

Mở đầu
Trong bài blog này, chúng ta sẽ cùng tạo một model CNN bằng pytorch để phân loại ảnh chữ cổ của Nhật: Kuzushiji. Nếu bạn nào biết về dataset phân loại ảnh(số từ 0-9) MNIST, thì đây cũng là dataset tương tự tên là KMNIST. Chúng ta sẽ không phân loại hết tất cả chữ, mà chỉ 10 chữ cái Kuzushiji trong đó thôi.
Các bạn có thể băn khoăn tại sao ta không dùng dataset MNIST trực tiếp cho đơn giản. Tại vì phân loại MNIST đã được viết đến nhiều, phân loại Kuzushiji sẽ thú vị hơn.
Các bạn đọc nên có các kiến thức dưới. Nhưng nếu chỉ muốn implement thử CNN bằng trong pytorch thì không cần thiết.
- Neural Network và Neural Network học như thế nào
- Convolutional Neural Network
Nhiều code trong bài sẽ được dựa vào bài viết trước về Pytorch. Các bạn có thể xem ở Pytorch cơ bản Phần 1: Linear Regression
Giới thiệu về Kuzushiji

Hình 1: Kuzushiji. Source: [Kaggle](https://www.kaggle.com/c/kuzushiji-recognition/overview/about-kuzushiji)
Kuzushiji là chữ viết cổ được sử dụng ở Nhật hơn 1000 năm, hiện giờ không được sử dụng ở Nhật. Chỉ có 0.01% người Nhật có thể đọc được các chữ này. Dataset KMNIST được bắt nguồn từ Kuzushiji Dataset. Dataset Kuzushiji được chắt lọc từ sách và tài liệu cổ của bên Nhật. Một mục đích là qua học máy, dịch được các tài liệu từ tiếng Nhật cổ sang tiếng Nhật hiện đại để hiểu hơn về văn hóa thời xưa. Điểm lưu ý là KMNIST sẽ chỉ có 10 chữ cái, không phải toàn bộ chữ Kuzushiji
Download và process dữ liệu
Như bài viết trước tôi khuyến khích các bạn sử dụng Jupyter Notebook để thực hành cùng. Đầu tiên ta sẽ import các thư viện sau:
import torch
import torchvision
import matplotlib.pyplot as plt
from torchvision import transforms
Các bạn nên tạo trước folder ./data tại nơi định thực hành.
Tiếp đó có thể sử dụng thư viện để trực tiếp download data Train và Test cho Kuzushiji (KMNIST).
transforms.ToTensor() được dùng để chuyển dữ liệu ảnh và label download về dạng Tensor trong Pytorch.
train_dataset = torchvision.datasets.KMNIST(
root="./data/KMNIST",
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.KMNIST(
root="./data/KMNIST",
train=False,
transform=transforms.ToTensor(),
download=True)
Tìm hiểu KMNIST có bao nhiêu dữ liệu:
print("Train dataset size: %d" % len(train_dataset))
print("Test dataset size: %d" % len(test_dataset))
# Train dataset size: 60000
# Test dataset size: 10000
Lần này, thay bằng cho model train tất cả dữ liệu một lúc. Ta sẽ tạo loader, để model train 32 ảnh một lần, cho đến khi hết dữ liệu.
batch_size = 32
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
test_dataloader = torch.utils.data.DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=2
)
classes = ["o", "ki", "su", "tsu", "na", "ha", "ma", "ya", "re", "wo"]
Trước hết chúng ta nên kiểm tra dữ liệu trông như thế nào.
# map từ label sang chữ tiếng nhật
labels_map = {
0:"o",
1:"ki",
2:"su",
3:"tsu",
4:"na",
5:"ha",
6:"ma",
7:"ya",
8:"re",
9:"wo"
}
# Vẽ chữ cái và label dưới dạng 3x3
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
# Lấy index ngẫu nhiên
sample_idx = torch.randint(len(train_dataset), size=(1,)).item()
# Lấy dữ liệu ngẫu nhiên bằng index
img, label = train_dataset[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
# Vẽ ảnh
plt.imshow(img.squeeze(), cmap="gray")
plt.show()

Hình 2: Dữ liệu Kuzushiji
Từ Hình 2, có thể thấy dữ liệu sẽ có:
- Ảnh tiếng nhật
- Label của chữ tiếng Nhật dưới dạng text
Nếu bạn đã học Hiragana, sẽ nghĩ là chữ viết trên hơi lạ. Tuy nhiên đó không phải vì dữ liệu sai. Kiểm tra lại ví dụ, thật sự là cùng một chữ thời xưa có nhiều kiểu viết.
Vì cùng một label có nhiều kiểu viết với ít sự tương đồng, model có thể ghi đè, hoặc tìm cách phân biệt các feature nó vừa học trong quá trình training. Đồng thời có một số nét viết trong ảnh bị thiếu, không rõ, hay thừa cũng ảnh hưởng đến model học từ ảnh. Model có thể gặp khó khăn trong việc học.

Hình 3: Hiragana và Kuzushiji
Tạo Model
Model lần này sử dụng CNN để train với ảnh. Phức tạp hơn Linear Regression của lần trước.
Đầu tiên thử kiểm tra xem máy của bạn có GPU hay CPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
# Nếu GPU: device(type='cuda')
# Nếu CPU: device(type='cpu')
Nếu có GPU thì có thể train thoải mái. Nếu CPU thì có thể hạn chế số vòng lặp (epoch) khi train để máy tính đỡ phải làm việc nặng quá.
Bài viết sẽ không giải thích kĩ về CNN và Dropout. Nên các bạn có thể đọc về
- CNN tại link này: https://topdev.vn/blog/thuat-toan-cnn-convolutional-neural-network/#:~:text=Mạng CNN là một tập,cho các lớp tiếp theo.
- Dropout tại đây: https://viblo.asia/p/ky-thuat-dropout-bo-hoc-trong-deep-learning-XL6lAd8BZek
Kể cả nếu không hiểu, bạn có thể tiếp tục code thử và quay lại để nghiên cứu kỹ sau. Chúng ta sẽ chỉ tập trung vào implement code CNN bằng Python trong bài blog này.
Code của CNN sẽ như dưới:
class CustomCNN(torch.nn.Module):
def __init__(self):
super(CustomCNN, self).__init__()
self.cnn_layers = torch.nn.Sequential(
# Convolutional Layer. 64 filter
torch.nn.Conv2d(1, 64, kernel_size=5, stride=1, padding="valid"),
# Relu layer sau convolution
torch.nn.ReLU(),
torch.nn.Conv2d(64, 128, kernel_size=3, padding="valid"),
torch.nn.ReLU(),
# Bỏ bớt 10% output từ filter layer trước
torch.nn.Dropout2d(0.1),
# Max pooling 2x2
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(128, 256, kernel_size=3, padding="valid"),
torch.nn.ReLU(),
torch.nn.Dropout2d(0.1),
torch.nn.MaxPool2d(3),
# Từ kết quả neuron phân bố 2D thành 1D
torch.nn.Flatten(start_dim=1, end_dim=-1),
# Bắt đầu layer Fully Connected của Neural Network bình thường
# Số 2304 này được lấy bằng việc chạy thử CNN trước và xem lỗi cần số input neuron của layer là bao nhiêu. Có thể tự tính, nhưng phức tạp hơn. Có thể sử dụng nn.LazyLinear để không cần quan tâm đến số input neuron
torch.nn.Linear(2304, 256),
torch.nn.ReLU(),
# Bỏ 10% neuron ngẫu nhiên.
torch.nn.Dropout(0.1),
torch.nn.Linear(256, 10),
# Layer output dự đoán ảnh thuộc label nào
torch.nn.Softmax()
)
def forward(self, X):
# Giống với bài blog trước về Linear Regression
# Chạy toàn bộ layer
result = self.cnn_layers(X)
return result
Tôi sẽ tóm tắt đơn giản để đủ hiểu về các layer trong code trên. Tôi sẽ bỏ qua giải thích về các argument của từng layer. Nếu các bạn hiểu kỹ về CNN thì có thể skip phần này.
torch.nn.Conv2d(Convolutional Layer): Input là ảnh 2D. Khi học, Neural Network sẽ cố tìm các tính chất gọi là filter (đường dọc, ngang, chéo phải...) của ảnh. Output là các ảnh trừu tượng tạo bởi các filter này.

Hình 4: Ví dụ filter của ảnh. Source: https://medium.com/neuronio/does-cnn-learns-modified-inputs-bc16ae1be498
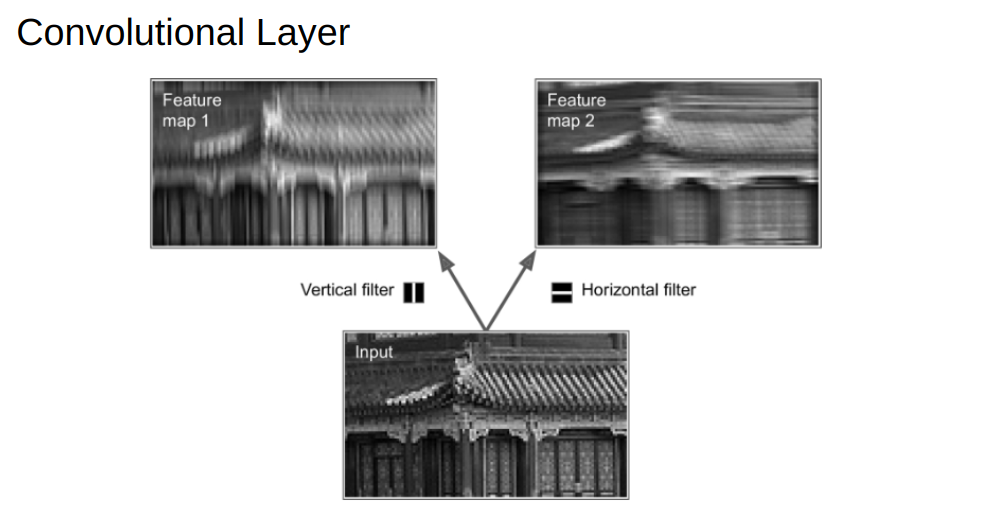
Hình 5: Ảnh output trừu tượng tạo bởi áp dụng filter*
torch.nn.ReLU: Layer sử dụng function ReLU, mô phỏng tín hiệu trong Neuron của não người. Nó được sử dụng trong từng Neuron của Neural Network. Các Neuron phối hợp để học từ lỗi sai và đưa ra dự đoán.
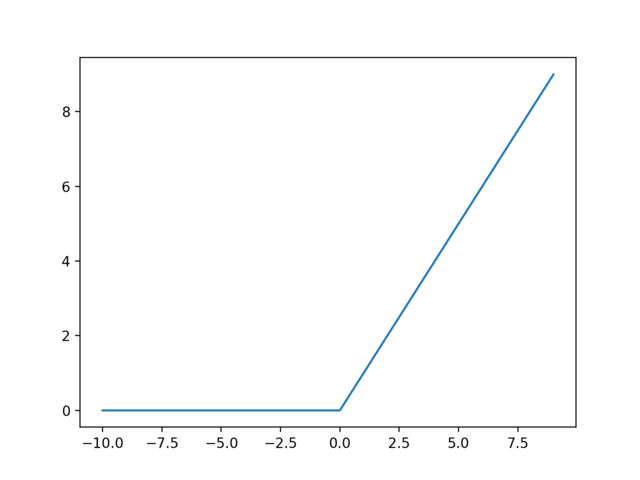
Hình 6: Function ReLU. Source: https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/
torch.nn.Dropout2dvàtorch.nn.Dropout: Bỏ một số Neuron trong Neural Network. Model có thể cố tình bỏ qua một số chi tiết trong ảnh khi học. Giúp model dự đoán tốt cho ảnh trông hơi khác với những ảnh đã học rồi (giảm overfit).torch.nn.MaxPool2d: Làm nhỏ ảnh và chỉ giữ những tính chất tiêu biểu, quan trọng nhất của ảnh. Giảm số neuron, giúp Neural Network học và dự đoán được nhanh hơn.torch.nn.Flatten: Layer để biến layer Neuron từ dạng 2D về 1D. Để sau có thể sử dụng layertorch.nn.Lineargiống Neural Network cơ bản.torch.nn.Linear: giống với Linear Regression trong bài Blog trước. Tính giá trị tổng input nhân với weight.torch.nn.Softmax: trong bài toán này, layer cuối đưa ra 10 Neuron. Mỗi Neuron tương ứng với một label của chữ (o, ki, su...). Neuron có giá trị càng cao, có nghĩa là Neural Network càng chắc chắn ảnh thuộc về label đó.
Truyền model CNN cho GPU hoặc CPU
cnn = CustomCNN()
cnn = cnn.to(device)
Định nghĩa Loss Function và Optimizer để bắt đầu train:
loss_fn = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=cnn.parameters(), lr=0.001, weight_decay=0.001)
Chúng ta sử dụng Cross Entropy Loss cho bài toán phân loại có nhiều class (>2). Ở đây, ta có 10 class như dưới nên sử dụng loại loss này:
classes = ["o", "ki", "su", "tsu", "na", "ha", "ma", "ya", "re", "wo"]
Train CNN
Chúng ta tạo vòng lặp để train model như sau. Các bạn có thể tham khảo comment để hiểu kĩ hơn:
# 1 epoch là 1 lần model train toàn bộ dữ liệu
epochs = 6
for epoch in range(1, epochs + 1):
correct = 0
total_loss = 0
# Từ Dataloader định nghĩa ở trên, ta sẽ lấy 32 ảnh và 32 labels.
for X, y in train_dataloader:
# Chuyển dữ liệu này cho GPU hoặc CPU
# X là ảnh, y là label
X = X.to(device)
y = y.to(device)
# Thử đưa 32 ảnh cho model CNN để dự đoán
# Kết quả là cho mỗi ảnh có 10 xác xuất (tương ứng với 10 labels), xác xuất càng cao thì model càng chắc chắn về dự đoán
pred_y = cnn(X)
# Tính Cross Entropy Loss dựa vào độ sai lệch giữa dự đoán và label thật.
loss = loss_fn(pred_y, y)
# Phải cố tình cho gradient về 0, nếu không gradient sẽ tích trữ và học sai
optimizer.zero_grad()
# Back propagation: model tìm gradient để sửa lỗi
loss.backward()
# Sửa lại lỗi bằng cách update lại weight với gradient
optimizer.step()
# Ta sử dụng argmax để lấy index của chữ cái nào có xác xuất lớn nhất trong 10 chữ cái
processed_pred_y = torch.argmax(pred_y, dim=1)
correct += (processed_pred_y == y).float().sum()
total_loss += loss
# Tính độ chính xác của dự đoán so với label thực tế
accuracy = 100 * correct / len(train_dataset)
# In loss và độ chính xác cho mỗi epoch
print(f"Epoch: {epoch}, loss: {total_loss}, accuracy: {accuracy:.2f}%")
Kết quả chạy sẽ như sau:
Epoch: 1, loss: 1.6462129354476929, accuracy: 79.98%
Epoch: 2, loss: 1.5302973985671997, accuracy: 88.53%
Epoch: 3, loss: 1.4613463878631592, accuracy: 89.76%
Epoch: 4, loss: 1.5596038103103638, accuracy: 92.26%
Epoch: 5, loss: 1.5865377187728882, accuracy: 93.35%
Epoch: 6, loss: 1.465031385421753, accuracy: 95.10%
Khi sử dụng dropout đôi khi loss của model sẽ tăng bất thường, tuy nhiên về lâu dài thì loss sẽ giảm và độ chính xác tăng.
Phân loại ảnh bằng CNN
Bây giờ ta thử model dự đoán với data test chưa được nhìn thấy:
def test(dataloader, model):
correct_preds = 0
total = 0
for batch_index, (X, y) in enumerate(dataloader):
# Chuyển dữ liệu ảnh và label đến GPU hoặc CPU
X = X.to(device)
y = y.to(device)
# Cho model dự đoán
predictions = model(X)
processed_preds = torch.argmax(predictions, dim=1)
correct_preds += torch.sum(processed_preds==y).item()
total += X.shape[0]
accuracy = correct_preds/total
print(f"{accuracy*100:.5f}%")
Nếu chạy với data test sẽ cho độ chính xác sau.
test(test_dataloader, cnn)
# 89.79000%
Kết luận
Trong bài viết này, chúng ta đã tạo model CNN bằng Pytorch, và đạt được độ chính xác trên dữ liệu test là 90%. Độ chính xác của dữ liệu train là 95%, hơn dataset test là 5%. Chứng tỏ model vẫn đang bị overfit.
Để tăng độ chính xác và giảm overfit số cách các bạn có thể thử các phương án đơn giản sau và train lại model.
- Tăng
weight_decay. Giá trị này tương ứng với L2 regularization. Regularization cao thì overfit giảm - Tăng xác xuất ở
torch.nn.Dropout2dvàtorch.nn.Dropout






