-optimisation-in-python-a1a09989c6d8






